Chapter 6 - Concurrency
Just so we're all on the same page, let's start with some definitions:
Concurrency is when the execution of two or more pieces of code act as if they run at the same time. Parallelism is when they do run at the same time.
To have concurrency, you need to run code in an environment that can switch execution between different parts of your code when it is running. This is often implemented using things such as fibers, threads, and processes.
To have parallelism, you need hardware that can do two things at once. This might be multiple cores in a CPU, multiple CPUs in a computer, or multiple computers connected together.
Topic 33. Breaking Temporal Coupling
“What is temporal coupling all about?”, you may ask. It's about time.
Time is an often ignored aspect of software architectures. The only time that preoccupies us is the time on the schedule, the time left until we ship—but this is not what we're talking about here. Instead, we are talking about the role of time as a design element of the software itself. There are two aspects of time that are important to us: concurrency (things happening at the same time) and ordering (the relative positions of things in time).
We don't usually approach programming with either of these aspects in mind. When people first sit down to design an architecture or write a program, things tend to be linear. That's the way most people think—do this and then always do that. But thinking this way leads to temporal coupling: coupling in time. Method A must always be called before method B; only one report can be run at a time; you must wait for the screen to redraw before the button click is received. Tick must happen before tock.
This approach is not very flexible, and not very realistic.
We need to allow for concurrency and to think about decoupling any time or order dependencies. In doing so, we can gain flexibility and reduce any time-based dependencies in many areas of development: workflow analysis, architecture, design, and deployment. The result will be systems that are easier to reason about, that potentially respond faster and more reliably.
Looking for Concurrency
On many projects, we need to model and analyze the application workflows as part of the design. We'd like to find out what can happen at the same time, and what must happen in a strict order. One way to do this is to capture the workflow using a notation such as the activity diagram.[46]
Tip 56: Analyze Workflow to Improve Concurrency
An activity diagram consists of a set of actions drawn as rounded boxes. The arrow leaving an action leads to either another action (which can start once the first action completes) or to a thick line called a synchronization bar. Once all the actions leading into a synchronization bar are complete, you can then proceed along any arrows leaving the bar. An action with no arrows leading into it can be started at any time.
You can use activity diagrams to maximize parallelism by identifying activities that could be performed in parallel, but aren't.
For instance, we may be writing the software for a robotic piña colada maker. We're told that the steps are:
|
|
However, a bartender would lose their job if they followed these steps, one by one, in order. Even though they describe these actions serially, many of them could be performed in parallel. We'll use the following activity diagram to capture and reason about potential concurrency.
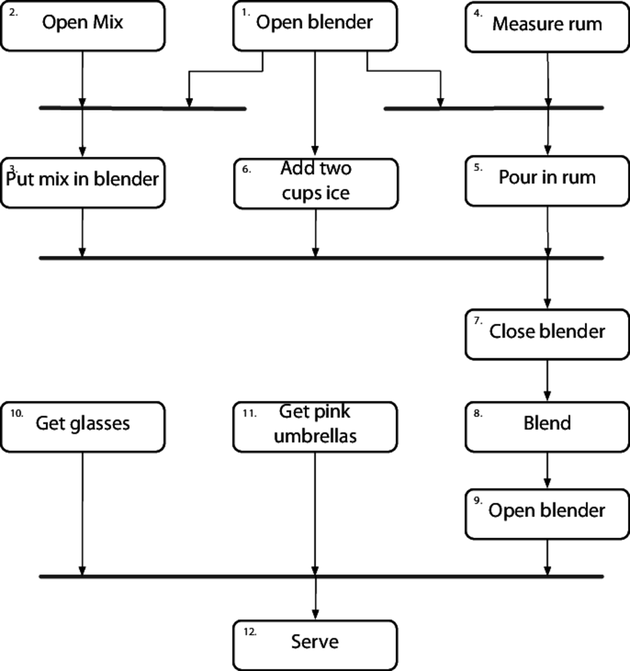
It can be eye-opening to see where the dependencies really exist. In this instance, the top-level tasks (1, 2, 4, 10, and 11) can all happen concurrently, up front. Tasks 3, 5, and 6 can happen in parallel later. If you were in a piña colada-making contest, these optimizations may make all the difference.
