Chapter 5 - Bend, or Break
Life doesn't stand still. Neither can the code that we write. In order to keep up with today's near-frantic pace of change, we need to make every effort to write code that's as loose—as flexible—as possible. Otherwise we may find our code quickly becoming outdated, or too brittle to fix, and may ultimately be left behind in the mad dash toward the future.
Back in Topic 11, Reversibility we talked about the perils of irreversible decisions. In this chapter, we'll tell you how to make reversible decisions, so your code can stay flexible and adaptable in the face of an uncertain world.
First we look at coupling—the dependencies between bits of code. Topic 28, Decoupling shows how to keep separate concepts separate, decreasing coupling.
Next, we'll look at different techniques you can use when Topic 29, Juggling the Real World. We'll examine four different strategies to help manage and react to events—a critical aspect of modern software applications.
Traditional procedural and object-oriented code might be too tightly coupled for your purposes. In Topic 30, Transforming Programming, we'll take advantage of the more flexible and clearer style offered by function pipelines, even if your language doesn't support them directly.
Common object-oriented style can tempt you with another trap. Don't fall for it, or you'll end up paying a hefty Topic 31, Inheritance Tax. We'll explore better alternatives to keep your code flexible and easier to change.
And of course a good way to stay flexible is to write less code. Changing code leaves you open to the possibility of introducing new bugs. Topic 32, Configuration will explain how to move details out of the code completely, where they can be changed more safely and easily.
All these techniques will help you write code that bends and doesn't break.
Topic 28. Decoupling
When we try to pick out anything by itself, we find it hitched to everything else in the Universe.
John Muir, My First Summer in the Sierra
In Topic 8, The Essence of Good Design we claim that using good design principles will make the code you write easy to change. Coupling is the enemy of change, because it links together things that must change in parallel. This makes change more difficult: either you spend time tracking down all the parts that need changing, or you spend time wondering why things broke when you changed “just one thing” and not the other things to which it was coupled.
When you are designing something you want to be rigid, a bridge or a tower perhaps, you couple the components together:

The links work together to make the structure rigid.
Compare that with something like this:

Here there's no structural rigidity: individual links can change and others just accommodate it.
When you're designing bridges, you want them to hold their shape; you need them to be rigid. But when you're designing software that you'll want to change, you want exactly the opposite: you want it to be flexible. And to be flexible, individual components should be coupled to as few other components as possible.
And, to make matters worse, coupling is transitive: if A is coupled to B and C, and B is coupled to M and N, and C to X and Y, then A is actually coupled to B, C, M, N, X, and Y.
This means there's a simple principle you should follow:
Tip 44: Decoupled Code Is Easier to Change
Given that we don't normally code using steel beams and rivets, just what does it mean to decouple code? In this section we'll talk about:
- Train wrecks—chains of method calls
- Globalization—the dangers of static things
- Inheritance—why subclassing is dangerous
To some extent this list is artificial: coupling can occur just about any time two pieces of code share something, so as you read what follows keep an eye out for the underlying patterns so you can apply them to your code. And keep a lookout for some of the symptoms of coupling:
-
Wacky dependencies between unrelated modules or libraries.
-
“Simple” changes to one module that propagate through unrelated modules in the system or break stuff elsewhere in the system.
-
Developers who are afraid to change code because they aren't sure what might be affected.
-
Meetings where everyone has to attend because no one is sure who will be affected by a change.
Train Wrecks
We've all seen (and probably written) code like this:
public void applyDiscount(customer, order_id, discount) {
totals = customer
.orders
.find(order_id)
.getTotals();
totals.grandTotal = totals.grandTotal - discount;
totals.discount = discount;
}
We're getting a reference to some orders from a customer object, using that to find a particular order, and then getting the set of totals for the order. Using those totals, we subtract the discount from the order grand total and also update them with that discount.
This chunk of code is traversing five levels of abstraction, from customer to total amounts. Ultimately our top-level code has to know that a customer object exposes orders, that the orders have a find method that takes an order id and returns an order, and that the order object has a totals object which has getters and setters for grand totals and discounts. That's a lot of implicit knowledge. But worse, that's a lot of things that cannot change in the future if this code is to continue to work. All the cars in a train are coupled together, as are all the methods and attributes in a train wreck.
Let's imagine that the business decides that no order can have a discount of more than 40%. Where would we put the code that enforces that rule?
You might say it belongs in the applyDiscount function we just wrote. That's certainly part of the answer. But with the code the way it is now, you can't know that this is the whole answer. Any piece of code, anywhere, could set fields in the totals object, and if the maintainer of that code didn't get the memo, it wouldn't be checking against the new policy.
One way to look at this is to think about responsibilities. Surely the totals object should be responsible for managing the totals. And yet it isn't: it's really just a container for a bunch of fields that anyone can query and update.
The fix for that is to apply something we call:
Tip 45: Tell, Don't Ask
This principle says that you shouldn't make decisions based on the internal state of an object and then update that object. Doing so totally destroys the benefits of encapsulation and, in doing so, spreads the knowledge of the implementation throughout the code. So the first fix for our train wreck is to delegate the discounting to the total object:
public void applyDiscount(customer, order_id, discount) {
customer
.orders
.find(order_id)
.getTotals()
.applyDiscount(discount);
}
We have the same kind of tell-don't-ask (TDA) issue with the customer object and its orders: we shouldn't fetch its list of orders and search them. We should instead get the order we want directly from the customer:
public void applyDiscount(customer, order_id, discount) {
customer
.findOrder(order_id)
.getTotals()
.applyDiscount(discount);
}
The same thing applies to our order object and its totals. Why should the outside world have to know that the implementation of an order uses a separate object to store its totals?
public void applyDiscount(customer, order_id, discount) {
customer
.findOrder(order_id)
.applyDiscount(discount);
}
And this is where we'd probably stop.
At this point you might be thinking that TDA would make us add an applyDiscountToOrder(order_id) method to customers. And, if followed slavishly, it would.
But TDA is not a law of nature; it's just a pattern to help us recognize problems. In this case, we're comfortable exposing the fact that a customer has orders, and that we can find one of those orders by asking the customer object for it. This is a pragmatic decision.
