Chapter 7 - While You Are Coding
Conventional wisdom says that once a project is in the coding phase, the work is mostly mechanical, transcribing the design into executable statements. We think that this attitude is the single biggest reason that software projects fail, and many systems end up ugly, inefficient, poorly structured, unmaintainable, or just plain wrong.
Coding is not mechanical. If it were, all the CASE tools that people pinned their hopes on way back in the early 1980s would have replaced programmers long ago. There are decisions to be made every minute—decisions that require careful thought and judgment if the resulting program is to enjoy a long, accurate, and productive life.
Not all decisions are even conscious. You can better harness your instincts and nonconscious thoughts when you Topic 37, Listen to Your Lizard Brain. We'll see how to listen more carefully and look at ways of actively responding to these sometimes niggling thoughts.
But listening to your instincts doesn't mean you can just fly on autopilot. Developers who don't actively think about their code are programming by coincidence—the code might work, but there's no particular reason why. In Topic 38, Programming by Coincidence, we advocate a more positive involvement with the coding process.
While most of the code we write executes quickly, we occasionally develop algorithms that have the potential to bog down even the fastest processors. In Topic 39, Algorithm Speed, we discuss ways to estimate the speed of code, and we give some tips on how to spot potential problems before they happen.
Pragmatic Programmers think critically about all code, including our own. We constantly see room for improvement in our programs and our designs. In Topic 40, Refactoring, we look at techniques that help us fix up existing code continuously as we go.
Testing is not about finding bugs, it's about getting feedback on your code: aspects of design, the API, coupling, and so on. That means that the major benefits of testing happen when you think about and write the tests, not just when you run them. We'll explore this idea in Topic 41, Test to Code.
But of course when you test your own code, you might bring your own biases to the task. In Topic 42, Property-Based Testing we'll see how to have the computer do some wide-ranging testing for you and how to handle the inevitable bugs that come up.
It's critical that you write code that is readable and easy to reason about. It's a harsh world out there, filled with bad actors who are actively trying to break into your system and cause harm. We'll discuss some very basic techniques and approaches to help you Topic 43, Stay Safe Out There.
Finally, one of the hardest things in software development is Topic 44, Naming Things. We have to name a lot of things, and in many ways the names we choose define the reality we create. You need to stay aware of any potential semantic drift while you are coding.
Most of us can drive a car largely on autopilot; we don't explicitly command our foot to press a pedal, or our arm to turn the wheel—we just think “slow down and turn right.” However, good, safe drivers are constantly reviewing the situation, checking for potential problems, and putting themselves into good positions in case the unexpected happens. The same is true of coding—it may be largely routine, but keeping your wits about you could well prevent a disaster.
Topic 37. Listen to Your Lizard Brain
Only human beings can look directly at something, have all the information they need to make an accurate prediction, perhaps even momentarily make the accurate prediction, and then say that it isn't so.
Gavin de Becker, The Gift of Fear
Gavin de Becker's life's work is helping people to protect themselves. His book, The Gift of Fear: And Other Survival Signals That Protect Us from Violence [de 98], encapsulates his message. One of the key themes running through the book is that as sophisticated humans we have learned to ignore our more animal side; our instincts, our lizard brain. He claims that most people who are attacked in the street are aware of feeling uncomfortable or nervous before the attack. These people just tell themselves they're being silly. Then the figure emerges from the dark doorway….
Instincts are simply a response to patterns packed into our nonconscious brain. Some are innate, others are learned through repetition. As you gain experience as a programmer, your brain is laying down layers of tacit knowledge: things that work, things that don't work, the probable causes of a type of error, all the things you notice throughout your days. This is the part of your brain that hits the save file key when you stop to chat with someone, even when you don't realize that you're doing it.
Whatever their source, instincts share one thing: they have no words. Instincts make you feel, not think. And so when an instinct is triggered, you don't see a flashing lightbulb with a banner wrapped around it. Instead, you get nervous, or queasy, or feel like this is just too much work.
The trick is first to notice it is happening, and then to work out why. Let's look first at a couple of common situations in which your inner lizard is trying to tell you something. Then we'll discuss how you can let that instinctive brain out of its protective wrapper.
Fear of the Blank Page
Everyone fears the empty screen, the lonely blinking cursor surrounded by a whole bunch of nothing. Starting a new project (or even a new module in an existing project) can be an unnerving experience. Many of us would prefer to put off making the initial commitment of starting.
We think that there are two problems that cause this, and that both have the same solution.
One problem is that your lizard brain is trying to tell you something; there's some kind of doubt lurking just below the surface of perception. And that's important.
As a developer, you've been trying things and seeing which worked and which didn't. You've been accumulating experience and wisdom. When you feel a nagging doubt, or experience some reluctance when faced with a task, it might be that experience trying to speak to you. Heed it. You may not be able to put your finger on exactly what's wrong, but give it time and your doubts will probably crystallize into something more solid, something you can address. Let your instincts contribute to your performance.
The other problem is a little more prosaic: you might simply be afraid that you'll make a mistake.
And that's a reasonable fear. We developers put a lot of ourselves into our code; we can take errors in that code as reflections on our competence. Perhaps there's an element of imposter syndrome, too; we may think that this project is beyond us. We can't see our way through to the end; we'll get so far and then be forced to admit that we're lost.
Fighting Yourself
Sometimes code just flies from your brain into the editor: ideas become bits with seemingly no effort.
Other days, coding feels like walking uphill in mud. Taking each step requires tremendous effort, and every three steps you slide back two.
But, being a professional, you soldier on, taking step after muddy step: you have a job to do. Unfortunately, that's probably the exact opposite of what you should do.
Your code is trying to tell you something. It's saying that this is harder than it should be. Maybe the structure or design is wrong, maybe you're solving the wrong problem, or maybe you're just creating an ant farm's worth of bugs. Whatever the reason, your lizard brain is sensing feedback from the code, and it's desperately trying to get you to listen.
How to Talk Lizard
We talk a lot about listening to your instincts, to your nonconscious, lizard brain. The techniques are always the same.
Tip 61: Listen to Your Inner Lizard
First, stop what you're doing. Give yourself a little time and space to let your brain organize itself. Stop thinking about the code, and do something that is fairly mindless for a while, away from a keyboard. Take a walk, have lunch, chat with someone. Maybe sleep on it. Let the ideas percolate up through the layers of your brain on their own: you can't force it. Eventually they may bubble up to the conscious level, and you have one of those a ha! moments.
If that's not working, try externalizing the issue. Make doodles about the code you're writing, or explain it to a coworker (preferably one who isn't a programmer), or to your rubber duck. Expose different parts of your brain to the issue, and see if any of them have a better handle on the thing that's troubling you. We've lost track of the number of conversations we've had where one of us was explaining a problem to the other and suddenly went “Oh! Of course!” and broke off to fix it.
But maybe you've tried these things, and you're still stuck. It's time for action. We need to tell your brain that what you're about to do doesn't matter. And we do that by prototyping.
It's Playtime!
Andy and Dave have both spent hours looking at empty editor buffers. We'll type in some code, then look at the ceiling, then get yet another drink, then type in some more code, then go read a funny story about a cat with two tails, then type some more code, then do select-all/delete and start again. And again. And again.
And over the years we've found a brain hack that seems to work. Tell yourself you need to prototype something. If you're facing a blank screen, then look for some aspect of the project that you want to explore. Maybe you're using a new framework, and want to see how it does data binding. Or maybe it's a new algorithm, and you want to explore how it works on edge cases. Or maybe you want to try a couple of different styles of user interaction.
If you're working on existing code and it's pushing back, then stash it away somewhere and prototype up something similar instead.
Do the following.
-
Write “I'm prototyping” on a sticky note, and stick it on the side of your screen.
-
Remind yourself that prototypes are meant to fail. And remind yourself that prototypes get thrown away, even if they don't fail. There is no downside to doing this.
-
In your empty editor buffer, create a comment describing in one sentence what you want to learn or do.
-
Start coding.
If you start to have doubts, look at the sticky note.
If, in the middle of coding, that nagging doubt suddenly crystallizes into a solid concern, then address it.
If you get to the end of the experiment and you still feel uneasy, start again with the walk and the talk and the time off.
But, in our experience, at some point during the first prototype you will be surprised to find yourself humming along with your music, enjoying the feeling of creating code. The nervousness will have evaporated, replaced by a feeling of urgency: let's get this done!
At this stage, you know what to do. Delete all the prototype code, throw away the sticky note, and fill that empty editor buffer with bright, shiny new code.
Not Just Your Code
A large part of our job is dealing with existing code, often written by other people. Those people will have different instincts to you, and so the decisions they made will be different. Not necessarily worse; just different.
You can read their code mechanically, slogging through it making notes on stuff that seems important. It's a chore, but it works.
Or you can try an experiment. When you spot things done in a way that seems strange, jot it down. Continue doing this, and look for patterns. If you can see what drove them to write code that way, you may find that the job of understanding it becomes a lot easier. You'll be able consciously to apply the patterns that they applied tacitly.
And you might just learn something new along the way.
Not Just Code
Learning to listen to your gut when coding is an important skill to foster. But it applies to the bigger picture are well. Sometimes a design just feels wrong, or some requirement makes you feel uneasy. Stop and analyze these feelings. If you're in a supportive environment, express them out loud. Explore them. The chances are that there's something lurking in that dark doorway. Listen to your instincts and avoid the problem before it jumps out at you.
Related Sections Include
- Topic 13, Prototypes and Post-it Notes
- Topic 22, Engineering Daybooks
- Topic 46, Solving Impossible Puzzles
Challenges
- Is there something you know you should do, but have put off because it feels a little scary, or difficult? Apply the techniques in this section. Time box it to an hour, maybe two, and promise yourself that when the bell rings you'll delete what you did. What did you learn?