Opportunities for Concurrency
Activity diagrams show the potential areas of concurrency, but have nothing to say about whether these areas are worth exploiting. For example, in the piña colada example, a bartender would need five hands to be able to run all the potential initial tasks at once.
And that's where the design part comes in. When we look at the activities, we realize that number 8, liquify, will take a minute. During that time, our bartender can get the glasses and umbrellas (activities 10 and 11) and probably still have time to serve another customer.
And that's what we're looking for when we're designing for concurrency. We're hoping to find activities that take time, but not time in our code. Querying a database, accessing an external service, waiting for user input: all these things would normally stall our program until they complete. And these are all opportunities to do something more productive than the CPU equivalent of twiddling one's thumbs.
Opportunities for Parallelism
Remember the distinction: concurrency is a software mechanism, and parallelism is a hardware concern. If we have multiple processors, either locally or remotely, then if we can split work out among them we can reduce the overall time things take.
The ideal things to split this way are pieces of work that are relatively independent—where each can proceed without waiting for anything from the others. A common pattern is to take a large piece of work, split it into independent chunks, process each in parallel, then combine the results.
An interesting example of this in practice is the way the compiler for the Elixir language works. When it starts, it splits the project it is building into modules, and compiles each in parallel. Sometimes a module depends on another, in which case its compilation pauses until the results of the other module's build become available. When the top-level module completes, it means that all dependencies have been compiled. The result is a speedy compilation that takes advantage of all the cores available.
Identifying Opportunities Is the Easy Part
Back to your applications. We've identified places where it will benefit from concurrency and parallelism. Now for the tricky part: how can we implement it safely. That's the topic of the rest of the chapter.
Related Sections Include
- Topic 10, Orthogonality
- Topic 26, How to Balance Resources
- Topic 28, Decoupling
- Topic 36, Blackboards
Challenges
- How many tasks do you perform in parallel when you get ready for work in the morning? Could you express this in a UML activity diagram? Can you find some way to get ready more quickly by increasing concurrency?
Topic 34. Shared State Is Incorrect State
You're in your favorite diner. You finish your main course, and ask your server if there's any apple pie left. He looks over his shoulder, sees one piece in the display case, and says yes. You order it and sigh contentedly.
Meanwhile, on the other side of the restaurant, another customer asks their server the same question. She also looks, confirms there's a piece, and that customer orders.
One of the customers is going to be disappointed.
Swap the display case for a joint bank account, and turn the waitstaff into point-of-sale devices. You and your partner both decide to buy a new phone at the same time, but there's only enough in the account for one. Someone—the bank, the store, or you—is going to be very unhappy.
Tip 57: Shared State Is Incorrect State
The problem is the shared state. Each server in the restaurant looked into the display case without regard for the other. Each point-of-sale device looked at an account balance without regard for the other.
Nonatomic Updates
Let's look at our diner example as if it were code:
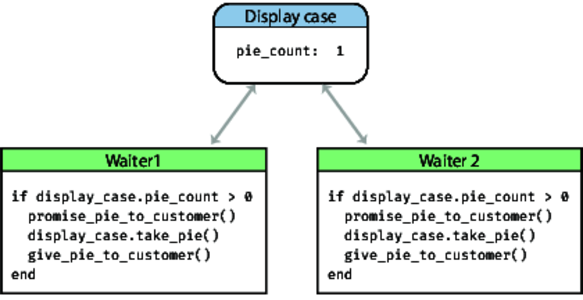
The two waiters operate concurrently (and, in real life, in parallel). Let's look at their code:
if display_case.pie_count > 0 promise_pie_to_customer() display_case.take_pie() give_pie_to_customer() end
Waiter 1 gets the current pie count, and finds that it is one. He promises the pie to the customer. But at that point, waiter 2 runs. She also sees the pie count is one and makes the same promise to her customer. One of the two then grabs the last piece of pie, and the other waiter enters some kind of error state (which probably involves much grovelling).