In every application there are certain top-level concepts that are universal. In this application, those concepts include customers and orders. It makes no sense to hide orders totally inside customer objects: they have an existence of their own. So we have no problem creating APIs that expose order objects.
The Law of Demeter
People often talk about something called the Law of Demeter, or LoD, in relation to coupling. The LoD is a set of guidelines[37] written in the late '80s by Ian Holland. He created them to help developers on the Demeter Project keep their functions cleaner and decoupled.
The LoD says that a method defined in a class C should only call:
- Other instance methods in C
- Its parameters
- Methods in objects that it creates, both on the stack and in the heap
- Global variables
In the first edition of this book we spent some time describing the LoD. In the intervening 20 years the bloom has faded on that particular rose. We now don't like the “global variable” clause (for reasons we'll go into in the next section). We also discovered that it's difficult to use this in practice: it's a little like having to parse a legal document whenever you call a method.
However, the principle is still sound. We just recommend a somewhat simpler way of expressing almost the same thing:
Tip 46: Don't Chain Method Calls
Try not to have more than one “.” when you access something. And access something also covers cases where you use intermediate variables, as in the following code:
# This is pretty poor style amount = customer.orders.last().totals().amount; # and so is this… orders = customer.orders; last = orders.last(); totals = last.totals(); amount = totals.amount;
There's a big exception to the one-dot rule: the rule doesn't apply if the things you're chaining are really, really unlikely to change. In practice, anything in your application should be considered likely to change. Anything in a third-party library should be considered volatile, particularly if the maintainers of that library are known to change APIs between releases. Libraries that come with the language, however, are probably pretty stable, and so we'd be happy with code such as:
people
.sort_by {|person| person.age }
.first(10)
.map {| person | person.name }
That Ruby code worked when we wrote the first edition, 20 years ago, and will likely still work when we enter the home for old programmers (any day now…).
Chains and Pipelines
In Topic 30, Transforming Programming we talk about composing functions into pipelines. These pipelines transform data, passing it from one function to the next. This is not the same as a train wreck of method calls, as we are not relying on hidden implementation details.
That's not to say that pipelines don't introduce some coupling: they do. The format of the data returned by one function in a pipeline must be compatible with the format accepted by the next.
Our experience is that this form of coupling is far less a barrier to changing the code than the form introduced by train wrecks.
The Evils of Globalization
Globally accessible data is an insidious source of coupling between application components. Each piece of global data acts as if every method in your application suddenly gained an additional parameter: after all, that global data is available inside every method.
Globals couple code for many reasons. The most obvious is that a change to the implementation of the global potentially affects all the code in the system. In practice, of course, the impact is fairly limited; the problem really comes down to knowing that you've found every place you need to change.
Global data also creates coupling when it comes to teasing your code apart.
Much has been made of the benefits of code reuse. Our experience has been that reuse should probably not be a primary concern when creating code, but the thinking that goes into making code reusable should be part of your coding routine. When you make code reusable, you give it clean interfaces, decoupling it from the rest of your code. This allows you to extract a method or module without dragging everything else along with it. And if your code uses global data, then it becomes difficult to split it out from the rest.
You'll see this problem when you're writing unit tests for code that uses global data. You'll find yourself writing a bunch of setup code to create a global environment just to allow your test to run.
Tip 47: Avoid Global Data
Global Data Includes Singletons
In the previous section we were careful to talk about global data and not global variables. That's because people often tell us “Look! No global variables. I wrapped it all as instance data in a singleton object or global module.”
Try again, Skippy. If all you have is a singleton with a bunch of exported instance variables, then it's still just global data. It just has a longer name.
So then folks take this singleton and hide all the data behind methods. Instead of coding Config.log_level they now say Config.log_level() or Config.getLogLevel(). This is better, because it means that your global data has a bit of intelligence behind it. If you decide to change the representation of log levels, you can maintain compatibility by mapping between the new and old in the Config API. But you still have only the one set of configuration data.
Global Data Includes External Resources
Any mutable external resource is global data. If your application uses a database, datastore, file system, service API, and so on, it risks falling into the globalization trap. Again, the solution is to make sure you always wrap these resources behind code that you control.
Tip 48: If It's Important Enough to Be Global, Wrap It in an API
Inheritance Adds Coupling
The misuse of subclassing, where a class inherits state and behavior from another class, is so important that we discuss it in its own section, Topic 31, Inheritance Tax.
Again, It's All About Change
Coupled code is hard to change: alterations in one place can have secondary effects elsewhere in the code, and often in hard-to-find places that only come to light a month later in production.
Keeping your code shy: having it only deal with things it directly knows about, will help keep your applications decoupled, and that will make them more amenable to change.
Related Sections Include
- Topic 8, The Essence of Good Design
- Topic 9, DRY—The Evils of Duplication
- Topic 10, Orthogonality
- Topic 11, Reversibility
- Topic 29, Juggling the Real World
- Topic 30, Transforming Programming
- Topic 31, Inheritance Tax
- Topic 32, Configuration
- Topic 33, Breaking Temporal Coupling
- Topic 34, Shared State Is Incorrect State
- Topic 35, Actors and Processes
- Topic 36, Blackboards
- We discuss Tell, Don't Ask in our 2003 Software Construction article The Art of Enbugging.[38]
Topic 29. Juggling the Real World
Things don't just happen; they are made to happen.
John F. Kennedy
In the old days, when your authors still had their boyish good looks, computers were not particularly flexible. We'd typically organize the way we interacted with them based on their limitations.
Today, we expect more: computers have to integrate into our world, not the other way around. And our world is messy: things are constantly happening, stuff gets moved around, we change our minds, …. And the applications we write somehow have to work out what to do.
This section is all about writing these responsive applications.
We'll start off with the concept of an event.
Events
An event represents the availability of information. It might come from the outside world: a user clicking a button, or a stock quote update. It might be internal: the result of a calculation is ready, a search finishes. It can even be something as trivial as fetching the next element in a list.