Topic 38. Programming by Coincidence
Do you ever watch old black-and-white war movies? The weary soldier advances cautiously out of the brush. There's a clearing ahead: are there any land mines, or is it safe to cross? There aren't any indications that it's a minefield—no signs, barbed wire, or craters. The soldier pokes the ground ahead of him with his bayonet and winces, expecting an explosion. There isn't one. So he proceeds painstakingly through the field for a while, prodding and poking as he goes. Eventually, convinced that the field is safe, he straightens up and marches proudly forward, only to be blown to pieces.
The soldier's initial probes for mines revealed nothing, but this was merely lucky. He was led to a false conclusion—with disastrous results.
As developers, we also work in minefields. There are hundreds of traps waiting to catch us each day. Remembering the soldier's tale, we should be wary of drawing false conclusions. We should avoid programming by coincidence—relying on luck and accidental successes—in favor of programming deliberately.
How to Program by Coincidence
Suppose Fred is given a programming assignment. Fred types in some code, tries it, and it seems to work. Fred types in some more code, tries it, and it still seems to work. After several weeks of coding this way, the program suddenly stops working, and after hours of trying to fix it, he still doesn't know why. Fred may well spend a significant amount of time chasing this piece of code around without ever being able to fix it. No matter what he does, it just doesn't ever seem to work right.
Fred doesn't know why the code is failing because he didn't know why it worked in the first place. It seemed to work, given the limited “testing'' that Fred did, but that was just a coincidence. Buoyed by false confidence, Fred charged ahead into oblivion. Now, most intelligent people may know someone like Fred, but we know better. We don't rely on coincidences—do we?
Sometimes we might. Sometimes it can be pretty easy to confuse a happy coincidence with a purposeful plan. Let's look at a few examples.
Accidents of Implementation
Accidents of implementation are things that happen simply because that's the way the code is currently written. You end up relying on undocumented error or boundary conditions.
Suppose you call a routine with bad data. The routine responds in a particular way, and you code based on that response. But the author didn't intend for the routine to work that way—it was never even considered. When the routine gets “fixed,'' your code may break. In the most extreme case, the routine you called may not even be designed to do what you want, but it seems to work okay. Calling things in the wrong order, or in the wrong context, is a related problem.
Here it looks like Fred is desperately trying to get something out on the screen using some particular GUI rendering framework:
paint(); invalidate(); validate(); revalidate(); repaint(); paintImmediately();
But these routines were never designed to be called this way; although they seem to work, that's really just a coincidence.
To add insult to injury, when the scene finally does get drawn, Fred won't try to go back and take out the spurious calls. “It works now, better leave well enough alone….”
It's easy to be fooled by this line of thought. Why should you take the risk of messing with something that's working? Well, we can think of several reasons:
-
It may not really be working—it might just look like it is.
-
The boundary condition you rely on may be just an accident. In different circumstances (a different screen resolution, more CPU cores), it might behave differently.
-
Undocumented behavior may change with the next release of the library.
-
Additional and unnecessary calls make your code slower.
-
Additional calls increase the risk of introducing new bugs of their own.
For code you write that others will call, the basic principles of good modularization and of hiding implementation behind small, well-documented interfaces can all help. A well-specified contract (see Topic 23, Design by Contract) can help eliminate misunderstandings.
For routines you call, rely only on documented behavior. If you can't, for whatever reason, then document your assumption well.
Close Enough Isn't
We once worked on a large project that reported on data fed from a very large number of hardware data collection units out in the field. These units spanned states and time zones, and for various logistical and historical reasons, each unit was set to local time.[50] As a result of conflicting time zone interpretations and inconsistencies in Daylight Savings Time policies, results were almost always wrong, but only off by one. The developers on the project had gotten into the habit of just adding one or subtracting one to get the correct answer, reasoning that it was only off by one in this one situation. And then the next function would see the value as off by the one the other way, and change it back.
But the fact that it was “only” off by one some of the time was a coincidence, masking a deeper and more fundamental flaw. Without a proper model of time handling, the entire large code base had devolved over time to an untenable mass of +1 and -1 statements. Ultimately, none of it was correct and the project was scrapped.
Phantom Patterns
Human beings are designed to see patterns and causes, even when it's just a coincidence. For example, Russian leaders always alternate between being bald and hairy: a bald (or obviously balding) state leader of Russia has succeeded a non-bald (“hairy”) one, and vice versa, for nearly 200 years.[51]
But while you wouldn't write code that depended on the next Russian leader being bald or hairy, in some domains we think that way all the time. Gamblers imagine patterns in lottery numbers, dice games, or roulette, when in fact these are statistically independent events. In finance, stock and bond trading are similarly rife with coincidence instead of actual, discernible patterns.
A log file that shows an intermittent error every 1,000 requests may be a difficult-to-diagnose race condition, or may be a plain old bug. Tests that seem to pass on your machine but not on the server might indicate a difference between the two environments, or maybe it's just a coincidence.
Don't assume it, prove it.
Accidents of Context
You can have “accidents of context” as well. Suppose you are writing a utility module. Just because you are currently coding for a GUI environment, does the module have to rely on a GUI being present? Are you relying on English-speaking users? Literate users? What else are you relying on that isn't guaranteed?
Are you relying on the current directory being writable? On certain environment variables or configuration files being present? On the time on the server being accurate—within what tolerance? Are you relying on network availability and speed?
When you copied code from the first answer you found on the net, are you sure your context is the same? Or are you building “cargo cult” code, merely imitating form without content?[52]
Finding an answer that happens to fit is not the same as the right answer.
Tip 62: Don't Program by Coincidence
Implicit Assumptions
Coincidences can mislead at all levels—from generating requirements through to testing. Testing is particularly fraught with false causalities and coincidental outcomes. It's easy to assume that X causes Y, but as we said in Topic 20, Debugging: don't assume it, prove it.
At all levels, people operate with many assumptions in mind—but these assumptions are rarely documented and are often in conflict between different developers. Assumptions that aren't based on well-established facts are the bane of all projects.
How to Program Deliberately
We want to spend less time churning out code, catch and fix errors as early in the development cycle as possible, and create fewer errors to begin with. It helps if we can program deliberately:
-
Always be aware of what you are doing. Fred let things get slowly out of hand, until he ended up boiled, like the frog here.
-
Can you explain the code, in detail, to a more junior programmer? If not, perhaps you are relying on coincidences.
-
Don't code in the dark. Build an application you don't fully grasp, or use a technology you don't understand, and you'll likely be bitten by coincidences. If you're not sure why it works, you won't know why it fails.
-
Proceed from a plan, whether that plan is in your head, on the back of a cocktail napkin, or on a whiteboard.
-
Rely only on reliable things. Don't depend on assumptions. If you can't tell if something is reliable, assume the worst.
-
Document your assumptions. Topic 23, Design by Contract, can help clarify your assumptions in your own mind, as well as help communicate them to others.
-
Don't just test your code, but test your assumptions as well. Don't guess; actually try it. Write an assertion to test your assumptions (see Topic 25, Assertive Programming). If your assertion is right, you have improved the documentation in your code. If you discover your assumption is wrong, then count yourself lucky.
-
Prioritize your effort. Spend time on the important aspects; more than likely, these are the hard parts. If you don't have fundamentals or infrastructure correct, brilliant bells and whistles will be irrelevant.
-
Don't be a slave to history. Don't let existing code dictate future code. All code can be replaced if it is no longer appropriate. Even within one program, don't let what you've already done constrain what you do next—be ready to refactor (see Topic 40, Refactoring). This decision may impact the project schedule. The assumption is that the impact will be less than the cost of not making the change.[53]
So next time something seems to work, but you don't know why, make sure it isn't just a coincidence.
Related Sections Include
- Topic 4, Stone Soup and Boiled Frogs
- Topic 9, DRY—The Evils of Duplication
- Topic 23, Design by Contract
- Topic 34, Shared State Is Incorrect State
- Topic 43, Stay Safe Out There
Exercises
Exercise 25 (possible answer)
A data feed from a vendor gives you an array of tuples representing key-value pairs. The key of DepositAccount will hold a string of the account number in the corresponding value:
[
...
{:DepositAccount, "564-904-143-00"}
...
]
It worked perfectly in test on the 4-core developer laptops and on the 12-core build machine, but on the production servers running in containers, you keep getting the wrong account numbers. What's going on?
Exercise 26 (possible answer)
You're coding an autodialer for voice alerts, and have to manage a database of contact information. The ITU specifies that phone numbers should be no longer than 15 digits, so you store the contact's phone number in a numeric field guaranteed to hold at least 15 digits. You've tested in thoroughly throughout North America and everything seems fine, but suddenly you're getting a rash of complaints from other parts of the world. Why?
Exercise 27 (possible answer)
You have written an app that scales up common recipes for a cruise ship dining room that seats 5,000. But you're getting complaints that the conversions aren't precise. You check, and the code uses the conversion formula of 16 cups to a gallon. That's right, isn't it?
Topic 39. Algorithm Speed
In Topic 15, Estimating, we talked about estimating things such as how long it takes to walk across town, or how long a project will take to finish. However, there is another kind of estimating that Pragmatic Programmers use almost daily: estimating the resources that algorithms use—time, processor, memory, and so on.
This kind of estimating is often crucial. Given a choice between two ways of doing something, which do you pick? You know how long your program runs with 1,000 records, but how will it scale to 1,000,000? What parts of the code need optimizing?
It turns out that these questions can often be answered using common sense, some analysis, and a way of writing approximations called the Big-O notation.