The problem here is not that two processes can write to the same memory. The problem is that neither process can guarantee that its view of that memory is consistent. Effectively, when a waiter executes display_case.pie_count(), they copy the value from the display case into their own memory. If the value in the display case changes, their memory (which they are using to make decisions) is now out of date.
This is all because the fetching and then updating the pie count is not an atomic operation: the underlying value can change in the middle.
So how can we make it atomic?
Semaphores and Other Forms of Mutual Exclusion
A semaphore is simply a thing that only one person can own at a time. You can create a semaphore and then use it to control access to some other resource. In our example, we could create a semaphore to control access to the pie case, and adopt the convention that anyone who wants to update the pie case contents can only do so if they are holding that semaphore.
Say the diner decides to fix the pie problem with a physical semaphore. They place a plastic Leprechaun on the pie case. Before any waiter can sell a pie, they have to be holding the Leprechaun in their hand. Once their order has been completed (which means delivering the pie to the table) they can return the Leprechaun to its place guarding the treasure of the pies, ready to mediate the next order.
Let's look at this in code. Classically, the operation to grab the semaphore was called P, and the operation to release it was called V.[47] Today we use terms such as lock/unlock, claim/release, and so on.
case_semaphore.lock() if display_case.pie_count > 0 promise_pie_to_customer() display_case.take_pie() give_pie_to_customer() end case_semaphore.unlock()
This code assumes that a semaphore has already been created and stored in the variable case_semaphore.
Let's assume both waiters execute the code at the same time. They both try to lock the semaphore, but only one succeeds. The one that gets the semaphore continues to run as normal. The one that doesn't get the semaphore is suspended until the semaphore becomes available (the waiter waits…). When the first waiter completes the order they unlock the semaphore and the second waiter continues running. They now see there's no pie in the case, and apologize to the customer.
There are some problems with this approach. Probably the most significant is that it only works because everyone who accesses the pie case agrees on the convention of using the semaphore. If someone forgets (that is, some developer writes code that doesn't follow the convention) then we're back in chaos.
Make the Resource Transactional
The current design is poor because it delegates responsibility for protecting access to the pie case to the people who use it. Let's change it to centralize that control. To do this, we have to change the API so that waiters can check the count and also take a slice of pie in a single call:
slice = display_case.get_pie_if_available() if slice give_pie_to_customer() end
To make this work, we need to write a method that runs as part of the display case itself:
def get_pie_if_available() ####
if @slices.size > 0 #
update_sales_data(:pie) #
return @slices.shift #
else # incorrect code!
false #
end #
end ####
This code illustrates a common misconception. We've moved the resource access into a central place, but our method can still be called from multiple concurrent threads, so we still need to protect it with a semaphore:
def get_pie_if_available()
@case_semaphore.lock()
if @slices.size > 0
update_sales_data(:pie)
return @slices.shift
else
false
end
@case_semaphore.unlock()
end
Even this code might not be correct. If update_sales_data raises an exception, the semaphore will never get unlocked, and all future access to the pie case will hang indefinitely. We need to handle this:
def get_pie_if_available()
@case_semaphore.lock()
try {
if @slices.size > 0
update_sales_data(:pie)
return @slices.shift
else
false
end
}
ensure {
@case_semaphore.unlock()
}
end
Because this is such a common mistake, many languages provide libraries that handle this for you:
def get_pie_if_available()
@case_semaphore.protect() {
if @slices.size > 0
update_sales_data(:pie)
return @slices.shift
else
false
end
}
endMultiple Resource Transactions
Our diner just installed an ice cream freezer. If a customer orders pie à la mode, the waiter will need to check that both pie and ice cream are available.