Whatever the source, if we write applications that respond to events, and adjust what they do based on those events, those applications will work better in the real world. Their users will find them to be more interactive, and the applications themselves will make better use of resources.
But how can we write these kinds of applications? Without some kind of strategy, we'll quickly find ourselves confused, and our applications will be a mess of tightly coupled code.
Let's look at four strategies that help.
- Finite State Machines
- The Observer Pattern
- Publish/Subscribe
- Reactive Programming and Streams
Finite State Machines
Dave finds that he writes code using a Finite State Machine (FSM) just about every week. Quite often, the FSM implementation will be just a couple of lines of code, but those few lines help untangle a whole lot of potential mess.
Using an FSM is trivially easy, and yet many developers shy away from them. There seems to be a belief that they are difficult, or that they only apply if you're working with hardware, or that you need to use some hard-to-understand library. None of these are true.
The Anatomy of a Pragmatic FSM
A state machine is basically just a specification of how to handle events. It consists of a set of states, one of which is the current state. For each state, we list the events that are significant to that state. For each of those events, we define the new current state of the system.
For example, we may be receiving multipart messages from a websocket. The first message is a header. This is followed by any number of data messages, followed by a trailing message. This could be represented as an FSM like this:
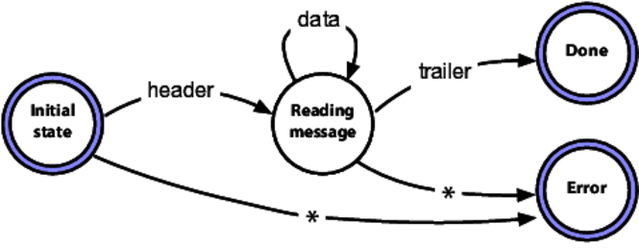
We start in the “Initial state.” If we receive a header message, we transition to the “Reading message” state. If we receive anything else while we're in the initial state (the line labeled with an asterisk) we transition to the “Error” state and we're done.
While we're in the “Reading message” state, we can accept either data messages, in which case we continue reading in the same state, or we can accept a trailer message, which transitions us to the “Done” state. Anything else causes a transition to the error state.
The neat thing about FSMs is that we can express them purely as data. Here's a table representing our message parser:
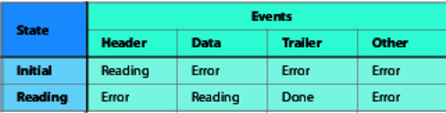
The rows in the table represent the states. To find out what to do when an event occurs, look up the row for the current state, scan along for the column representing the event, the contents of that cell are the new state.
The code that handles it is equally simple:
TRANSITIONS = {
initial: {header: :reading},
reading: {data: :reading, trailer: :done},
}
state = :initial
while state != :done state != :error
msg = get_next_message()
state = TRANSITIONS[state][msg.msg_type] || :error
end
The code that implements the transitions between states is on line 10. It indexes the transition table using the current state, and then indexes the transitions for that state using the message type. If there is no matching new state, it sets the state to :error.
Adding Actions
A pure FSM, such as the one we were just looking at, is an event stream parser. Its only output is the final state. We can beef it up by adding actions that are triggered on certain transitions.
For example, we might need to extract all of the strings in a source file. A string is text between quotes, but a backslash in a string escapes the next character, so "Ignore \"quotes\"" is a single string. Here's an FSM that does this:
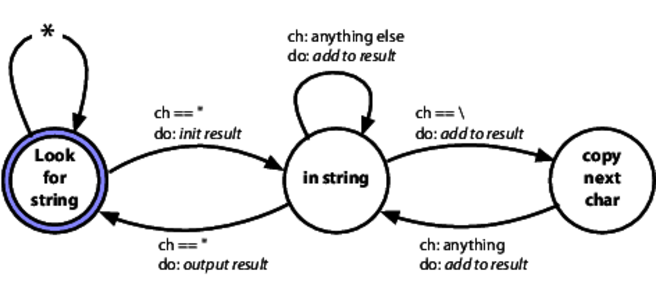
This time, each transition has two labels. The top one is the event that triggers it, and the bottom one is the action to take as we move between states.
We'll express this in a table, as we did last time. However, in this case each entry in the table is a two-element list containing the next state and the name of an action:
TRANSITIONS = {
# current new state action to take
#---------------------------------------------------------
look_for_string: {
'"' => [ :in_string, :start_new_string ],
:default => [ :look_for_string, :ignore ],
},
in_string: {
'"' => [ :look_for_string, :finish_current_string ],
'\\' => [ :copy_next_char, :add_current_to_string ],
:default => [ :in_string, :add_current_to_string ],
},
copy_next_char: {
:default => [ :in_string, :add_current_to_string ],
},
}
We've also added the ability to specify a default transition, taken if the event doesn't match any of the other transitions for this state.
Now let's look at the code:
state = :look_for_string
result = []
while ch = STDIN.getc
state, action = TRANSITIONS[state][ch] || TRANSITIONS[state][:default]
case action
when :ignore
when :start_new_string
result = []
when :add_current_to_string
result
This is similar to the previous example, in that we loop through the events (the characters in the input), triggering transitions. But it does more than the previous code. The result of each transition is both a new state and the name of an action. We use the action name to select the code to run before we go back around the loop.
This code is very basic, but it gets the job done. There are many other variants: the transition table could use anonymous functions or function pointers for the actions, you could wrap the code that implements the state machine in a separate class, with its own state, and so on.
There's nothing to say that you have to process all the state transitions at the same time. If you're going through the steps to sign up a user on your app, there's likely to be a number of transitions as they enter their details, validate their email, agree to the 107 different legislated warnings that online apps must now give, and so on. Keeping the state in external storage, and using it to drive a state machine, is a great way to handle these kind of workflow requirements.
State Machines Are a Start
State machines are underused by developers, and we'd like to encourage you to look for opportunities to apply them. But they don't solve all the problems associated with events. So let's move on to some other ways of looking at the problems of juggling events.
The Observer Pattern
In the observer pattern we have a source of events, called the observable and a list of clients, the observers, who are interested in those events.