What Do We Mean by Estimating Algorithms?
Most nontrivial algorithms handle some kind of variable input—sorting $ n $ strings, inverting an $ m \times n $ matrix, or decrypting a message with an $ n $-bit key. Normally, the size of this input will affect the algorithm: the larger the input, the longer the running time or the more memory used.
If the relationship were always linear (so that the time increased in direct proportion to the value of $ n $), this section wouldn't be important. However, most significant algorithms are not linear. The good news is that many are sublinear. A binary search, for example, doesn't need to look at every candidate when finding a match. The bad news is that other algorithms are considerably worse than linear; runtimes or memory requirements increase far faster than $ n $. An algorithm that takes a minute to process ten items may take a lifetime to process 100.
We find that whenever we write anything containing loops or recursive calls, we subconsciously check the runtime and memory requirements. This is rarely a formal process, but rather a quick confirmation that what we're doing is sensible in the circumstances. However, we sometimes do find ourselves performing a more detailed analysis. That's when Big-O notation comes in handy.
Big-O Notation
The Big-O notation, written $ O() $, is a mathematical way of dealing with approximations. When we write that a particular sort routine sorts $ O() $ records in $ O(n^2) $ time, we are simply saying that the worst-case time taken will vary as the square of $ n $. Double the number of records, and the time will increase roughly fourfold. Think of the $ O $ as meaning on the order of.
The $ O() $ notation puts an upper bound on the value of the thing we're measuring (time, memory, and so on). If we say a function takes $ O(n^2) $ time, then we know that the upper bound of the time it takes will not grow faster than $ n^2 $. Sometimes we come up with fairly complex $ O() $ functions, but because the highest-order term will dominate the value as $ n $ increases, the convention is to remove all low-order terms, and not to bother showing any constant multiplying factors:
$$ O(\frac{n^2}{2} + 3n)\,is\,the\,same\,as\,O(\frac{n^2}{2})\,is\,the\,same\,as\,O(n^2) $$
This is actually a feature of the $ O() $ notation—one $ O(n^2) $ algorithm may be 1,000 times faster than another $ O(n^2) $ algorithm, but you won't know it from the notation. Big-O is never going to give you actual numbers for time or memory or whatever: it simply tells you how these values will change as the input changes.
Figure 3, Runtimes of various algorithms shows several common $ O() $ notations you'll come across, along with a graph comparing running times of algorithms in each category. Clearly, things quickly start getting out of hand once we get over $ O(n^2) $.
For example, suppose you've got a routine that takes one second to process 100 records. How long will it take to process 1,000? If your code is $ O(1) $, then it will still take one second. If it's $ O(\lg{n})$, then you'll probably be waiting about three seconds. $ O(n) $ will show a linear increase to ten seconds, while an $ O(n\,lg{n}) $ will take some 33 seconds. If you're unlucky enough to have an $ O(n^2) $ routine, then sit back for 100 seconds while it does its stuff. And if you're using an exponential algorithm $ O(2^n) $, you might want to make a cup of coffee—your routine should finish in about $ 10^263 $ years. Let us know how the universe ends.
The $O()$ notation doesn't apply just to time; you can use it to represent any other resources used by an algorithm. For example, it is often useful to be able to model memory consumption (see the exercises for an example).
$O(1)$ | Constant (access element in array, simple statements) |
$O(\lg{n})$ |
Logarithmic (binary search). The base of the logarithm doesn't matter, so this is equivalent $O(\log{n})$. |
$O(n)$ | Linear (sequential search) |
$O(n\,\lg{n})$ | Worse than linear, but not much worse. (Average runtime of quicksort, heapsort) |
$O(n^2)$ | Square law (selection and insertion sorts) |
$O(n^3)$ |
Cubic (multiplication of two $n \times n$ matrices) |
$O(C^n)$ | Exponential (traveling salesman problem, set partitioning) |
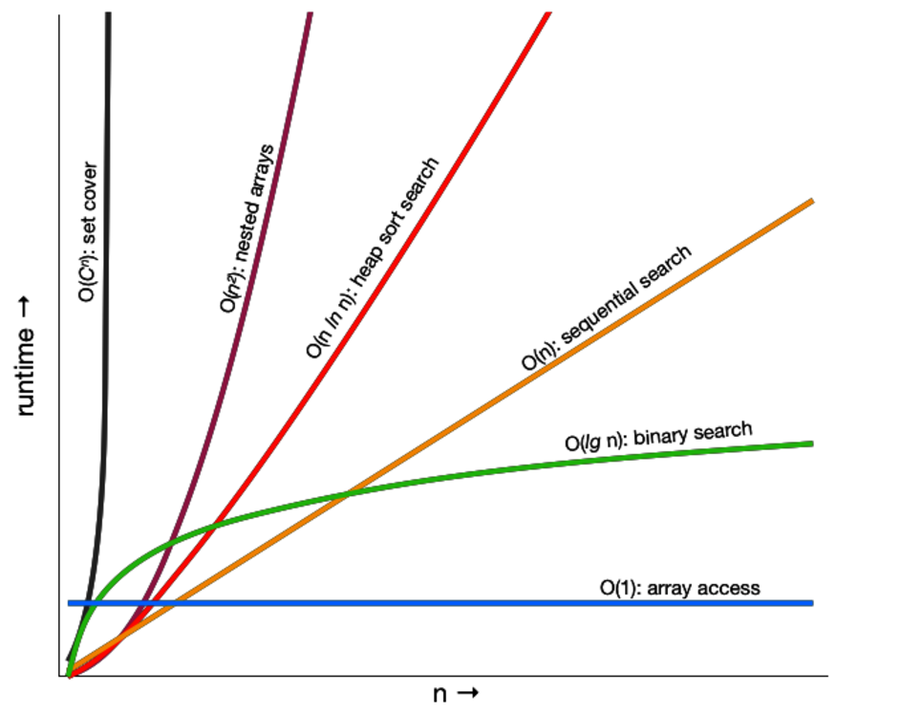
Figure 3. Runtimes of various algorithms
Common Sense Estimation
You can estimate the order of many basic algorithms using common sense.
- Simple loops
-
If a simple loop runs from $1$ to $n$, then the algorithm is likely to be $O(n)$—time increases linearly with $n$. Examples include exhaustive searches, finding the maximum value in an array, and generating checksums.
- Nested loops
-
If you nest a loop inside another, then your algorithm becomes $O(m\times n)$, where $m$ and $n$ are the two loops' limits. This commonly occurs in simple sorting algorithms, such as bubble sort, where the outer loop scans each element in the array in turn, and the inner loop works out where to place that element in the sorted result. Such sorting algorithms tend to be $O(n^2)$.
- Binary chop
-
If your algorithm halves the set of things it considers each time around the loop, then it is likely to be logarithmic, $O(\lg{n})$. A binary search of a sorted list, traversing a binary tree, and finding the first set bit in a machine word can all be $O(\lg{n})$.
- Divide and conquer
-
Algorithms that partition their input work on the two halves independently, and then combine the result can be $O(n\,\lg{n})$. The classic example is quicksort, which works by partitioning the data into two halves and recursively sorting each. Although technically $O(n^2)$, because its behavior degrades when it is fed sorted input, the average runtime of quicksort is $O(n\,\lg{n})$.
- Combinatoric
-
Whenever algorithms start looking at the permutations of things, their running times may get out of hand. This is because permutations involve factorials (there are $5! = 5\times 4 \times 3 \times 2 \times 1 = 120$ permutations of the digits from 1 to 5). Time a combinatoric algorithm for five elements: it will take six times longer to run it for six, and 42 times longer for seven. Examples include algorithms for many of the acknowledged hard problems—the traveling salesman problem, optimally packing things into a container, partitioning a set of numbers so that each set has the same total, and so on. Often, heuristics are used to reduce the running times of these types of algorithms in particular problem domains.
Algorithm Speed in Practice
It's unlikely that you'll spend much time during your career writing sort routines. The ones in the libraries available to you will probably outperform anything you may write without substantial effort. However, the basic kinds of algorithms we've described earlier pop up time and time again. Whenever you find yourself writing a simple loop, you know that you have an $O(n)$ algorithm. If that loop contains an inner loop, then you're looking at $O(m \times n)$. You should be asking yourself how large these values can get. If the numbers are bounded, then you'll know how long the code will take to run. If the numbers depend on external factors (such as the number of records in an overnight batch run, or the number of names in a list of people), then you might want to stop and consider the effect that large values may have on your running time or memory consumption.
Tip 63: Estimate the Order of Your Algorithms
There are some approaches you can take to address potential problems. If you have an algorithm that is $O(n^2)$, try to find a divide-and-conquer approach that will take you down to $O(n\lg{n})$.
If you're not sure how long your code will take, or how much memory it will use, try running it, varying the input record count or whatever is likely to impact the runtime. Then plot the results. You should soon get a good idea of the shape of the curve. Is it curving upward, a straight line, or flattening off as the input size increases? Three or four points should give you an idea.
Also consider just what you're doing in the code itself. A simple $O(n^2)$ loop may well perform better than a complex, $O(n\lg{n})$ one for smaller values of $n$, particularly if the $O(n\lg{n})$ algorithm has an expensive inner loop.
In the middle of all this theory, don't forget that there are practical considerations as well. Runtime may look like it increases linearly for small input sets. But feed the code millions of records and suddenly the time degrades as the system starts to thrash. If you test a sort routine with random input keys, you may be surprised the first time it encounters ordered input. Try to cover both the theoretical and practical bases. After all this estimating, the only timing that counts is the speed of your code, running in the production environment, with real data. This leads to our next tip.