We could change the waiter code to something like:
slice = display_case.get_pie_if_available() scoop = freezer.get_ice_cream_if_available() if slice scoop give_order_to_customer() end
This won't work, though. What happens if we claim a slice of pie, but when we try to get a scoop of ice cream we find out there isn't any? We're now left holding some pie that we can't do anything with (because our customer must have ice cream). And the fact we're holding the pie means it isn't in the case, so it isn't available to some other customer who (being a purist) doesn't want ice cream with it.
We could fix this by adding a method to the case that lets us return a slice of pie. We'll need to add exception handling to ensure we don't keep resources if something fails:
slice = display_case.get_pie_if_available()
if slice
try {
scoop = freezer.get_ice_cream_if_available()
if scoop
try {
give_order_to_customer()
}
rescue {
freezer.give_back(scoop)
}
end
}
rescue {
display_case.give_back(slice)
}
end
Again, this is less than ideal. The code is now really ugly: working out what it actually does is difficult: the business logic is buried in all the housekeeping.
Previously we fixed this by moving the resource handling code into the resource itself. Here, though, we have two resources. Should we put the code in the display case or the freezer?
We think the answer is “no” to both options. The pragmatic approach would be to say that “apple pie à la mode” is its own resource. We'd move this code into a new module, and then the client could just say “get me apple pie with ice cream” and it either succeeds or fails.
Of course, in the real world there are likely to be many composite dishes like this, and you wouldn't want to write new modules for each. Instead, you'd probably want some kind of menu item which contained references to its components, and then have a generic get_menu_item method that does the resource dance with each.
Non-Transactional Updates
A lot of attention is given to shared memory as a source of concurrency problems, but in fact the problems can pop up anywhere where your application code shares mutable resources: files, databases, external services, and so on. Whenever two or more instances of your code can access some resource at the same time, you're looking at a potential problem.
Sometimes, the resource isn't all that obvious. While writing this edition of the book we updated the toolchain to do more work in parallel using threads. This caused the build to fail, but in bizarre ways and random places. A common thread through all the errors was that files or directories could not be found, even though they were really in exactly the right place.
We tracked this down to a couple of places in the code which temporarily changed the current directory. In the nonparallel version, the fact that this code restored the directory back was good enough. But in the parallel version, one thread would change the directory and then, while in that directory, another thread would start running. That thread would expect to be in the original directory, but because the current directory is shared between threads, that wasn't the case.
The nature of this problem prompts another tip:
Tip 58: Random Failures Are Often Concurrency Issues
Other Kinds of Exclusive Access
Most languages have library support for some kind of exclusive access to shared resources. They may call it mutexes (for mutual exclusion), monitors, or semaphores. These are all implemented as libraries.
However, some languages have concurrency support built into the language itself. Rust, for example, enforces the concept of data ownership; only one variable or parameter can hold a reference to any particular piece of mutable data at a time.
You could also argue that functional languages, with their tendency to make all data immutable, make concurrency simpler. However, they still face the same challenges, because at some point they are forced to step into the real, mutable world.
Doctor, It Hurts…
If you take nothing else away from this section, take this: concurrency in a shared resource environment is difficult, and managing it yourself is fraught with challenges.
Which is why we're recommending the punchline to the old joke:
Doctor, it hurts when I do this.
Then don't do that.
The next couple of sections suggest alternative ways of getting the benefits of concurrency without the pain.
Related Sections Include
- Topic 10, Orthogonality
- Topic 28, Decoupling
- Topic 38, Programming by Coincidence
Topic 35. Actors and Processes
Without writers, stories would not be written, Without actors, stories could not be brought to life.
Angie-Marie Delsante
Actors and processes offer interesting ways of implementing concurrency without the burden of synchronizing access to shared memory.
Before we get into them, however, we need to define what we mean. And this is going to sound academic. Never fear, we'll be working through it all in a short while.