An observer registers its interest with the observable, typically by passing a reference to a function to be called. Subsequently, when the event occurs, the observable iterates down its list of observers and calls the function that each passed it. The event is given as a parameter to that call.
Here's a simple example in Ruby. The Terminator module is used to terminate the application. Before it does so, however, it notifies all its observers that the application is going to exit.[39] They might use this notification to tidy up temporary resources, commit data, and so on:
module Terminator
CALLBACKS = []
def self.register(callback)
CALLBACKS $ ruby event/observer.rb callback 1 sees 99 callback 2 sees 99
There's not much code involved in creating an observable: you push a function reference onto a list, and then call those functions when the event occurs. This is a good example of when not to use a library.
The observer/observable pattern has been used for decades, and it has served us well. It is particularly prevalent in user interface systems, where the callbacks are used to inform the application that some interaction has occurred.
But the observer pattern has a problem: because each of the observers has to register with the observable, it introduces coupling. In addition, because in the typical implementation the callbacks are handled inline by the observable, synchronously, it can introduce performance bottlenecks.
This is solved by the next strategy, Publish/Subscribe.
Publish/Subscribe
Publish/Subscribe (pubsub) generalizes the observer pattern, at the same time solving the problems of coupling and performance.
In the pubsub model, we have publishers and subscribers. These are connected via channels. The channels are implemented in a separate body of code: sometimes a library, sometimes a process, and sometimes a distributed infrastructure. All this implementation detail is hidden from your code.
Every channel has a name. Subscribers register interest in one or more of these named channels, and publishers write events to them. Unlike the observer pattern, the communication between the publisher and subscriber is handled outside your code, and is potentially asynchronous.
Although you could implement a very basic pubsub system yourself, you probably don't want to. Most cloud service providers have pubsub offerings, allowing you to connect applications around the world. Every popular language will have at least one pubsub library.
Pubsub is a good technology for decoupling the handling of asynchronous events. It allows code to be added and replaced, potentially while the application is running, without altering existing code. The downside is that it can be hard to see what is going on in a system that uses pubsub heavily: you can't look at a publisher and immediately see which subscribers are involved with a particular message.
Compared to the observer pattern, pubsub is a great example of reducing coupling by abstracting up through a shared interface (the channel). However, it is still basically just a message passing system. Creating systems that respond to combinations of events will need more than this, so let's look at ways we can add a time dimension to event processing.
Reactive Programming, Streams, and Events
If you've ever used a spreadsheet, then you'll be familiar with reactive programming. If a cell contains a formula which refers to a second cell, then updating that second cell causes the first to update as well. The values react as the values they use change.
There are many frameworks that can help with this kind of data-level reactivity: in the realm of the browser React and Vue.js are current favorites (but, this being JavaScript, this information will be out-of-date before this book is even printed).
It's clear that events can also be used to trigger reactions in code, but it isn't necessarily easy to plumb them in. That's where streams come in.
Streams let us treat events as if they were a collection of data. It's as if we had a list of events, which got longer when new events arrive. The beauty of that is that we can treat streams just like any other collection: we can manipulate, combine, filter, and do all the other data-ish things we know so well. We can even combine event streams and regular collections. And streams can be asynchronous, which means your code gets the opportunity to respond to events as they arrive.
The current de facto baseline for reactive event handling is defined on the site http://reactivex.io, which defines a language-agnostic set of principles and documents some common implementations. Here we'll use the RxJs library for JavaScript.
Our first example takes two streams and zips them together: the result is a new stream where each element contains one item from the first input stream and one item from the other. In this case, the first stream is simply a list of five animal names. The second stream is more interesting: it's an interval timer which generates an event every 500ms. Because the streams are zipped together, a result is only generated when data is available on both, and so our result stream only emits a value every half second:
import * as Observable from 'rxjs'
import { logValues } from "../rxcommon/logger.js"
let animals = Observable.of("ant", "bee", "cat", "dog", "elk")
let ticker = Observable.interval(500)
let combined = Observable.zip(animals, ticker)
combined.subscribe(next => logValues(JSON.stringify(next)))
This code uses a simple logging function[40] which adds items to a list in the browser window. Each item is timestamped with the time in milliseconds since the program started to run. Here's what it shows for our code:
![An output is shown different timestamps. The output at 502 milliseconds is ["ant", 0]; The output at 1002 milliseconds is ["bee", 1]; The output at 1502 milliseconds is ["cat", 2]; The output at 2002 milliseconds is ["dog", 3]; The output at 2502 milliseconds is ["elk", 4];](/images/the-pragmatic-programmer/events_rxjs_0.png)
Notice the timestamps: we're getting one event from the stream every 500ms. Each event contains a serial number (created by the interval observable) and the name of the next animal from the list. Watching it live in a browser, the log lines appear at every half second.
Event streams are normally populated as events occur, which implies that the observables that populate them can run in parallel. Here's an example that fetches information about users from a remote site. For this we'll use https://reqres.in, a public site that provides an open REST interface. As part of its API, we can fetch data on a particular (fake) user by performing a GET request to users/«id». Our code fetches the users with the IDs 3, 2, and 1:
import * as Observable from 'rxjs'
import { mergeMap } from 'rxjs/operators'
import { ajax } from 'rxjs/ajax'
import { logValues } from "../rxcommon/logger.js"
let users = Observable.of(3, 2, 1)
let result = users.pipe(
mergeMap((user) => ajax.getJSON(`https://reqres.in/api/users/${user}`))
)
result.subscribe(
resp => logValues(JSON.stringify(resp.data)),
err => console.error(JSON.stringify(err))
)
The internal details of the code are not too important. What's exciting is the result, shown in the following screenshot:

Look at the timestamps: the three requests, or three separate streams, were processed in parallel, The first to come back, for id 2, took 82ms, and the next two came back 50 and 51ms later.
Streams of Events Are Asynchronous Collections
In the previous example, our list of user IDs (in the observable users) was static. But it doesn't have to be. Perhaps we want to collect this information when people log in to our site. All we have to do is to generate an observable event containing their user ID when their session is created, and use that observable instead of the static one. We'd then be fetching details about the users as we received these IDs, and presumably storing them somewhere.