Tip 64: Test Your Estimates
If it's tricky getting accurate timings, use code profilers to count the number of times the different steps in your algorithm get executed, and plot these figures against the size of the input.
Best Isn't Always Best
You also need to be pragmatic about choosing appropriate algorithms—the fastest one is not always the best for the job. Given a small input set, a straightforward insertion sort will perform just as well as a quicksort, and will take you less time to write and debug. You also need to be careful if the algorithm you choose has a high setup cost. For small input sets, this setup may dwarf the running time and make the algorithm inappropriate.
Also be wary of premature optimization. It's always a good idea to make sure an algorithm really is a bottleneck before investing your precious time trying to improve it.
Related Sections Include
- Topic 15, Estimating
Challenges
-
Every developer should have a feel for how algorithms are designed and analyzed. Robert Sedgewick has written a series of accessible books on the subject (Algorithms [SW11]An Introduction to the Analysis of Algorithms [SF13] and others). We recommend adding one of his books to your collection, and making a point of reading it.
-
For those who like more detail than Sedgewick provides, read Donald Knuth's definitive Art of Computer Programming books, which analyze a wide range of algorithms.
- The Art of Computer Programming, Volume 1: Fundamental Algorithms [Knu98]
- The Art of Computer Programming, Volume 2: Seminumerical Algorithms [Knu98a]
- The Art of Computer Programming, Volume 3: Sorting and Searching [Knu98b]
- The Art of Computer Programming, Volume 4A: Combinatorial Algorithms, Part 1 [Knu11].
-
In the first exercise that follows we look at sorting arrays of long integers. What is the impact if the keys are more complex, and the overhead of key comparison is high? Does the key structure affect the efficiency of the sort algorithms, or is the fastest sort always fastest?
Exercises
Exercise 28 (possible answer)
We coded a set of simple sort routines[54] in Rust. Run them on various machines available to you. Do your figures follow the expected curves? What can you deduce about the relative speeds of your machines? What are the effects of various compiler optimization settings?
Exercise 29 (possible answer)
In Common Sense Estimation, we claimed that a binary chop is $O(\lg{n})$. Can you prove this?
Exercise 30 (possible answer)
In Figure 3, Runtimes of various algorithms, we claimed that $O(\lg{n})$ is the same as $O(\log_10{n})$ (or indeed logarithms to any base). Can you explain why?
Topic 40. Refactoring
Change and decay in all around I see...
H. F. Lyte, Abide With Me
As a program evolves, it will become necessary to rethink earlier decisions and rework portions of the code. This process is perfectly natural. Code needs to evolve; it's not a static thing.
Unfortunately, the most common metaphor for software development is building construction. Bertrand Meyer's classic work Object-Oriented Software Construction [Mey97] uses the term “Software Construction,” and even your humble authors edited the Software Construction column for IEEE Software in the early 2000s.[55]
But using construction as the guiding metaphor implies the following steps:
-
An architect draws up blueprints.
-
Contractors dig the foundation, build the superstructure, wire and plumb, and apply finishing touches.
-
The tenants move in and live happily ever after, calling building maintenance to fix any problems.
Well, software doesn't quite work that way. Rather than construction, software is more like gardening—it is more organic than concrete. You plant many things in a garden according to an initial plan and conditions. Some thrive, others are destined to end up as compost. You may move plantings relative to each other to take advantage of the interplay of light and shadow, wind and rain. Overgrown plants get split or pruned, and colors that clash may get moved to more aesthetically pleasing locations. You pull weeds, and you fertilize plantings that are in need of some extra help. You constantly monitor the health of the garden, and make adjustments (to the soil, the plants, the layout) as needed.
Business people are comfortable with the metaphor of building construction: it is more scientific than gardening, it's repeatable, there's a rigid reporting hierarchy for management, and so on. But we're not building skyscrapers—we aren't as constrained by the boundaries of physics and the real world.
The gardening metaphor is much closer to the realities of software development. Perhaps a certain routine has grown too large, or is trying to accomplish too much—it needs to be split into two. Things that don't work out as planned need to be weeded or pruned.
Rewriting, reworking, and re-architecting code is collectively known as restructuring. But there's a subset of that activity that has become practiced as refactoring.
Refactoring [Fow19] is defined by Martin Fowler as a:
disciplined technique for restructuring an existing body of code, altering its internal structure without changing its external behavior.
The critical parts of this definition are that:
-
The activity is disciplined, not a free-for-all
-
External behavior does not change; this is not the time to add features
Refactoring is not intended to be a special, high-ceremony, once-in-a-while activity, like plowing under the whole garden in order to replant. Instead, refactoring is a day-to-day activity, taking low-risk small steps, more like weeding and raking. Instead of a free-for-all, wholesale rewrite of the codebase, it's a targeted, precision approach to help keep the code easy to change.
In order to guarantee that the external behavior hasn't changed, you need good, automated unit testing that validates the behavior of the code.
When Should You Refactor?
You refactor when you've learned something; when you understand something better than you did last year, yesterday, or even just ten minutes ago.
Perhaps you've come across a stumbling block because the code doesn't quite fit anymore, or you notice two things that should really be merged, or anything else at all strikes you as being “wrong,” don't hesitate to change it. There's no time like the present. Any number of things may cause code to qualify for refactoring:
- Duplication
-
You've discovered a violation of the DRY principle.
- Nonorthogonal design
-
You've discovered something that could be made more orthogonal.
- Outdated knowledge
-
Things change, requirements drift, and your knowledge of the problem increases. Code needs to keep up.
- Usage
-
As the system gets used by real people under real circumstances, you realize some features are now more important than previously thought, and “must have” features perhaps weren't.
- Performance
-
You need to move functionality from one area of the system to another to improve performance.
- The Tests Pass
-
Yes. Seriously. We did say that refactoring should be a small scale activity, backed up by good tests. So when you've added a small amount of code, and that one extra test passes, you now have a great opportunity to dive in and tidy up what you just wrote.
Refactoring your code—moving functionality around and updating earlier decisions—is really an exercise in pain management. Let's face it, changing source code around can be pretty painful: it was working, maybe it's better to leave well enough alone. Many developers are reluctant to go in and re-open a piece of code just because it isn't quite right.
Real-World Complications
So you go to your teammates or client and say, “This code works, but I need another week to completely refactor it.”
We can't print their reply.
Time pressure is often used as an excuse for not refactoring. But this excuse just doesn't hold up: fail to refactor now, and there'll be a far greater time investment to fix the problem down the road—when there are more dependencies to reckon with. Will there be more time available then? Nope.
You might want to explain this principle to others by using a medical analogy: think of the code that needs refactoring as “a growth.” Removing it requires invasive surgery. You can go in now, and take it out while it is still small. Or, you could wait while it grows and spreads—but removing it then will be both more expensive and more dangerous. Wait even longer, and you may lose the patient entirely.
Tip 65: Refactor Early, Refactor Often
Collateral damage in code can be just as deadly over time (see Topic 3, Software Entropy). Refactoring, as with most things, is easier to do while the issues are small, as an ongoing activity while coding. You shouldn't need “a week to refactor” a piece of code—that's a full-on rewrite. If that level of disruption is necessary, then you might well not be able to do it immediately. Instead, make sure that it gets placed on the schedule. Make sure that users of the affected code know that it is scheduled to be rewritten and how this might affect them.
How Do You Refactor?
Refactoring started out in the Smalltalk community, and had just started to gain a wider audience when we wrote the first edition of this book, probably thanks to the first major book on refactoring (Refactoring: Improving the Design of Existing Code [Fow19], now in its second edition).
At its heart, refactoring is redesign. Anything that you or others on your team designed can be redesigned in light of new facts, deeper understandings, changing requirements, and so on. But if you proceed to rip up vast quantities of code with wild abandon, you may find yourself in a worse position than when you started.
Clearly, refactoring is an activity that needs to be undertaken slowly, deliberately, and carefully. Martin Fowler offers the following simple tips on how to refactor without doing more harm than good:[56]
-
Don't try to refactor and add functionality at the same time.
-
Make sure you have good tests before you begin refactoring. Run the tests as often as possible. That way you will know quickly if your changes have broken anything.
-
Take short, deliberate steps: move a field from one class to another, split a method, rename a variable. Refactoring often involves making many localized changes that result in a larger-scale change. If you keep your steps small, and test after each step, you will avoid prolonged debugging.[57]
We'll talk more about testing at this level in Topic 41, Test to Code, and larger-scale testing in Ruthless and Continuous Testing, but Mr. Fowler's point of maintaining good regression tests is the key to refactoring safely.
If you have to go beyond refactoring and end up changing external behavior or interfaces, then it can help to deliberately break the build: old clients of this code should fail to compile. That way you'll know what needs updating. Next time you see a piece of code that isn't quite as it should be, fix it. Manage the pain: if it hurts now, but is going to hurt even more later, you might as well get it over with. Remember the lessons of Topic 3, Software Entropy: don't live with broken windows.
Related Sections Include
- Topic 3, Software Entropy
- Topic 9, DRY—The Evils of Duplication
- Topic 12, Tracer Bullets
- Topic 27, Don't Outrun Your Headlights
- Topic 44, Naming Things
- Topic 48, The Essence of Agility
Topic 41. Test to Code
The first edition of this book was written in more primitive times, when most developers wrote no tests—why bother, they thought, the world was going to end in the year 2000 anyway.
In that book, we had a section on how to build code that was easy to test. It was a sneaky way of convincing developers to actually write tests.
These are more enlightened times. If there are any developers still not writing tests, they at least know that they should be.
But there's still a problem. When we ask developers why they write tests, they look at us as if we just asked if they still coded using punched cards and they'd say “to make sure the code works,” with an unspoken “you dummy” at the end. And we think that's wrong.