-
An actor is an independent virtual processor with its own local (and private) state. Each actor has a mailbox. When a message appears in the mailbox and the actor is idle, it kicks into life and processes the message. When it finishes processing, it processes another message in the mailbox, or, if the mailbox is empty, it goes back to sleep.
When processing a message, an actor can create other actors, send messages to other actors that it knows about, and create a new state that will become the current state when the next message is processed.
-
A process is typically a more general-purpose virtual processor, often implemented by the operating system to facilitate concurrency. Processes can be constrained (by convention) to behave like actors, and that's the type of process we mean here.
Actors Can Only Be Concurrent
There are a few things that you won't find in the definition of actors:
-
There's no single thing that's in control. Nothing schedules what happens next, or orchestrates the transfer of information from the raw data to the final output.
-
The only state in the system is held in messages and in the local state of each actor. Messages cannot be examined except by being read by their recipient, and local state is inaccessible outside the actor.
-
All messages are one way—there's no concept of replying. If you want an actor to return a response, you include your own mailbox address in the message you send it, and it will (eventually) send the response as just another message to that mailbox.
-
An actor processes each message to completion, and only processes one message at a time.
As a result, actors execute concurrently, asynchronously, and share nothing. If you had enough physical processors, you could run an actor on each. If you have a single processor, then some runtime can handle the switching of context between them. Either way, the code running in the actors is the same.
Tip 59: Use Actors For Concurrency Without Shared State
A Simple Actor
Let's implement our diner using actors. In this case, we'll have three (the customer, the waiter, and the pie case).
The overall message flow will look like this:
-
We (as some kind of external, God-like being) tell the customer that they are hungry
-
In response, they'll ask the waiter for pie
-
The waiter will ask the pie case to get some pie to the customer
-
If the pie case has a slice available, it will send it to the customer, and also notify the waiter to add it to the bill
-
If there is no pie, the case tells the waiter, and the waiter apologizes to the customer
We've chosen to implement the code in JavaScript using the Nact library.[48] We've added a little wrapper to this that lets us write actors as simple objects, where the keys are the message types that it receives and the values are functions to run when that particular message is received. (Most actor systems have a similar kind of structure, but the details depend on the host language.)
Let's start with the customer. The customer can receive three messages:
- You're hungry (sent by the external context)
- There's pie on the table (sent by the pie case)
- Sorry, there's no pie (sent by the waiter)
Here's the code:
const customerActor = {
'hungry for pie': (msg, ctx, state) => {
return dispatch(state.waiter,
{ type: "order", customer: ctx.self, wants: 'pie' })
},
'put on table': (msg, ctx, _state) =>
console.log(`${ctx.self.name} sees "${msg.food}" appear on the table`),
'no pie left': (_msg, ctx, _state) =>
console.log(`${ctx.self.name} sulks…`)
}
The interesting case is when we receive a ‘‘hungry for pie'” message, where we then send a message off to the waiter. (We'll see how the customer knows about the waiter actor shortly.)
Here's the waiter's code:
const waiterActor = {
"order": (msg, ctx, state) => {
if (msg.wants == "pie") {
dispatch(state.pieCase,
{ type: "get slice", customer: msg.customer, waiter: ctx.self })
}
else {
console.dir(`Don't know how to order ${msg.wants}`);
}
},
"add to order": (msg, ctx) =>
console.log(`Waiter adds ${msg.food} to ${msg.customer.name}'s order`),
"error": (msg, ctx) => {
dispatch(msg.customer, { type: 'no pie left', msg: msg.msg });
console.log(`\nThe waiter apologizes to ${msg.customer.name}: ${msg.msg}`)
}
};
When it receives the 'order' message from the customer, it checks to see if the request is for pie. If so, it sends a request to the pie case, passing references both to itself and the customer.