This is a very powerful abstraction: we no longer need to think about time as being something we have to manage. Event streams unify synchronous and asynchronous processing behind a common, convenient API.
Events Are Ubiquitous
Events are everywhere. Some are obvious: a button click, a timer expiring. Other are less so: someone logging in, a line in a file matching a pattern. But whatever their source, code that's crafted around events can be more responsive and better decoupled than its more linear counterpart.
Related Sections Include
- Topic 28, Decoupling
- Topic 36, Blackboards
Exercises
Exercise 19 (possible answer)
In the FSM section we mentioned that you could move the generic state machine implementation into its own class. That class would probably be initialized by passing in a table of transitions and an initial state.
Try implementing the string extractor that way.
Exercise 20 (possible answer)
Which of these technologies (perhaps in combination) would be a good fit for the following situations:
-
If you receive three network interface down events within five minutes, notify the operations staff.
-
If it is after sunset, and there is motion detected at the bottom of the stairs followed by motion detected at the top of the stairs, turn on the upstairs lights.
-
You want to notify various reporting systems that an order was completed.
-
In order to determine whether a customer qualifies for a car loan, the application needs to send requests to three backend services and wait for the responses.
Topic 30. Transforming Programming
If you can't describe what you are doing as a process, you don't know what you're doing.
W. Edwards Deming, (attr)
All programs transform data, converting an input into an output. And yet when we think about design, we rarely think about creating transformations. Instead we worry about classes and modules, data structures and algorithms, languages and frameworks.
We think that this focus on code often misses the point: we need to get back to thinking of programs as being something that transforms inputs into outputs. When we do, many of the details we previously worried about just evaporate. The structure becomes clearer, the error handling more consistent, and the coupling drops way down.
To start our investigation, let's take the time machine back to the 1970s and ask a Unix programmer to write us a program that lists the five longest files in a directory tree, where longest means “having the largest number of lines.”
You might expect them to reach for an editor and start typing in C. But they wouldn't, because they are thinking about this in terms of what we have (a directory tree) and what we want (a list of files). Then they'd go to a terminal and type something like:
$ find . -type f | xargs wc -l | sort -n | tail -5
This is a series of transformations:
- find . -type f
-
Write a list of all the files (-type f) in or below the current directory (.) to standard output.
- xargs wc -l
-
Read lines from standard input and arrange for them all to be passed as arguments to the command wc -l. The wc program with the -l option counts the number of lines in each of its arguments and writes each result as “count filename” to standard output.
- sort -n
-
Sort standard input assuming each line starts with a number (-n), writing the result to standard output.
- tail -5
-
Read standard input and write just the last five lines to standard output.
Run this in our book's directory and we get
470 ./test_to_build.pml 487 ./dbc.pml 719 ./domain_languages.pml 727 ./dry.pml 9561 total
That last line is the total number of lines in all the files (not just those shown), because that's what wc does. We can strip it off by requesting one more line from tail, and then ignoring the last line:
$ find . -type f | xargs wc -l | sort -n | tail -6 | head -5
470 ./debug.pml
470 ./test_to_build.pml
487 ./dbc.pml
719 ./domain_languages.pml
727 ./dry.pml
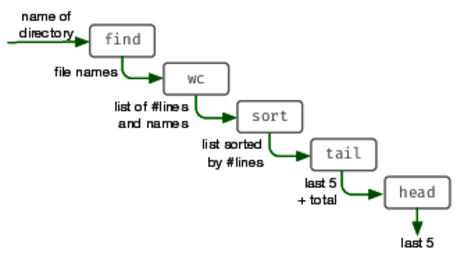
Figure 1. The find pipeline as a series of transformations
Let's look at this in terms of the data that flows between the individual steps. Our original requirement, “top 5 files in terms of lines,” becomes a series of transformations (also show in the figure).
directory name
→ list of files
→ list with line numbers
→ sorted list
→ highest five + total
→ highest five
It's almost like an industrial assembly line: feed raw data in one end and the finished product (information) comes out the other.
And we like to think about all code this way.
Tip 49: Programming Is About Code, But Programs Are About Data
Finding Transformations
Sometimes the easiest way to find the transformations is to start with the requirement and determine its inputs and outputs. Now you've defined the function representing the overall program. You can then find steps that lead you from input to output. This is a top-down approach.
For example, you want to create a website for folks playing word games that finds all the words that can be made from a set of letters. Your input here is a set of letters, and your output is a list of three-letter words, four-letter words, and so on:
| "lvyin" | is transformed to → |
3 => ivy, lin, nil, yin |
(Yes, they are all words, at least according to the macOS dictionary.)
The trick behind the overall application is simple: we have a dictionary which groups words by a signature, chosen so that all words containing the same letters will have the same signature. The simplest signature function is just the sorted list of letters in the word. We can then look up an input string by generating a signature for it, and then seeing which words (if any) in the dictionary have that same signature.
Thus the anagram finder breaks down into four separate transformations:
| Step | Transformation | Sample data |
|---|---|---|
| Step 0: | Initial input | "ylvin" |
| Step 1: | All combinations of three or more letters | vin, viy, vil, vny, vnl, vyl, iny, inl, iyl, nyl, viny, vinl, viyl, vnyl, inyl, vinyl |
| Step 2: | Signatures of the combinations | inv, ivy, ilv, nvy, lnv, lvy, iny, iln, ily, lny, invy, ilnv, ilvy, lnvy, ilny, ilnvy |
| Step 3: | List of all dictionary words which match any of the signatures | ivy, yin, nil, lin, viny, liny, inly, vinyl |
| Step 4: | Words grouped by length |
3 => ivy, lin, nil, yin |
Transformations All the Way Down
Let's start by looking at step 1, which takes a word and creates a list of all combinations of three or more letters. This step can itself be expressed as a list of transformations:
| Step | Transformation | Sample data |
|---|---|---|
| Step 1.0: | Initial input | "vinyl" |
| Step 1.1: | Convert to characters | v, i, n, y, l |
| Step 1.2: | Get all subsets | [], [v], [i], … [v,i], [v,n], [v,y], … [v,i,n], [v,i,y], … [v,n,y,l], [i,n,y,l], [v,i,n,y,l] |
| Step 1.3: | Only those longer than three characters | [v,i,n], [v,i,y], … [i,n,y,l], [v,i,n,y,l] |
| Step 1.4: | Convert back to strings | [vin,viy, … inyl,vinyl] |
We've now reached the point where we can easily implement each transformation in code (using Elixir in this case):
defp all_subsets_longer_than_three_characters(word) do word |> String.codepoints() |> Comb.subsets() |> Stream.filter(fn subset -> length(subset) >= 3 end) |> Stream.map((1)) end
What's with the |> Operator?