So what do we think is important about testing? And how do we think you should go about it?
Let's start with the bold statement:
Tip 66: Testing Is Not About Finding Bugs
We believe that the major benefits of testing happen when you think about and write the tests, not when you run them.
Thinking About Tests
It's a Monday morning and you settle in to start work on some new code. You have to write something that queries the database to return a list of people who watch more than 10 videos a week on your “world's funniest dishwashing videos” site.
You fire up your editor, and start by writing the function that performs the query:
def return_avid_viewers do # ... hmmm ... end
Stop! How do you know that what you're about to do is a good thing?
The answer is that you can't know that. No one can. But thinking about tests can make it more likely. Here's how that works.
Start by imagining that you'd finished writing the function and now had to test it. How would you do that? Well, you'd want to use some test data, which probably means you want to work in a database you control. Now some frameworks can handle that for you, running tests against a test database, but in our case that means we should be passing the database instance into our function rather than using some global one, as that allows us to change it while testing:
def return_avid_users(db) do
Then we have to think about how we'd populate that test data. The requirement asks for a “list of people who watch more than 10 videos a week.” So we look at the database schema for fields that might help. We find two likely fields in a table of who-watched-what: opened_video and completed_video. To write our test data, we need to know which field to use. But we don't know what the requirement means, and our business contact is out. Let's just cheat and pass in the name of the field (which will allow us to test what we have, and potentially change it later):
def return_avid_users(db, qualifying_field_name) do
We started by thinking about our tests, and without writing a line of code, we've already made two discoveries and used them to change the API of our method.
Tests Drive Coding
In the previous example, thinking about testing made us reduce coupling in our code (by passing in a database connection rather than using a global one) and increase flexibility (by making the name of the field we test a parameter). Thinking about writing a test for our method made us look at it from the outside, as if we were a client of the code, and not its author.
Tip 67: A Test Is the First User of Your Code
We think this is probably the biggest benefit offered by testing: testing is vital feedback that guides your coding.
A function or method that is tightly coupled to other code is hard to test, because you have to set up all that environment before you can even run your method. So making your stuff testable also reduces its coupling.
And before you can test something, you have to understand it. That sounds silly, but in reality we've all launched into a piece of code based on a nebulous understanding of what we had to do. We assure ourselves that we'll work it out as we go along. Oh, and we'll add all the code to support the boundary conditions later, too. Oh, and the error handling. And the code ends up five times longer than it should because it's full of conditional logic and special cases. But shine the light of a test on that code, and things become clearer. If you think about testing boundary conditions and how that will work before you start coding, you may well find the patterns in the logic that'll simplify the function. If you think about the error conditions you'll need to test, you'll structure your function accordingly.
Test-Driven Development
There's a school of programming that says that, given all the benefits of thinking about tests up front, why not go ahead and write them up front too? They practice something called test-driven development or TDD. You'll also see this called test-first development.[58]
The basic cycle of TDD is:
-
Decide on a small piece of functionality you want to add.
-
Write a test that will pass once that functionality is implemented.
-
Run all tests. Verify that the only failure is the one you just wrote.
-
Write the smallest amount of code needed to get the test to pass, and verify that the tests now run cleanly.
-
Refactor your code: see if there is a way to improve on what you just wrote (the test or the function). Make sure the tests still pass when you're done.
The idea is that this cycle should be very short: a matter of minutes, so that you're constantly writing tests and then getting them to work.
We see a major benefit in TDD for people just starting out with testing. If you follow the TDD workflow, you'll guarantee that you always have tests for your code. And that means you'll always be thinking about your tests.
However, we've also seen people become slaves to TDD. This manifests itself in a number of ways:
-
They spend inordinate amounts of time ensuring that they always have 100% test coverage.
-
They have lots of redundant tests. For example, before writing a class for the first time, many TDD adherents will first write a failing test that simply references the class's name. It fails, then they write an empty class definition and it passes. But now you have a test that does absolutely nothing; the next test you write will also reference the class, and so it makes the first unnecessary. There's more stuff to change if the class name changes later. And this is just a trivial example.
-
Their designs tend to start at the bottom and work their way up. (See Bottom-Up vs. Top-Down vs. The Way You Should Do It.)
By all means practice TDD. But, if you do, don't forget to stop every now and then and look at the big picture. It is easy to become seduced by the green "tests passed" message, writing lots of code that doesn't actually get you closer to a solution.
TDD: You Need to Know Where You're Going
The old joke asks “How do you eat an elephant?” The punchline: “One bite at a time.” And this idea is often touted as a benefit of TDD. When you can't comprehend the whole problem, take small steps, one test at a time. However, this approach can mislead you, encouraging you to focus on and endlessly polish the easy problems while ignoring the real reason you're coding. An interesting example of this happened in 2006, when Ron Jeffries, a leading figure in the agility movement, started a series of blog posts which documented his test-driven coding of a Sudoko solver.[59] After five posts, he'd refined the representation of the underlying board, refactoring a number of times until he was happy with the object model. But then he abandoned the project. It's interesting to read the blog posts in order, and watch how a clever person can get sidetracked by the minutia, reinforced by the glow of passing tests.
As a contrast, Peter Norvig describes an alternative approach[60] which feels very different in character: rather than being driven by tests, he starts with a basic understanding of how these kinds of problems are traditionally solved (using constraint propagation), and then focuses on refining his algorithm. He addresses board representation in a dozen lines of code that flow directly from his discussion of notation.
Tests can definitely help drive development. But, as with every drive, unless you have a destination in mind, you can end up going in circles.
Back to the Code
Component-based development has long been a lofty goal of software development.[61] The idea is that generic software components should be available and combined just as easily as common integrated circuits (ICs) are combined. But this works only if the components you are using are known to be reliable, and if you have common voltages, interconnect standards, timing, and so on.
Chips are designed to be tested—not just at the factory, not just when they are installed, but also in the field when they are deployed. More complex chips and systems may have a full Built-In Self Test (BIST) feature that runs some base-level diagnostics internally, or a Test Access Mechanism (TAM) that provides a test harness that allows the external environment to provide stimuli and collect responses from the chip.
We can do the same thing in software. Like our hardware colleagues, we need to build testability into the software from the very beginning, and test each piece thoroughly before trying to wire them together.
Unit Testing
Chip-level testing for hardware is roughly equivalent to unit testing in software—testing done on each module, in isolation, to verify its behavior. We can get a better feeling for how a module will react in the big wide world once we have tested it throughly under controlled (even contrived) conditions.
A software unit test is code that exercises a module. Typically, the unit test will establish some kind of artificial environment, then invoke routines in the module being tested. It then checks the results that are returned, either against known values or against the results from previous runs of the same test (regression testing).
Later, when we assemble our “software ICs” into a complete system, we'll have confidence that the individual parts work as expected, and then we can use the same unit test facilities to test the system as a whole. We talk about this large-scale checking of the system in Ruthless and Continuous Testing.
Before we get that far, however, we need to decide what to test at the unit level. Historically, programmers threw a few random bits of data at the code, looked at the print statements, and called it tested. We can do much better.
Testing Against Contract
We like to think of unit testing as testing against contract (see Topic 23, Design by Contract). We want to write test cases that ensure that a given unit honors its contract. This will tell us two things: whether the code meets the contract, and whether the contract means what we think it means. We want to test that the module delivers the functionality it promises, over a wide range of test cases and boundary conditions.
What does this mean in practice? Let's start with a simple, numerical example: a square root routine. Its documented contract is simple:
pre-conditions: argument >= 0; post-conditions: ((result * result) - argument).abs
This tells us what to test:
-
Pass in a negative argument and ensure that it is rejected.
-
Pass in an argument of zero to ensure that it is accepted (this is the boundary value).
-
Pass in values between zero and the maximum expressible argument and verify that the difference between the square of the result and the original argument is less than some small fraction of the argument (epsilon).
Armed with this contract, and assuming that our routine does its own pre- and postcondition checking, we can write a basic test script to exercise the square root function.
Then we can call this routine to test our square root function:
assertWithinEpsilon(my_sqrt(0), 0) assertWithinEpsilon(my_sqrt(2.0), 1.4142135624) assertWithinEpsilon(my_sqrt(64.0), 8.0) assertWithinEpsilon(my_sqrt(1.0e7), 3162.2776602) assertRaisesException fn => my_sqrt(-4.0) end
This is a pretty simple test; in the real world, any nontrivial module is likely to be dependent on a number of other modules, so how do we go about testing the combination?
Suppose we have a module A that uses a DataFeed and a LinearRegression. In order, we would test:
- DataFeed's contract, in full
- LinearRegression's contract, in full
- A's contract, which relies on the other contracts but does not directly expose them
This style of testing requires you to test subcomponents of a module first. Once the subcomponents have been verified, then the module itself can be tested.
If DataFeed and LinearRegression's tests passed, but A's test failed, we can be pretty sure that the problem is in A, or in A's use of one of those subcomponents. This technique is a great way to reduce debugging effort: we can quickly concentrate on the likely source of the problem within module A, and not waste time reexamining its subcomponents.
Why do we go to all this trouble? Above all, we want to avoid creating a “time bomb”—something that sits around unnoticed and blows up at an awkward moment later in the project. By emphasizing testing against contract, we can try to avoid as many of those downstream disasters as possible.
Tip 69: Design to Test
Ad Hoc Testing
Not to be confused with “odd hack,” ad-hoc testing is when we run poke at our code manually. This may be as simple as a console.log(), or a piece of code entered interactively in a debugger, IDE environment, or REPL.
At the end of the debugging session, you need to formalize this ad hoc test. If the code broke once, it is likely to break again. Don't just throw away the test you created; add it to the existing unit test arsenal.