The pie case has state: an array of all the slices of pie it holds. (Again, we see how that gets set up shortly.) When it receives a 'get slice' message from the waiter, it sees if it has any slices left. If it does, it passes the slice to the customer, tells the waiter to update the order, and finally returns an updated state, containing one less slice. Here's the code:
const pieCaseActor = {
'get slice': (msg, context, state) => {
if (state.slices.length == 0) {
dispatch(msg.waiter,
{ type: 'error', msg: "no pie left", customer: msg.customer })
return state
}
else {
var slice = state.slices.shift() + " pie slice";
dispatch(msg.customer,
{ type: 'put on table', food: slice });
dispatch(msg.waiter,
{ type: 'add to order', food: slice, customer: msg.customer });
return state;
}
}
}
Although you'll often find that actors are started dynamically by other actors, in our case we'll keep it simple and start our actors manually. We will also pass each some initial state:
- The pie case gets the initial list of pie slices it contains
- We'll give the waiter a reference to the pie case
- We'll give the customers a reference to the waiter
const actorSystem = start();
let pieCase = start_actor(
actorSystem,
'pie-case',
pieCaseActor,
{ slices: ["apple", "peach", "cherry"] });
let waiter = start_actor(
actorSystem,
'waiter',
waiterActor,
{ pieCase: pieCase });let c1 = start_actor(actorSystem, 'customer1',
customerActor, { waiter: waiter });
let c2 = start_actor(actorSystem, 'customer2',
customerActor, { waiter: waiter });
And finally we kick it off. Our customers are greedy. Customer 1 asks for three slices of pie, and customer 2 asks for two:
dispatch(c1, { type: 'hungry for pie', waiter: waiter });
dispatch(c2, { type: 'hungry for pie', waiter: waiter });
dispatch(c1, { type: 'hungry for pie', waiter: waiter });
dispatch(c2, { type: 'hungry for pie', waiter: waiter });
dispatch(c1, { type: 'hungry for pie', waiter: waiter });
sleep(500)
.then(() => {
stop(actorSystem);
})
When we run it, we can see the actors communicating.[49] The order you see may well be different:
$ node index.js customer1 sees "apple pie slice" appear on the table customer2 sees "peach pie slice" appear on the table Waiter adds apple pie slice to customer1's order Waiter adds peach pie slice to customer2's order customer1 sees "cherry pie slice" appear on the table Waiter adds cherry pie slice to customer1's order The waiter apologizes to customer1: no pie left customer1 sulks… The waiter apologizes to customer2: no pie left customer2 sulks…
No Explicit Concurrency
In the actor model, there's no need to write any code to handle concurrency, as there is no shared state. There's also no need to code in explicit end-to-end “do this, do that” logic, as the actors work it out for themselves based on the messages they receive.
There's also no mention of the underlying architecture. This set of components work equally well on a single processor, on multiple cores, or on multiple networked machines.
Erlang Sets the Stage
The Erlang language and runtime are great examples of an actor implementation (even though the inventors of Erlang hadn't read the original Actor's paper). Erlang calls actors processes, but they aren't regular operating system processes. Instead, just like the actors we've been discussing, Erlang processes are lightweight (you can run millions of them on a single machine), and they communicate by sending messages. Each is isolated from the others, so there is no sharing of state.
In addition, the Erlang runtime implements a supervision system, which manages the lifetimes of processes, potentially restarting a process or set of processes in case of failure. And Erlang also offers hot-code loading: you can replace code in a running system without stopping that system. And the Erlang system runs some of the world's most reliable code, often citing nine nines availability.
But Erlang (and it's progeny Elixir) aren't unique—there are actor implementations for most languages. Consider using them for your concurrent implementations.
Related Sections Include
- Topic 28, Decoupling
- Topic 30, Transforming Programming
- Topic 36, Blackboards
Challenges
-
Do you currently have code that uses mutual exclusion to protect shared data. Why not try a prototype of the same code written using actors?
-
The actor code for the diner only supports ordering slices of pie. Extend it to let customers order pie à la mode, with separate agents managing the pie slices and the scoops of ice cream. Arrange things so that it handles the situation where one or the other runs out.