Elixir, along with many other functional languages, has a pipeline operator, sometimes called a forward pipe or just a pipe.[41] All it does is take the value on its left and insert it as the first parameter of the function on its right, so
"vinyl" |> String.codepoints |> Comb.subsets()
is the same as writing
Comb.subsets(String.codepoints("vinyl"))
(Other languages may inject this piped value as the last parameter of the next function—it largely depends on the style of the built-in libraries.)
You might think that this is just syntactic sugar. But in a very real way the pipeline operator is a revolutionary opportunity to think differently. Using a pipeline means that you're automatically thinking in terms of transforming data; each time you see |> you're actually seeing a place where data is flowing between one transformation and the next.
Many languages have something similar: Elm, and F# have |>, Clojure has -> and ->> (which work a little differently), R has %>%. Haskell both has pipe operators and makes it easy to declare new ones. As we write this, there's talk of adding |> to JavaScript.
If your current language supports something similar, you're in luck. If it doesn't, see Language X Doesn't Have Pipelines.
Anyway, back to the code.
Keep on Transforming…
Now look at Step 2 of the main program, where we convert the subsets into signatures. Again, it's a simple transformation—a list of subsets becomes a list of signatures:
| Step | Transformation | Sample data |
|---|---|---|
| Step 2.0: | initial input | vin, viy, … inyl, vinyl |
| Step 2.1: | convert to signatures | inv, ivy … ilny, inlvy |
The Elixir code in the following listing is just as simple:
defp as_unique_signatures(subsets) do subsets |> Stream.map(/1) end
Now we transform that list of signatures: each signature gets mapped to the list of known words with the same signature, or nil if there are no such words. We then have to remove the nils and flatten the nested lists into a single level:
defp find_in_dictionary(signatures) do signatures |> Stream.map(/1) |> Stream.reject(/1) |> Stream.concat((1)) end
Step 4, grouping the words by length, is another simple transformation, converting our list into a map where the keys are the lengths, and the values are all words with that length:
defp group_by_length(words) do words |> Enum.sort() |> Enum.group_by(/1) end
Putting It All Together
We've written each of the individual transformations. Now it's time to string them all together into our main function:
def anagrams_in(word) do
word
|> all_subsets_longer_than_three_characters()
|> as_unique_signatures()
|> find_in_dictionary()
|> group_by_length()
end
Does it work? Let's try it:
iex(1)> Anagrams.anagrams_in "lyvin"
%{
3 => ["ivy", "lin", "nil", "yin"],
4 => ["inly", "liny", "viny"],
5 => ["vinyl"]
}Why Is This So Great?
Let's look at the body of the main function again:
word |> all_subsets_longer_than_three_characters() |> as_unique_signatures() |> find_in_dictionary() |> group_by_length()
It's simply a chain of the transformations needed to meet our requirement, each taking input from the previous transformation and passing output to the next. That comes about as close to literate code as you can get.
But there's something deeper, too. If your background is object-oriented programming, then your reflexes demand that you hide data, encapsulating it inside objects. These objects then chatter back and forth, changing each other's state. This introduces a lot of coupling, and it is a big reason that OO systems can be hard to change.
Tip 50: Don't Hoard State; Pass It Around
In the transformational model, we turn that on its head. Instead of little pools of data spread all over the system, think of data as a mighty river, a flow. Data becomes a peer to functionality: a pipeline is a sequence of code → data → code → data…. The data is no longer tied to a particular group of functions, as it is in a class definition. Instead it is free to represent the unfolding progress of our application as it transforms its inputs into its outputs. This means that we can greatly reduce coupling: a function can be used (and reused) anywhere its parameters match the output of some other function.
Yes, there is still a degree of coupling, but in our experience it's more manageable than the OO-style of command and control. And, if you're using a language with type checking, you'll get compile-time warnings when you try to connect two incompatible things.
What About Error Handling?
So far our transforms have worked in a world where nothing goes wrong. How can we use them in the real world, though? If we can only build linear chains, how can we add all that conditional logic that we need for error checking?
There are many ways of doing this, but they all rely on a basic convention: we never pass raw values between transformations. Instead, we wrap them in a data structure (or type) which also tells us if the contained value is valid. In Haskell, for example, this wrapper is called Maybe. In F# and Scala it's Option.
How you use this concept is language specific. In general, though, there are two basic ways of writing the code: you can handle checking for errors inside your transformations or outside them.
Elixir, which we've used so far, doesn't have this support built in. For our purposes this is a good thing, as we get to show an implementation from the ground up. Something similar should work in most other languages.
First, Choose a Representation
We need a representation for our wrapper (the data structure that carries around a value or an error indication). You can use structures for this, but Elixir already has a pretty strong convention: functions tend to return a tuple containing either {:ok, value} or {:error, reason}. For example, File.open returns either :ok and an IO process or :error and a reason code:
iex(1)> File.open("/etc/passwd")
{:ok, #PID
We'll use the :ok/:error tuple as our wrapper when passing things through a pipeline.