Build a Test Window
Even the best sets of tests are unlikely to find all the bugs; there's something about the damp, warm conditions of a production environment that seems to bring them out of the woodwork.
This means you'll often need to test a piece of software once it has been deployed—with real-world data flowing though its veins. Unlike a circuit board or chip, we don't have test pins in software, but we can provide various views into the internal state of a module, without using the debugger (which may be inconvenient or impossible in a production application).
Log files containing trace messages are one such mechanism. Log messages should be in a regular, consistent format; you may want to parse them automatically to deduce processing time or logic paths that the program took. Poorly or inconsistently formatted diagnostics are just so much “spew”—they are difficult to read and impractical to parse.
Another mechanism for getting inside running code is the ”hot-key” sequence or magic URL. When this particular combination of keys is pressed, or the URL is accessed, a diagnostic control window pops up with status messages and so on. This isn't something you normally would reveal to end users, but it can be very handy for the help desk.
More generally, you could use a feature switch to enable extra diagnostics for a particular user or class of users.
A Culture of Testing
All software you write will be tested—if not by you and your team, then by the eventual users—so you might as well plan on testing it thoroughly. A little forethought can go a long way toward minimizing maintenance costs and help-desk calls.
You really only have a few choices:
- Test First
- Test During
- Test Never
Test First, including Test-Driven Design, is probably your best choice in most circumstances, as it ensures that testing happens. But sometimes that's not as convenient or useful, so Test During coding can be a good fallback, where you write some code, fiddle with it, write the tests for it, then move on to the next bit. The worst choice is often called “Test Later,” but who are you kidding? “Test Later” really means “Test Never.”
A culture of testing means all the tests pass all the time. Ignore a spew of tests that “always fail” makes it easier to ignore all the tests, and the vicious spiral begins (see Topic 3, Software Entropy).
Treat test code with the same care as any production code. Keep it decoupled, clean, and robust. Don't rely on unreliable things (see Topic 38, Programming by Coincidence) like the absolute position of widgets in a GUI system, or exact timestamps in a server log, or the exact wording of error messages. Testing for these sorts of things will result in fragile tests.
Tip 70: Test Your Software, or Your Users Will
Make no mistake, testing is part of programming. It's not something left to other departments or staff.
Testing, design, coding—it's all programming.
Related Sections Include
- Topic 27, Don't Outrun Your Headlights
- Topic 51, Pragmatic Starter Kit
Topic 42. Property-Based Testing
Доверяй, но проверяй (Trust, but verify)
Russian proverb
We recommend writing unit tests for your functions. You do that by thinking about typical things that might be a problem, based on your knowledge of the thing you're testing.
There's a small but potentially significant problem lurking in that paragraph, though. If you write the original code and you write the tests, is it possible that an incorrect assumption could be expressed in both? The code passes the tests, because it does what it is supposed to based on your understanding.
One way around this is to have different people write tests and the code under test, but we don't like this: as we said in Topic 41, Test to Code, one of the biggest benefits of thinking about tests is the way it informs the code you write. You lose that when the work of testing is split from the coding.
Instead, we favor an alternative, where the computer, which doesn't share your preconceptions, does some testing for you.
Contracts, Invariants, and Properties
In Topic 23, Design by Contract, we talked about the idea that code has contracts that it meets: you meet the conditions when you feed it input, and it will make certain guarantees about the outputs it produces.
There are also code invariants, things that remain true about some piece of state when it's passed through a function. For example, if you sort a list, the result will have the same number of elements as the original—the length is invariant.
Once we work out our contracts and invariants (which we're going to lump together and call properties) we can use them to automate our testing. What we end up doing is called property-based testing.
Tip 71: Use Property-Based Tests to Validate Your Assumptions
As an artificial example, we can build some tests for our sorted list. We've already established one property: the sorted list is the same size as the original. We can also state that no element in the result can be greater than the one that follows it.
We can now express that in code. Most languages have some kind of property-based testing framework. This example is in Python, and uses the Hypothesis tool and pytest, but the principles are pretty universal.
Here is the full source of the tests:
from hypothesis import given
import hypothesis.strategies as some
@given(some.lists(some.integers()))
def test_list_size_is_invariant_across_sorting(a_list):
original_length = len(a_list)
a_list.sort()
assert len(a_list) == original_length
@given(some.lists(some.text()))
def test_sorted_result_is_ordered(a_list):
a_list.sort()
for i in range(len(a_list) - 1):
assert a_list[i]
Here's what happens when we run it:
$ pytest sort.py ======================= test session starts ======================== ... plugins: hypothesis-4.14.0 sort.py .. [100%] ===================== 2 passed in 0.95 seconds =====================
Not much drama there. But, behind the scenes, Hypothesis ran both of our tests one hundred times, passing in a different list each time. The lists will have varying lengths, and will have different contents. It's as if we'd cooked up 200 individual tests with 200 random lists.
Test Data Generation
Like most property-based testing libraries, Hypothesis gives you a minilanguage for describing the data it should generate. The language is based around calls to functions in the hypothesis.strategies module, which we aliased as some, just because it reads better.
If we wrote:
@given(some.integers())
Our test function would run multiple times. Each time, it would be passed a different integer. If instead we wrote the following:
@given(some.integers(min_value=5, max_value=10).map(lambda x: x * 2))
then we'd get the even numbers between 10 and 20.
You can also compose types, so that
@given(some.lists(some.integers(min_value=1), max_size=100))
will be lists of natural numbers that are at most 100 elements long.
This isn't supposed to be a tutorial on any particular framework, so we'll skip a bunch of cool details and instead look at a real-world example.
Finding Bad Assumptions
We're writing a simple order processing and stock control system (because there's always room for one more). It models the stock levels with a Warehouse object. We can query a warehouse to see if something is in stock, remove things from stock, and get the current stock levels.
Here's the code:
class Warehouse:
def __init__(self, stock):
self.stock = stock
def in_stock(self, item_name):
return (item_name in self.stock) and (self.stock[item_name] > 0)
def take_from_stock(self, item_name, quantity):
if quantity
We wrote a basic unit test, which passes:
def test_warehouse():
wh = Warehouse({"shoes": 10, "hats": 2, "umbrellas": 0})
assert wh.in_stock("shoes")
assert wh.in_stock("hats")
assert not wh.in_stock("umbrellas")
wh.take_from_stock("shoes", 2)
assert wh.in_stock("shoes")
wh.take_from_stock("hats", 2)
assert not wh.in_stock("hats")
Then we wrote a function that processes a request to order items from the warehouse. It returns a tuple where the first element is either "ok" or "not available", followed by the item and requested quantity. We also wrote some tests, and they pass:
def order(warehouse, item, quantity):
if warehouse.in_stock(item):
warehouse.take_from_stock(item, quantity)
return ( "ok", item, quantity )
else:
return ( "not available", item, quantity )def test_order_in_stock():
wh = Warehouse({"shoes": 10, "hats": 2, "umbrellas": 0})
status, item, quantity = order(wh, "hats", 1)
assert status == "ok"
assert item == "hats"
assert quantity == 1
assert wh.stock_count("hats") == 1
def test_order_not_in_stock():
wh = Warehouse({"shoes": 10, "hats": 2, "umbrellas": 0})
status, item, quantity = order(wh, "umbrellas", 1)
assert status == "not available"
assert item == "umbrellas"
assert quantity == 1
assert wh.stock_count("umbrellas") == 0
def test_order_unknown_item():
wh = Warehouse({"shoes": 10, "hats": 2, "umbrellas": 0})
status, item, quantity = order(wh, "bagel", 1)
assert status == "not available"
assert item == "bagel"
assert quantity == 1
On the surface, everything looks fine. But before we ship the code, let's add some property tests.
One thing we know is that stock cannot appear and disappear across our transaction. This means that if we take some items from the warehouse, the number we took plus the number currently in the warehouse should be the same as the number originally in the warehouse. In the following test, we run our test with the item parameter chosen randomly from "hat" or "shoe" and the quantity chosen from 1 to 4:
@given(item = some.sampled_from(["shoes", "hats"]),
quantity = some.integers(min_value=1, max_value=4))
def test_stock_level_plus_quantity_equals_original_stock_level(item, quantity):
wh = Warehouse({"shoes": 10, "hats": 2, "umbrellas": 0})
initial_stock_level = wh.stock_count(item)
(status, item, quantity) = order(wh, item, quantity)
if status == "ok":
assert wh.stock_count(item) + quantity == initial_stock_level
Let's run it:
$ pytest stock.py
. . .
stock.py:72:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
stock.py:76: in test_stock_level_plus_quantity_equals_original_stock_level
(status, item, quantity) = order(wh, item, quantity)
stock.py:40: in order
warehouse.take_from_stock(item, quantity)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = at 0x10cf97cf8>, item_name = 'hats'
quantity = 3
def take_from_stock(self, item_name, quantity):
if quantity
It blew up in warehouse.take_from_stock: we tried to remove three hats from the warehouse, but it only has two in stock.
Our property testing found a faulty assumption: our in_stock function only checks that there's at least one of the given item in stock. Instead we need to make sure we have enough to fill the order:
def in_stock(self, item_name, quantity):
return (item_name in self.stock) and (self.stock[item_name] >= quantity)
And we change the order function, too:
def order(warehouse, item, quantity):
if warehouse.in_stock(item, quantity):
warehouse.take_from_stock(item, quantity)
return ( "ok", item, quantity )
else:
return ( "not available", item, quantity )
And now our property test passes.
Property-Based Tests Often Surprise You
In the previous example, we used a property-based test to check that stock levels were adjusted properly. The test found a bug, but it wasn't to do with stock level adjustment. Instead, it found a bug in our in_stock function.
