Appendix 2 - Possible Answers to the Exercises
Answer 1 (from exercise 1)
To our way of thinking, class Split2 is more orthogonal. It concentrates on its own task, splitting lines, and ignores details such as where the lines are coming from. Not only does this make the code easier to develop, but it also makes it more flexible. Split2 can split lines read from a file, generated by another routine, or passed in via the environment.
Answer 2 (from exercise 2)
Let's start with an assertion: you can write good, orthogonal code in just about any language. At the same time, every language has temptations: features that can lead to increased coupling and decreased orthogonality.
In OO languages, features such as multiple inheritance, exceptions, operator overloading, and parent-method overriding (via subclassing) provide ample opportunity to increase coupling in nonobvious ways. There is also a kind of coupling because a class couples code to data. This is normally a good thing (when coupling is good, we call it cohesion). But if you don't make your classes focused enough, it can lead to some pretty ugly interfaces.
In functional languages, you're encouraged to write lots of small, decoupled functions, and to combine them in different ways to solve your problem. In theory this sounds good. In practice it often is. But there's a form of coupling that can happen here, too. These functions typically transform data, which means the result of one function can become the input to another. If you're not careful, making a change to the data format a function generates can result in a failure somewhere down the transformational stream. Languages with good type systems can help mitigate this.
Answer 3 (from exercise 3)
Low-tech to the rescue! Draw a few cartoons with markers on a whiteboard—a car, a phone, and a house. It doesn't have to be great art; stick-figure outlines are fine. Put Post-it notes that describe the contents of target pages on the clickable areas. As the meeting progresses, you can refine the drawings and placements of the Post-it notes.
Answer 4 (from exercise 4)
Because we want to make the language extendable, we'll make the parser table driven. Each entry in the table contains the command letter, a flag to say whether an argument is required, and the name of the routine to call to handle that particular command.
typedef struct {
char cmd; /* the command letter */
int hasArg; /* does it take an argument */
void (*func)(int, int); /* routine to call */
} Command;
static Command cmds[] = {
{ 'P', ARG, doSelectPen },
{ 'U', NO_ARG, doPenUp },
{ 'D', NO_ARG, doPenDown },
{ 'N', ARG, doPenDir },
{ 'E', ARG, doPenDir },
{ 'S', ARG, doPenDir },
{ 'W', ARG, doPenDir }
};
The main program is pretty simple: read a line, look up the command, get the argument if required, then call the handler function.
while (fgets(buff, sizeof(buff), stdin)) {
Command *cmd = findCommand(*buff);
if (cmd) {
int arg = 0;
if (cmd->hasArg !getArg(buff+1, )) {
fprintf(stderr, "'%c' needs an argument\n", *buff);
continue;
}
cmd->func(*buff, arg);
}
}
The function that looks up a command performs a linear search of the table, returning either the matching entry or NULL.
Command *findCommand(int cmd) {
int i;
for (i = 0; i
Finally, reading the numeric argument is pretty simple using sscanf.
int getArg(const char *buff, int *result) {
return sscanf(buff, "%d", result) == 1;
}
Answer 5 (from exercise 5)
Actually, you've already solved this problem in the previous exercise, where you wrote an interpreter for the external language, will contain the internal interpreter. In the case of our sample code, this is the doXxx functions.