Then Handle It Inside Each Transformation
Let's write a function that returns all the lines in a file that contain a given string, truncated to the first 20 characters. We want to write it as a transformation, so the input will be a file name and a string to match, and the output will be either an :ok tuple with a list of lines or an :error tuple with some kind of reason. The top-level function should look something like this:
def find_all(file_name, pattern) do File.read(file_name) |> find_matching_lines(pattern) |> truncate_lines() end
There's no explicit error checking here, but if any step in the pipeline returns an error tuple then the pipeline will return that error without executing the functions that follow.[42] We do this using Elixir's pattern matching:
defp find_matching_lines({:ok, content}, pattern) do
content
|> String.split(~r/\n/)
|> Enum.filter(?(1, pattern))
|> ok_unless_empty()
end
defp find_matching_lines(error, _), do: error
# ----------
defp truncate_lines({ :ok, lines }) do
lines
|> Enum.map((1, 0, 20))
|> ok()
end
defp truncate_lines(error), do: error
# ----------
defp ok_unless_empty([]), do: error("nothing found")
defp ok_unless_empty(result), do: ok(result)
defp ok(result), do: { :ok, result }
defp error(reason), do: { :error, reason }
Have a look at the function find_matching_lines. If its first parameter is an :ok tuple, it uses the content in that tuple to find lines matching the pattern. However, if the first parameter is not an :ok tuple, the second version of the function runs, which just returns that parameter. This way the function simply forwards an error down the pipeline. The same thing applies to truncate_lines.
We can play with this at the console:
iex> Grep.find_all "/etc/passwd", ~r/www/
{:ok, ["_www:*:70:70:World W", "_wwwproxy:*:252:252:"]}iex> Grep.find_all "/etc/passwd", ~r/wombat/
{:error, "nothing found"}
iex> Grep.find_all "/etc/koala", ~r/www/
{:error, :enoent}
You can see that an error anywhere in the pipeline immediately becomes the value of the pipeline.
Or Handle It in the Pipeline
You might be looking at the find_matching_lines and truncate_lines functions thinking that we've moved the burden of error handling into the transformations. You'd be right. In a language which uses pattern matching in function calls, such as Elixir, the effect is lessened, but it's still ugly.
It would be nice if Elixir had a version of the pipeline operator |> that knew about the :ok/:error tuples and which short-circuited execution when an error occurred.[43] But the fact that it doesn't allows us to add something similar, and in a way that is applicable to a number of other languages.
The problem we face is that when an error occurs we don't want to run code further down the pipeline, and that we don't want that code to know that this is happening. This means that we need to defer running pipeline functions until we know that previous steps in the pipeline were successful. To do this, we'll need to change them from function calls into function values that can be called later. Here's one implementation:
defmodule Grep1 do
def and_then({ :ok, value }, func), do: func.(value)
def and_then(anything_else, _func), do: anything_else
def find_all(file_name, pattern) do
File.read(file_name)
|> and_then((1, pattern))
|> and_then((1))
end
defp find_matching_lines(content, pattern) do
content
|> String.split(~r/\n/)
|> Enum.filter(?(1, pattern))
|> ok_unless_empty()
end
defp truncate_lines(lines) do
lines
|> Enum.map((1, 0, 20))
|> ok()
end
defp ok_unless_empty([]), do: error("nothing found")
defp ok_unless_empty(result), do: ok(result)
defp ok(result), do: { :ok, result }
defp error(reason), do: { :error, reason }
end
The and_then function is an example of a bind function: it takes a value wrapped in something, then applies a function to that value, returning a new wrapped value. Using the and_then function in the pipeline takes a little extra punctuation because Elixir needs to be told to convert function calls into function values, but that extra effort is offset by the fact that the transforming functions become simple: each just takes a value (and any extra parameters) and returns {:ok, new_value} or {:error, reason}.
Transformations Transform Programming
Thinking of code as a series of (nested) transformations can be a liberating approach to programming. It takes a while to get used to, but once you've developed the habit you'll find your code becomes cleaner, your functions shorter, and your designs flatter.
Give it a try.
Related Sections Include
- Topic 8, The Essence of Good Design
- Topic 17, Shell Games
- Topic 26, How to Balance Resources
- Topic 28, Decoupling
- Topic 35, Actors and Processes
Exercises
Exercise 21 (possible answer)
Can you express the following requirements as a top-level transformation? That is, for each, identify the input and the output.
- Shipping and sales tax are added to an order
- Your application loads configuration information from a named file
- Someone logs in to a web application
Exercise 22 (possible answer)
You've identified the need to validate and convert an input field from a string into an integer between 18 and 150. The overall transformation is described by
field contents as string
→ [validate convert]
→ {:ok, value} | {:error, reason}
Write the individual transformations that make up validate & convert.
Exercise 23 (possible answer)
In Language X Doesn't Have Pipelines we wrote:
const content = File.read(file_name); const lines = find_matching_lines(content, pattern) const result = truncate_lines(lines)
Many people write OO code by chaining together method calls, and might be tempted to write this as something like:
const result = content_of(file_name)
.find_matching_lines(pattern)
.truncate_lines()
What's the difference between these two pieces of code? Which do you think we prefer?
Topic 31. Inheritance Tax
You wanted a banana but what you got was a gorilla holding the banana and the entire jungle.
Joe Armstrong
Do you program in an object-oriented language? Do you use inheritance?
If so, stop! It probably isn't what you want to do.
Let's see why.
Some Background
Inheritance first appeared in Simula 67 in 1969. It was an elegant solution to the problem of queuing multiple types of events on the same list. The Simula approach was to use something called prefix classes. You could write something like this:
link CLASS car; ... implementation of car link CLASS bicycle; ... implementation of bicycle
The link is a prefix class that adds the functionality of linked lists. This lets you add both cars and bicycles to the list of things waiting at (say) a traffic light. In current terminology, link would be a parent class.
The mental model used by Simula programmers was that the instance data and implementation of class link was prepended to the implementation of classes car and bicycle. The link part was almost viewed as being a container that carried around cars and bicycles. This gave them a form of polymorphism: cars and bicycles both implemented the link interface because they both contained the link code.
After Simula came Smalltalk. Alan Kay, one of the creators of Smalltalk, describes in a 2019 Quora answer[44] why Smalltalk has inheritance:
So when I designed Smalltalk-72—and it was a lark for fun while thinking about Smalltalk-71—I thought it would be fun to use its Lisp-like dynamics to do experiments with “differential programming” (meaning: various ways to accomplish “this is like that except”).