Topic 36. Blackboards
The writing is on the wall…
Daniel 5 (ref)
Consider how detectives might use a blackboard to coordinate and solve a murder investigation. The chief inspector starts off by setting up a large blackboard in the conference room. On it, she writes a single question:
H. Dumpty (Male, Egg): Accident? Murder?
Did Humpty really fall, or was he pushed? Each detective may make contributions to this potential murder mystery by adding facts, statements from witnesses, any forensic evidence that might arise, and so on. As the data accumulates, a detective might notice a connection and post that observation or speculation as well. This process continues, across all shifts, with many different people and agents, until the case is closed. A sample blackboard is shown in the figure.
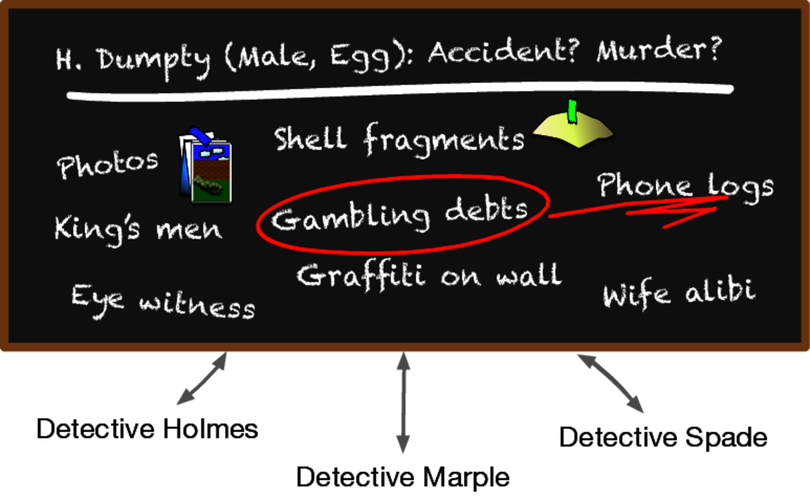
Figure 2. Someone found a connection between Humpty's gambling debts and the phone logs. Perhaps he was getting threatening phone calls.
Some key features of the blackboard approach are:
-
None of the detectives needs to know of the existence of any other detective—they watch the board for new information, and add their findings.
-
The detectives may be trained in different disciplines, may have different levels of education and expertise, and may not even work in the same precinct. They share a desire to solve the case, but that's all.
-
Different detectives may come and go during the course of the process, and may work different shifts.
-
There are no restrictions on what may be placed on the blackboard. It may be pictures, sentences, physical evidence, and so on.
This is a form of laissez faire concurrency. The detectives are independent processes, agents, actors, and so on. Some store facts on the blackboard. Others take facts off the board, maybe combining or processing them, and add more information to the board. Gradually the board helps them come to a conclusion.
Computer-based blackboard systems were originally used in artificial intelligence applications where the problems to be solved were large and complex—speech recognition, knowledge-based reasoning systems, and so on.
One of the first blackboard systems was David Gelernter's Linda. It stored facts as typed tuples. Applications could write new tuples into Linda, and query for existing tuples using a form of pattern matching.
Later came distributed blackboard-like systems such as JavaSpaces and T Spaces. With these systems, you can store active Java objects—not just data—on the blackboard, and retrieve them by partial matching of fields (via templates and wildcards) or by subtypes. For example, suppose you had a type Author, which is a subtype of Person. You could search a blackboard containing Person objects by using an Author template with a lastName value of “Shakespeare.'' You'd get Bill Shakespeare the author, but not Fred Shakespeare the gardener.
These systems never really took off, we believe, in part, because the need for the kind of concurrent cooperative processing hadn't yet developed.
A Blackboard in Action
Suppose we are writing a program to accept and process mortgage or loan applications. The laws that govern this area are odiously complex, with federal, state, and local governments all having their say. The lender must prove they have disclosed certain things, and must ask for certain information—but must not ask certain other questions, and so on, and so on.