Answer 6 (from exercise 6)
Using BNF, a time specification could be
time | ::= | hour ampm | hour : minute ampm | hour : minute |
ampm | ::= | am | pm |
hour | ::= | digit | digit digit |
minute | ::= | digit digit |
digit | ::= | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
A better definition of hour and minute would take into account that an hours can only be from 00 to 23, and a minute from 00 to 59:
hour | ::= | h-tens digit | digit |
minute | ::= | m-tens digit |
h-tens | ::= | 0 | 1 |
m-tens | ::= | 0 | 1 | 2 | 3 | 4 | 5 |
digit | ::= | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
Answer 7 (from exercise 7)
Here's the parser written using the Pegjs JavaScript library:
time
= h:hour offset:ampm { return h + offset }
/ h:hour ":" m:minute offset:ampm { return h + m + offset }
/ h:hour ":" m:minute { return h + m }
ampm
= "am" { return 0 }
/ "pm" { return 12*60 }
hour
= h:two_hour_digits { return h*60 }
/ h:digit { return h*60 }
minute
= d1:[0-5] d2:[0-9] { return parseInt(d1+d2, 10); }
digit
= digit:[0-9] { return parseInt(digit, 10); }
two_hour_digits
= d1:[01] d2:[0-9 ] { return parseInt(d1+d2, 10); }
/ d1:[2] d2:[0-3] { return parseInt(d1+d2, 10); }
The tests show it in use:
let test = require('tape');
let time_parser = require('./time_parser.js');
// time ::= hour ampm |
// hour : minute ampm |
// hour : minute
//
// ampm ::= am | pm
//
// hour ::= digit | digit digit
//
// minute ::= digit digit
//
// digit ::= 0 |1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
const h = (val) => val*60;
const m = (val) => val;
const am = (val) => val;
const pm = (val) => val + h(12);
let tests = {
"1am": h(1),
"1pm": pm(h(1)),
"2:30": h(2) + m(30),
"14:30": pm(h(2)) + m(30),
"2:30pm": pm(h(2)) + m(30),
}
test('time parsing', function (t) {
for (const string in tests) {
let result = time_parser.parse(string)
t.equal(result, tests[string], string);
}
t.end()
});
Answer 8 (from exercise 8)
Here's a possible solution in Ruby:
TIME_RE = %r{
(?[0-9]){0}
(?[0-1]){0}
(?[0-6]){0}
(? am | pm){0}
(? (\g \g) | \g){0}
(? \g \g){0}
\A(
( \g \g )
| ( \g : \g \g )
| ( \g : \g )
)\Z
}x
def parse_time(string)
result = TIME_RE.match(string)
if result
result[:hour].to_i * 60 +
(result[:minute] || "0").to_i +
(result[:ampm] == "pm" ? 12*60 : 0)
end
end
(This code uses the trick of defining named patterns at the start of the regular expression, and then referencing them as subpatterns in the actual match.)
Answer 9 (from exercise 9)
Our answer must be couched in several assumptions:
- The storage device contains the information we need to be transferred.
- We know the speed at which the person walks.
- We know the distance between the machines.
- We are not accounting for the time it takes to transfer information to and from the storage device.
- The overhead of storing data is roughly equal to the overhead of sending it over a communications line.
Answer 10 (from exercise 10)
Subject to the caveats in the previous answer: A 1TB tape contains 8×240, or 243 bits, so a 1Gbps line would have to pump data for about 9,000 seconds, or roughly 2½ hours, to transfer the equivalent amount of information. If the person is walking at a constant 3½ mph, then our two machines would need to be almost 9 miles apart for the communications line to outperform our courier. Otherwise, the person wins.
Answer 14 (from exercise 14)
We'll show the function signatures in Java, with the pre- and postconditions in comments.
First, the invariant for the class:
/** * @invariant getSpeed() > 0 * implies isFull() // Don't run empty * * @invariant getSpeed() >= 0 * getSpeed()
Next, the pre- and postconditions:
/** * @pre Math.abs(getSpeed() - x)
Answer 15 (from exercise 15)
There are 21 terms in the series. If you said 20, you just experienced a fencepost error (not knowing whether to count the fenceposts or the spaces between them).
Answer 16 (from exercise 16)
-
September, 1752 had only 19 days. This was done to synchronize calendars as part of the Gregorian Reformation.
-
The directory could have been removed by another process, you might not have permission to read it, the drive might not be mounted, …; you get the picture.
-
We sneakily didn't specify the types of a and b. Operator overloading might have defined +, =, or != to have unexpected behavior. Also, a and b may be aliases for the same variable, so the second assignment will overwrite the value stored in the first. Also, if the program is concurrent and badly written, a might have been updated by the time the addition takes place.
-
In non-Euclidean geometry, the sum of the angles of a triangle will not add up to 180°. Think of a triangle mapped on the surface of a sphere.
-
Leap minutes may have 61 or 62 seconds.
-
Depending on the language, numeric overflow may leave the result of a+1 negative.
Answer 17 (from exercise 17)
In most C and C++ implementations, there is no way of checking that a pointer actually points to valid memory. A common mistake is to deallocate a block of memory and reference that memory later in the program. By then, the memory pointed to may well have been reallocated to some other purpose. By setting the pointer to NULL, the programmers hope to prevent these rogue references—in most cases, dereferencing a NULL pointer will generate a runtime error.