This is both the power and the frustration of property-based testing. It's powerful because you set up some rules for generating inputs, set up some assertions for validating output, and then just let it rip. You never quite know what will happen. The test may pass. An assertion may fail. Or the code may fail totally because it couldn't handle the inputs it was given.
The frustration is that it can be tricky to pin down what failed.
Our suggestion is that when a property-based test fails, find out what parameters it was passing to the test function, and then use those values to create a separate, regular, unit test. That unit test does two things for you. First, it lets you focus in on the problem without all the additional calls being made into your code by the property-based testing framework. Second, that unit test acts as a regression test. Because property-based tests generate random values that get passed to your test, there's no guarantee that the same values will be used the next time you run tests. Having a unit test that forces those values to be used ensures that this bug won't slip through.
Property-Based Tests Also Help Your Design
When we talked about unit testing, we said that one of the major benefits was the way it made you think about your code: a unit test is the first client of your API.
The same is true of property-based tests, but in a slightly different way. They make you think about your code in terms of invariants and contracts; you think about what must not change, and what must be true. This extra insight has a magical effect on your code, removing edge cases and highlighting functions that leave data in an inconsistent state.
We believe that property-based testing is complementary to unit testing: they address different concerns, and each brings its own benefits. If you're not currently using them, give them a go.
Related Sections Include
- Topic 23, Design by Contract
- Topic 25, Assertive Programming
- Topic 45, The Requirements Pit
Exercises
Exercise 31 (possible answer)
Look back at the warehouse example. Are there any other properties that you can test?
Exercise 32 (possible answer)
Your company ships machinery. Each machine comes in a crate, and each crate is rectangular. The crates vary in size. Your job is to write some code to pack as many crates as possible in a single layer that fits in the delivery truck. The output of your code is a list of all the crates. For each crate, the list gives the location in the truck, along with the width and height. What properties of the output could be tested?
Challenges
Think about the code you're currently working on. What are the properties: the contracts and invariants? Can you use property-based testing framework to verify these automatically?
Topic 43. Stay Safe Out There
Good fences make good neighbors.
Robert Frost, Mending Wall
In the first edition's discussion of code coupling we made a bold and naive statement: “we don't need to be as paranoid as spies or dissidents.” We were wrong. In fact, you do need to be that paranoid, every day.
As we write this, the daily news is filled with stories of devastating data breaches, hijacked systems, and cyberfraud. Hundreds of millions of records stolen at once, billions and billions of dollars in losses and remediation—and these numbers are growing rapidly each year. In the vast majority of cases, it's not because the attackers were terribly clever, or even vaguely competent.
It's because the developers were careless.
The Other 90%
When coding, you may go through several cycles of “it works!” and “why isn't that working?” with the occasional “there's no way that could have happened…”[62] After several hills and bumps on this uphill climb, it's easy to say to yourself, “phew, it all works!” and proclaim the code done. Of course, it's not done yet. You're 90% done, but now you have the other 90% to consider.
The next thing you have to do is analyze the code for ways it can go wrong and add those to your test suite. You'll consider things such as passing in bad parameters, leaking or unavailable resources; that sort of thing.
In the good old days, this evaluation of internal errors may have been sufficient. But today that's only the beginning, because in addition to errors from internal causes, you need to consider how an external actor could deliberately screw up the system. But perhaps you protest, “Oh, no one will care about this code, it's not important, no one even knows about this server…” It's a big world out there, and most of it is connected. Whether it's a bored kid on the other side of the planet, state-sponsored terrorism, criminal gangs, corporate espionage, or even a vengeful ex, they are out there and aiming for you. The survival time of an unpatched, outdated system on the open net is measured in minutes—or even less.
Security through obscurity just doesn't work.
Security Basic Principles
Pragmatic Programmers have a healthy amount of paranoia. We know we have faults and limitations, and that external attackers will seize on any opening we leave to compromise our systems. Your particular development and deployment environments will have their own security-centric needs, but there are a handful of basic principles that you should always bear in mind:
- Minimize Attack Surface Area
- Principle of Least Privilege
- Secure Defaults
- Encrypt Sensitive Data
- Maintain Security Updates
Let's take a look at each of these.
Minimize Attack Surface Area
The attack surface area of a system is the sum of all access points where an attacker can enter data, extract data, or invoke execution of a service. Here are a few examples:
- Code complexity leads to attack vectors
-
Code complexity makes the attack surface larger, with more opportunities for unanticipated side effects. Think of complex code as making the surface area more porous and open to infection. Once again, simple, smaller code is better. Less code means fewer bugs, fewer opportunities for a crippling security hole. Simpler, tighter, less complex code is easier to reason about, easier to spot potential weaknesses.
- Input data is an attack vector
-
Never trust data from an external entity, always sanitize it before passing it on to a database, view rendering, or other processing.[63] Some languages can help with this. In Ruby, for example, variables holding external input are tainted, which limits what operations can be performed on them. For example, this code apparently uses the wc utility to report on the number of characters in a file whose name is supplied at runtime:
puts "Enter a file name to count: " name = gets system("wc -c #{name}")-
A nefarious user could do damage like this:
Enter a file name to count: test.dat; rm -rf /
-
However, setting the SAFE level to 1 will taint external data, which means it can't be used in dangerous contexts:
$SAFE = 1 puts "Enter a file name to count: " name = gets system("wc -c #{name}")-
Now when we run it, we get caught red-handed:
$ ruby taint.rb Enter a file name to count: test.dat; rm -rf / code/safety/taint.rb:5:in `system': Insecure operation - system (SecurityError) from code/safety/taint.rb:5:in `main
- Unauthenticated services are an attack vector
-
By their very nature, any user anywhere in the world can call unauthenticated services, so barring any other handling or limiting you've immediately created an opportunity for a denial-of-service attack at the very least. Quite a few of highly public data breaches recently were caused by developers accidentally putting data in unauthenticated, publicly readable data stores in the cloud.
- Authenticated services are an attack vector
-
Keep the number of authorized users at an absolute minimum. Cull unused, old, or outdated users and services. Many net-enabled devices have been found to contain simple default passwords or unused, unprotected administrative accounts. If an account with deployment credentials is compromised, your entire product is compromised.
- Output data is an attack vector
-
There's a (possibly apocryphal) story about a system that dutifully reported the error message Password is used by another user. Don't give away information. Make sure that the data you report is appropriate for the authorization of that user. Truncate or obfuscate potentially risky information such as Social Security or other government ID numbers.
- Debugging info is an attack vector
-
There's nothing as heartwarming as seeing a full stack trace with data on your local ATM machine, an airport kiosk, or crashing web page. Information designed to make debugging easier can make breaking in easier as well. Make sure any “test window” (discussed here) and runtime exception reporting is protected from spying eyes.[64]
Tip 72: Keep It Simple and Minimize Attack Surfaces
Principle of Least Privilege
Another key principle is to use the least amount of privilege for the shortest time you can get away with. In other words, don't automatically grab the highest permission level, such as root or Administrator. If that high level is needed, take it, do the minimum amount of work, and relinquish your permission quickly to reduce the risk. This principle dates back to the early 1970s:
Every program and every privileged user of the system should operate using the least amount of privilege necessary to complete the job.— Jerome Saltzer, Communications of the ACM, 1974.
Take the login program on Unix-derived systems. It initially executes with root privileges. As soon as it finishes authenticating the correct user, though, it drops the high level privilege to that of the user.
This doesn't just apply to operating system privilege levels. Does your application implement different levels of access? Is it a blunt tool, such as “administrator” vs. “user?” If so, consider something more finely grained, where your sensitive resources are partitioned into different categories, and individual users have permissions for only certain of those categories.
This technique follows the same sort of idea as minimizing surface area—reducing the scope of attack vectors, both by time and by privilege level. In this case, less is indeed more.
Secure Defaults
The default settings on your app, or for your users on your site, should be the most secure values. These might not be the most user-friendly or convenient values, but it's better to let each individual decide for themselves the trade-offs between security and convenience.
For example, the default for password entry might be to hide the password as entered, replacing each character with an asterisk. If you're entering a password in a crowded public place, or projected before a large audience, that's a sensible default. But some users might want to see the password spelled out, perhaps for accessibility. If there's little risk someone is looking over their shoulder, that's a reasonable choice for them.
Encrypt Sensitive Data
Don't leave personally identifiable information, financial data, passwords, or other credentials in plain text, whether in a database or some other external file. If the data gets exposed, encryption offers an additional level of safety.
In Topic 19, Version Control we strongly recommend putting everything needed for the project under version control. Well, almost everything. Here's one major exception to that rule:
Don't check in secrets, API keys, SSH keys, encryption passwords or other credentials alongside your source code in version control.
Keys and secrets need to be managed separately, generally via config files or environment variables as part of build and deployment.
Maintain Security Updates
Updating computer systems can be a huge pain. You need that security patch, but as a side effect it breaks some portion of your application. You could decide to wait, and defer the update until later. That's a terrible idea, because now your system is vulnerable to a known exploit.
Tip 73: Apply Security Patches Quickly
This tip affects every net-connected device, including phones, cars, appliances, personal laptops, developer machines, build machines, production servers, and cloud images. Everything. And if you think that this doesn't really matter, just remember that the largest data breaches in history (so far) were caused by systems that were behind on their updates.
Don't let it happen to you.
Common Sense vs. Crypto
It's important to keep in mind that common sense may fail you when it comes to matters of cryptography. The first and most important rule when it comes to crypto is never do it yourself.[66] Even for something as simple as passwords, common practices are wrongheaded (see the sidebar Password Antipatterns). Once you get into the world of crypto, even the tiniest, most insignificant-looking error can compromise everything: your clever new, home-made encryption algorithm can probably be broken by an expert in minutes. You don't want to do encryption yourself.