Beyond the miasma of applicable law, we also have the following problems to contend with:
-
Responses can arrive in any order. For instance, queries for a credit check or title search may take a substantial amount of time, while items such as name and address may be available immediately.
-
Data gathering may be done by different people, distributed across different offices, in different time zones.
-
Some data gathering may be done automatically by other systems. This data may arrive asynchronously as well.
-
Nonetheless, certain data may still be dependent on other data. For instance, you may not be able to start the title search for a car until you get proof of ownership or insurance.
-
The arrival of new data may raise new questions and policies. Suppose the credit check comes back with a less than glowing report; now you need these five extra forms and perhaps a blood sample.
You can try to handle every possible combination and circumstance using a workflow system. Many such systems exist, but they can be complex and programmer intensive. As regulations change, the workflow must be reorganized: people may have to change their procedures and hard-wired code may have to be rewritten.
A blackboard, in combination with a rules engine that encapsulates the legal requirements, is an elegant solution to the difficulties found here. Order of data arrival is irrelevant: when a fact is posted it can trigger the appropriate rules. Feedback is easily handled as well: the output of any set of rules can post to the blackboard and cause the triggering of yet more applicable rules.
Tip 60: Use Blackboards to Coordinate Workflow
Messaging Systems Can Be Like Blackboards
As we're writing this second edition, many applications are constructed using small, decoupled services, all communicating via some form of messaging system. These messaging systems (such as Kafka and NATS) do far more than simply send data from A to B. In particular, they offer persistence (in the form of an event log) and the ability to retrieve messages through a form of pattern matching. This means you can use them both as a blackboard system and/or as a platform on which you can run a bunch of actors.
But It's Not That Simple…
The actor and/or blackboard and/or microservice approach to architecture removes a whole class of potential concurrency problems from your applications. But that benefit comes at a cost. These approaches are harder to reason about, because a lot of the action is indirect. You'll find it helps to keep a central repository of message formats and/or APIs, particularly if the repository can generate the code and documentation for you. You'll also need good tooling to be able to trace messages and facts as they progress through the system. (A useful technique is to add a unique trace id when a particular business function is initiated and then propagate it to all the actors involved. You'll then be able to reconstruct what happens from the log files.)
Finally, these kinds of system can be more troublesome to deploy and manage, as there are more moving parts. To some extent this is offset by the fact that the system is more granular, and can be updated by replacing individual actors, and not the whole system.
Related Sections Include
- Topic 28, Decoupling
- Topic 29, Juggling the Real World
- Topic 33, Breaking Temporal Coupling
- Topic 35, Actors and Processes
Exercises
Exercise 24 (possible answer)
Would a blackboard-style system be appropriate for the following applications? Why, or why not?
Image processing. You'd like to have a number of parallel processes grab chunks of an image, process them, and put the completed chunk back.
Group calendaring. You've got people scattered across the globe, in different time zones, and speaking different languages, trying to schedule a meeting.
Network monitoring tool. The system gathers performance statistics and collects trouble reports, which agents use to look for trouble in the system.
Challenges
- Do you use blackboard systems in the real world—the message board by the refrigerator, or the big whiteboard at work? What makes them effective? Are messages ever posted with a consistent format? Does it matter?
[46]Although UML has gradually faded, many of its individual diagrams still exist in one form or another, including the very useful activity diagram. For more information on all of the UML diagram types, see UML Distilled: A Brief Guide to the Standard Object Modeling Language [Fow04].
[47]The names P and V come from the initial letters of Dutch words. However there is some discussion about exactly which words. The inventor of the technique, Edsger Dijkstra, has suggested both passering and prolaag for P, and vrijgave and possibly verhogen for V.
[48]https://github.com/ncthbrt/nact
[49]In order to run this code you'll also need our wrapper functions, which are not shown here. You can download them from https://media.pragprog.com/titles/tpp20/code/concurrency/actors/index.js