Answer 18 (from exercise 18)
By setting the reference to NULL, you reduce the number of pointers to the referenced object by one. Once this count reaches zero, the object is eligible for garbage collection. Setting the references to NULL can be significant for long-running programs, where the programmers need to ensure that memory utilization doesn't increase over time.
Answer 19 (from exercise 19)
A simple implementation could be:
class FSM
def initialize(transitions, initial_state)
@transitions = transitions
@state = initial_state
end
def accept(event)
@state, action = TRANSITIONS[@state][event] || TRANSITIONS[@state][:default]
end
end
(Download this file to get the updated code that uses this new FSM class.)
Answer 20 (from exercise 20)
-
…three network interface down events within five minutes
This could be implemented using a state machine, but it would be trickier than it might first appear: if you get events at minutes 1, 4, 7, and 8, then you should trigger the warning on the fourth event, which means the state machine needs to be able to handle reseting itself.
For this reason, event streams would seem to be the technology of choice. There's a reactive function named buffer with size and offset parameters that would let you return each group of three incoming events. You could then look at the timestamps of the first and last event in a group to determine if the alarm should be triggered.
-
…after sunset, and there is motion detected at the bottom of the stairs followed by motion detected at the top of the stairs…
This could probably be implemented using a combination of pubsub and state machines. You could use pubsub to disseminate events to any number of state machines, and then have the state machines determine what to do.
-
…notify various reporting systems that an order was completed.
This is probably best handled using pubsub. You might want to use streams, but that would require that the systems being notified were also stream based.
-
…three backend services and wait for the responses.
This is similar to our example that used streams to fetch user data.
Answer 21 (from exercise 21)
-
Shipping and sales tax are added to an order:
basic order → finalized order
In conventional code, it's likely you'd have a function that calculated shipping costs and another that calculated tax. But we're thinking about transformations here, so we transform an order with just items into a new kind of thing: an order that can be shipped.
-
Your application loads configuration information from a named file:
file name → configuration structure
-
Someone logs in to a web application:
user credentials → session
Answer 22 (from exercise 22)
The high-level transformation:
field contents as string
→ [validate convert]
→ {:ok, value} | {:error, reason}
could be broken down into:
field contents as string
→ [convert string to integer]
→ [check value >= 18]
→ [check value
This assumes that you have an error-handling pipeline.
Answer 23 (from exercise 23)
Let's answer the second part first: we prefer the first piece of code.
In the second chunk of code, each step returns an object that implements the next function we call: the object returned by content_of must implement find_matching_lines, and so on.
This means that the object returned by content_of is coupled to our code. Imagine the requirement changed, and we have to ignore lines starting with a # character. In the transformation style, that would be easy:
const content = File.read(file_name); const no_comments = remove_comments(content) const lines = find_matching_lines(no_comments, pattern) const result = truncate_lines(lines)
We could even swap the order of remove_comments and find_matching_lines and it would still work.
But in the chained style, this would be more difficult. Where should our remove_comments method live: in the object returned by content_of or the object returned by find_matching_lines? And what other code will we break if we change that object? This coupling is why the method chaining style is sometimes called a train wreck.
Answer 24 (from exercise 24)
- Image processing.
-
For simple scheduling of a workload among the parallel processes, a shared work queue may be more than adequate. You might want to consider a blackboard system if there is feedback involved—that is, if the results of one processed chunk affect other chunks, as in machine vision applications, or complex 3D image-warp transforms.
- Group calendaring
-
This might be a good fit. You can post scheduled meetings and availability to the blackboard. You have entities functioning autonomously, feedback from decisions is important, and participants may come and go.
You might want to consider partitioning this kind of blackboard system depending on who is searching: junior staff may care about only the immediate office, human resources may want only English-speaking offices worldwide, and the CEO may want the whole enchilada.
There is also some flexibility on data formats: we are free to ignore formats or languages we don't understand. We have to understand different formats only for those offices that have meetings with each other, and we do not need to expose all participants to a full transitive closure of all possible formats. This reduces coupling to where it is necessary, and does not constrain us artificially.