As we've said elsewhere, rely only on reliable things: well-vetted, thoroughly examined, well-maintained, frequently updated, preferably open source libraries and frameworks.
Beyond simple encryption tasks, take a hard look at other security-related features of your site or application. Take authentication, for instance.
In order to implement your own login with password or biometric authentication, you need to understand how hashes and salts work, how crackers use things like Rainbow tables, why you shouldn't use MD5 or SHA1, and a host of other concerns. And even if you get all that right, at the end of the day you're still responsible for holding onto the data and keeping it secure, subject to whatever new legislation and legal obligations come up.
Or, you could take the Pragmatic approach and let someone else worry about it and use a third-party authentication provider. This may be an off-the-shelf service you run in-house, or it could be a third party in the cloud. Authentication services are often available from email, phone, or social media providers, which may or may not be appropriate for your application. In any case, these folks spend all their days keeping their systems secure, and they're better at it than you are.
Stay safe out there.
Related Sections Include
- Topic 23, Design by Contract
- Topic 24, Dead Programs Tell No Lies
- Topic 25, Assertive Programming
- Topic 38, Programming by Coincidence
- Topic 45, The Requirements Pit
Topic 44. Naming Things
The beginning of wisdom is to call things by their proper name.
Confucius
What's in a name? When we're programming, the answer is “everything!”
We create names for applications, subsystems, modules, functions, variables—we're constantly creating new things and bestowing names on them. And those names are very, very important, because they reveal a lot about your intent and belief.
We believe that things should be named according to the role they play in your code. This means that, whenever you create something, you need to pause and think “what is my motivation to create this?”
This is a powerful question, because it takes you out of the immediate problem-solving mindset and makes you look at the bigger picture. When you consider the role of a variable or function, you're thinking about what is special about it, about what it can do, and what it interacts with. Often, we find ourselves realizing that what we were about to do made no sense, all because we couldn't come up with an appropriate name.
There's some science behind the idea that names are deeply meaningful. It turns out that the brain can read and understand words really fast: faster than many other activities. This means that words have a certain priority when we try to make sense of something. This can be demonstrated using the Stroop effect.[67]
Look at the following panel. It has a list of color names or shades, and each is shown in a color or shade. But the names and colors don't necessarily match. Here's part one of the challenge—say aloud the name of each color as written:[68]

Now repeat this, but instead say aloud the color used to draw the word. Harder, eh? It's easy to be fluent when reading, but way harder when trying to recognize colors.
Your brain treats written words as something to be respected. We need to make sure the names we use live up to this.
Let's look at a couple of examples:
-
We're authenticating people who access our site that sells jewelry made from old graphics cards:
let user = authenticate(credentials)
The variable is user because it's always user. But why? It means nothing. How about customer, or buyer? That way we get constant reminders as we code of what this person is trying to do, and what that means to us.
-
We have an instance method that discounts an order:
public void deductPercent(double amount) // ...Two things here. First, deductPercent is what it does and not why it does it. Then the name of the parameter amount is at best misleading: is it an absolute amount, a percentage?
Perhaps this would be better:
public void applyDiscount(Percentage discount) // ...
The method name now makes its intent clear. We've also changed the parameter from a double to a Percentage, a type we've defined. We don't know about you, but when dealing with percentages we never know if the value is supposed to be between 0 and 100 or 0.0 and 1.0. Using a type documents what the function expects.
-
We have a module that does interesting things with Fibonacci numbers. One of those things is to calculate the $n^{th}$ number in the sequence. Stop and think what you'd call this function.
Most people we ask would call it fib. Seems reasonable, but remember it will normally be called in the context of its module, so the call would be Fib.fib(n). How about calling it of or nth instead:
Fib.of(0) # => 0 Fib.nth(20) # => 4181
When naming things, you're constantly looking for ways of clarifying what you mean, and that act of clarification will lead you to a better understanding of your code as you write it.
However, not all names have to be candidates for a literary prize.
Honor the Culture
Most introductory computer texts will admonish you never to use single letter variables such as i, j, or k.[69]
We think they're wrong. Sort of.
In fact, it depends on the culture of that particular programming language or environment. In the C programming language, i, j, and k are traditionally used as loop increment variables, s is used for a character string, and so on. If you program in that environment, that's what you are used to seeing and it would be jarring (and hence wrong) to violate that norm. On the other hand, using that convention in a different environment where it's not expected is just as wrong. You'd never do something heinous like this Clojure example which assigns a string to variable i:
(let [i "Hello World"]
(println i))
Some language communities prefer camelCase, with embedded capital letters, while others prefer snake_case with embedded underscores to separate words. The languages themselves will of course accept either, but that doesn't make it right. Honor the local culture.
Some languages allow a subset of Unicode in names. Get a sense of what the community expects before going all cute with names like ɹǝsn or εξέρχεται.
Consistency
Emerson is famous for writing “A foolish consistency is the hobgoblin of little minds…,” but Emerson wasn't on a team of programmers.
Every project has its own vocabulary: jargon words that have a special meaning to the team. “Order” means one thing to a team creating an online store, and something very different to a team whose app charts the lineage of religious groups. It's important that everyone on the team knows what these words mean, and that they use them consistently.
One way is to encourage a lot of communication. If everyone pair programs, and pairs switch frequently, then jargon will spread osmotically.
Another way is to have a project glossary, listing the terms that have special meaning to the team. This is an informal document, possibly maintained on a wiki, possibly just index cards on a wall somewhere.
After a while, the project jargon will take on a life of its own. As everyone gets comfortable with the vocabulary, you'll be able to use the jargon as a shorthand, expressing a lot of meaning accurately and concisely. (This is exactly what a pattern language is.)
Renaming Is Even Harder
No matter how much effort you put in up front, things change. Code is refactored, usage shifts, meaning becomes subtly altered. If you aren't vigilant about updating names as you go, you can quickly descend into a nightmare much worse than meaningless names: misleading names. Have you ever had someone explain inconsistencies in code such as, “The routine called getData really writes data to an archive file”?
As we discuss in Topic 3, Software Entropy, when you spot a problem, fix it—right here and now. When you see a name that no longer expresses the intent, or is misleading or confusing, fix it. You've got full regression tests, so you'll spot any instances you may have missed.
Tip 74: Name Well; Rename When Needed
If for some reason you can't change the now-wrong name, then you've got a bigger problem: an ETC violation (see Topic 8, The Essence of Good Design). Fix that first, then change the offending name. Make renaming easy, and do it often.
Otherwise you'll have to explain to the new folks on the team that getData really writes data to a file, and you'll have to do it with a straight face.
Related Sections Include
- Topic 3, Software Entropy
- Topic 40, Refactoring
- Topic 45, The Requirements Pit
Challenges
-
When you find a function or method with an overly generic name, try and rename it to express all the things it really does. Now it's an easier target for refactoring.
-
In our examples, we suggested using more specific names such as buyer instead of the more traditional and generic user. What other names do you habitually use that could be better?
-
Are the names in your system congruent with user terms from the domain? If not, why? Does this cause a Stroop-effect style cognitive dissonance for the team?
-
Are names in your system hard to change? What can you do to fix that particular broken window?
[50]Note from the battle-scarred: UTC is there for a reason. Use it.
[51]https://en.wikipedia.org/wiki/Correlation_does_not_imply_causation
[52]See Topic 50, Coconuts Don't Cut It.
[53]You can also go too far here. We once knew a developer who rewrote all source he was given because he had his own naming conventions.
[54]https://media-origin.pragprog.com/titles/tpp20/code/algorithm_speed/sort/src/main.rs
[55]And yes, we did voice our concerns over the title.
[56]Originally spotted in UML Distilled: A Brief Guide to the Standard Object Modeling Language [Fow00].
[57]This is excellent advice in general (see Topic 27, Don't Outrun Your Headlights).
[58]Some folks argue that test-first and test-driven development are two different things, saying that the intents of the two are different. However, historically, test-first (which comes from eXtreme Programming) was identical to what people now call TDD.
[59]https://ronjeffries.com/categories/sudoku. A big “thank you” to Ron for letting us use this story.
[60]http://norvig.com/sudoku.html
[61]We've been trying since at least 1986, when Cox and Novobilski coined the term “software IC” in their Objective-C book Object-Oriented Programming Object-Oriented Programming: An Evolutionary Approach [CN91].
[62]See Topic 20, Debugging.
[63]Remember our good friend, little Bobby Tables (https://xkcd.com/327)? While you're reminiscing have a look at https://bobby-tables.com, which lists ways of sanitizing data passed to database queries.
[64]This technique has proven to be successful at the CPU chip level, where well-known exploits target debugging and administrative facilities. Once cracked, the entire machine is left exposed.
[65]NIST Special Publication 800-63B: Digital Identity Guidelines: Authentication and Lifecycle Management, available free online at https://doi.org/10.6028/NIST.SP.800-63b
[66]Unless you have a PhD in cryptography, and even then only with major peer review, extensive field trials with a bug bounty, and budget for long-term maintenance.
[67]Studies of Interference in Serial Verbal Reactions [Str35]
[68]We have two versions of this panel. One uses different colors, and the other uses shades of gray. If you're seeing this in black and white and want the color version, or if you're having trouble distinguishing colors and want to try the grayscale version, pop over to https://pragprog.com/the-pragmatic-programmer/stroop-effect.
[69]Do you know why i is commonly used as a loop variable? The answer comes from over 60 years ago, when variables starting with I through N were integers in the original FORTRAN. And FORTRAN was in turn influenced by algebra.