- Network monitoring tool
-
This is very similar to the mortgage/loan application program. You've got trouble reports sent in by users and statistics reported automatically, all posting to the blackboard. A human or software agent can analyze the blackboard to diagnose network failures: two errors on a line might just be cosmic rays, but 20,000 errors and you've got a hardware problem. Just as the detectives solve the murder mystery, you can have multiple entities analyzing and contributing ideas to solve the network problems.
Answer 25 (from exercise 25)
The assumption with a list of key-value pairs is generally that the key is unique, and hash libraries typically enforce that either by the behavior of the hash itself or with explicit error messages for duplicated keys. However, an array typically does not have those constraints, and will happily store duplicate keys unless you code it specifically not to. So in this case, the first key found that matches DepositAccount wins, and any remaining matching entries are ignored. The order of entries is not guaranteed, so sometimes it works and sometimes it doesn't.
And what about the difference in machines from development and production? It's just a coincidence.
Answer 26 (from exercise 26)
The fact that a purely numeric field works in the US, Canada, and the Caribbean is a coincidence. Per the ITU spec, international call format starts with a literal + sign. The * character is also used in some locales, and more commonly, leading zeros can be a part of the number. Never store a phone number in a numeric field.
Answer 27 (from exercise 27)
Depends on where you are. In the US, volume measures are based on the gallon, which is the volume of a cylinder 6 inches high and 7 inches in diameter, rounded to the nearest cubic inch.
In Canada, “one cup” in a recipe could mean any of
- 1/5 of an imperial quart, or 227ml
- 1/4 of a US quart, or 236ml
- 16 metric tablespoons, or 240ml
- 1/4 of a liter, or 250ml
Unless you're talking about a rice cooker, in which case “one cup” is 180ml. That derives from the koku, which was the estimated volume of dry rice required to feed one person for one year: apparently, around 180L. Rice cooker cups are 1 gō, which is 1/1000 of a koku. So, roughly the amount of rice a person would eat at a single meal.[85]
Answer 28 (from exercise 28)
Clearly, we can't give any absolute answers to this exercise. However, we can give you a couple of pointers.
If you find that your results don't follow a smooth curve, you might want to check to see if some other activity is using some of your processor's power. You probably won't get good figures if background processes periodically take cycles away from your programs. You might also want to check memory: if the application starts using swap space, performance will nose dive.
Here's a graph of the results of running the code on one of our machines:
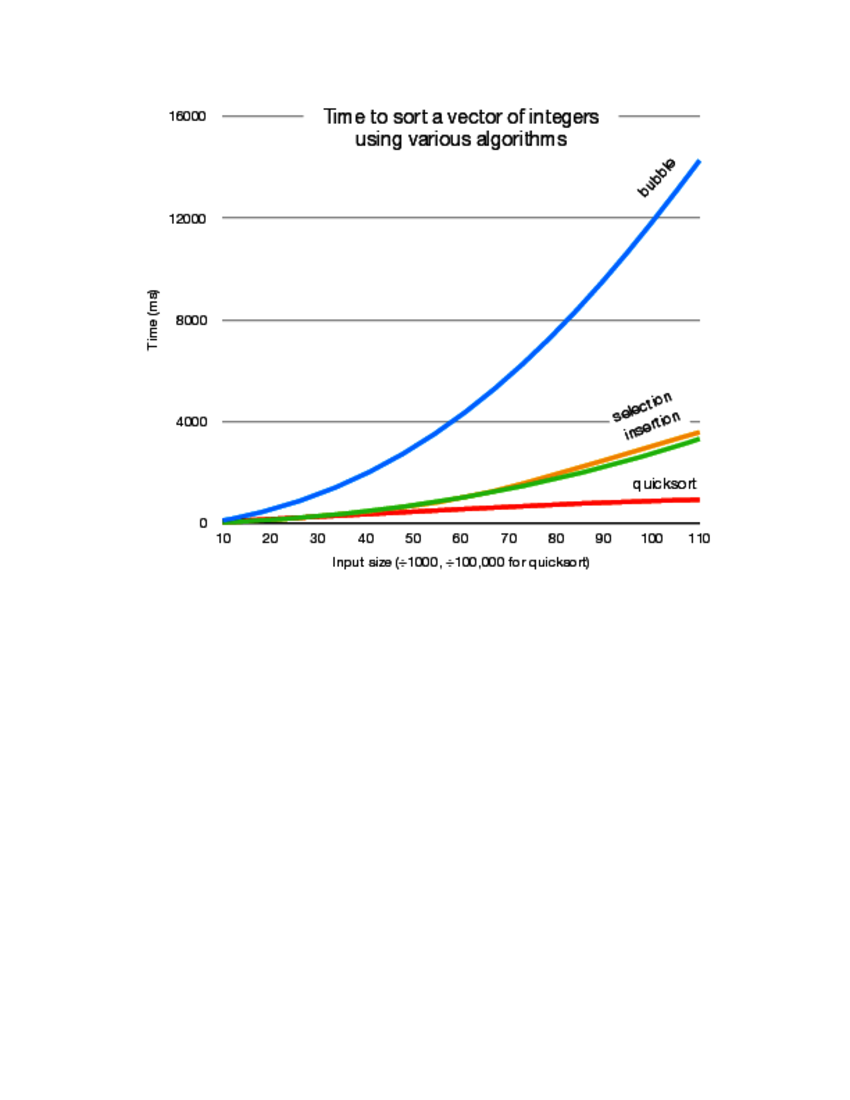
Answer 29 (from exercise 29)
There are a couple of ways of getting there. One is to turn the problem on its head. If the array has just one element, we don't iterate around the loop. Each additional iteration doubles the size of the array we can search. The general formula for the array size is therefore $n=2^m$, where $m$ is the number of iterations. If you take logs to the base 2 of each side, you get $\lg{n} = \lg{2^m}$, which by the definition of logs becomes $\lg{n} = m$.
Answer 30 (from exercise 30)
This is probably too much of a flashback to secondary school math, but the formula for converting a logarithm in base $a$ to one in base $b$ is:
$$ \log_{b}{x} = \frac{\log_{a}{x}}{\log_a{b}}$$
Because $\log_a{b}$ is a constant, then we can ignore it inside a Big-O result.
Answer 31 (from exercise 31)
One property we can test is that an order succeeds if the warehouse has enough items on hand. We can generate orders for random quantities of items, and verify that an "OK" tuple is returned if the warehouse had stock.
Answer 32 (from exercise 32)
This is a good use of property-based testing. The unit tests can focus on individual cases where you've worked out the result by some other means, and the property tests can focus on things like:
- Do any two crates overlap?
- Does any part of any crate exceed the width or length of the truck?
- Is the packing density (area used by crates divided by the area of the truck bed) less than or equal to 1?
- If it's part of the requirement, does the packing density exceed the minimum acceptable density?
Answer 33 (from exercise 33)
-
This statement sounds like a real requirement: there may be constraints placed on the application by its environment.
-
On its own, this statement isn't really a requirement. But to find out what's really required, you have to ask the magic question, “Why?”
It may be that this is a corporate standard, in which case the actual requirement should be something like “all UI elements must conform to the MegaCorp User Interface Standards, V12.76.”
It may be that this is a color that the design team happen to like. In that case, you should think about the way the design team also likes to change their minds, and phrase the requirement as “the background color of all modal windows must be configurable. As shipped, the color will be gray.” Even better would be the broader statement “All visual elements of the application (colors, fonts, and languages) must be configurable.”
Or it may simply mean that the user needs to be able to distinguish modal and nonmodal windows. If that's the case, some more discussions are needed.
-
This statement is not a requirement, it's architecture. When faced with something like this, you have to dig deep to find out what the user is thinking. Is this a scaling issue? Or performance? Cost? Security? The answers will inform your design.
-
The underlying requirement is probably something closer to “The system will prevent the user from making invalid entries in fields, and will warn the user when these entries are made.''
-
This statement is probably a hard requirement, based on some hardware limitation.
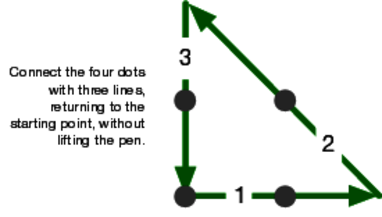
And here's a solution to the four-dots problem:
[85]Thanks for this bit of trivia goes to Avi Bryant (@avibryant)