This is subclassing purely for behavior.
These two styles of inheritance (which actually had a fair amount in common) developed over the following decades. The Simula approach, which suggested inheritance was a way of combining types, continued in languages such as C++ and Java. The Smalltalk school, where inheritance was a dynamic organization of behaviors, was seen in languages such as Ruby and JavaScript.
So, now we're faced with a generation of OO developers who use inheritance for one of two reasons: they don't like typing, or they like types.
Those who don't like typing save their fingers by using inheritance to add common functionality from a base class into child classes: class User and class Product are both subclasses of ActiveRecord::Base.
Those who like types use inheritance to express the relationship between classes: a Car is-a-kind-of Vehicle.
Unfortunately both kinds of inheritance have problems.
Problems Using Inheritance to Share Code
Inheritance is coupling. Not only is the child class coupled to the parent, the parent's parent, and so on, but the code that uses the child is also coupled to all the ancestors. Here's an example:
class Vehicle
def initialize
@speed = 0
end
def stop
@speed = 0
end
def move_at(speed)
@speed = speed
end
end
class Car
When the top-level calls my_car.move_at, the method being invoked is in Vehicle, the parent of Car.
Now the developer in charge of Vehicle changes the API, so move_at becomes set_velocity, and the instance variable @speed becomes @velocity.
An API change is expected to break clients of Vehicle class. But the top-level is not: as far as it is concerned it is using a Car. What the Car class does in terms of implementation is not the concern of the top-level code, but it still breaks.
Similarly the name of an instance variable is purely an internal implementation detail, but when Vehicle changes it also (silently) breaks Car.
So much coupling.
Problems Using Inheritance to Build Types
Some folks view inheritance as a way of defining new types. Their favorite design diagram shows class hierarchies. They view problems the way Victorian gentleman scientists viewed nature, as something to be broken down into categories.
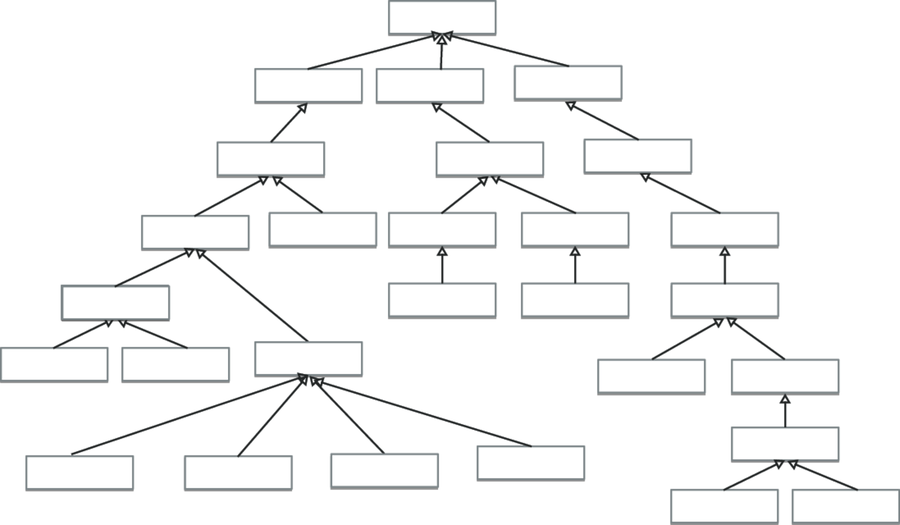
Unfortunately, these diagrams soon grow into wall-covering monstrosities, layer-upon-layer added in order to express the smallest nuance of differentiation between classes. This added complexity can make the application more brittle, as changes can ripple up and down many layers.
Even worse, though, is the multiple inheritance issue. A Car may be a kind of Vehicle, but it can also be a kind of Asset, InsuredItem, LoanCollateral and so on. Modeling this correctly would need multiple inheritance.
C++ gave multiple inheritance a bad name in the 1990s because of some questionable disambiguation semantics. As a result, many current OO languages don't offer it. So, even if you're happy with complex type trees, you won't be able to model your domain accurately anyway.
Tip 51: Don't Pay Inheritance Tax
The Alternatives Are Better
Let us suggest three techniques that mean you should never need to use inheritance again:
- Interfaces and protocols
- Delegation
- Mixins and traits
Interfaces and Protocols
Most OO languages allow you to specify that a class implements one or more sets of behaviors. You could say, for example, that a Car class implements the Drivable behavior and the Locatable behavior. The syntax used for doing this varies: in Java, it might look like this:
public class Car implements Drivable, Locatable {
// Code for class Car. This code must include
// the functionality of both Drivable
// and Locatable
}
Drivable and Locatable are what Java calls interfaces; other languages call them protocols, and some call them traits (although this is not what we'll be calling a trait later).
Interfaces are defined like this:
public interface Drivable {
double getSpeed();
void stop();
}
public interface Locatable() {
Coordinate getLocation();
boolean locationIsValid();
}
These declarations create no code: they simply say that any class that implements Drivable must implement the two methods getSpeed and stop, and a class that's Locatable must implement getLocation and locationIsValid. This means that our previous class definition of Car will only be valid if it includes all four of these methods.
What makes interfaces and protocols so powerful is that we can use them as types, and any class that implements the appropriate interface will be compatible with that type. If Car and Phone both implement Locatable, we could store both in a list of locatable items:
Listitems = new ArrayList
We can then process that list, safe in the knowledge that every item has getLocation and locationIsValid:
void printLocation(Locatable item) {
if (item.locationIsValid() {
print(item.getLocation().asString());
}
// ...
items.forEach(printLocation);Tip 52: Prefer Interfaces to Express Polymorphism
Interfaces and protocols give us polymorphism without inheritance.
Delegation
Inheritance encourages developers to create classes whose objects have large numbers of methods. If a parent class has 20 methods, and the subclass wants to make use of just two of them, its objects will still have the other 18 just lying around and callable. The class has lost control of its interface. This is a common problem—many persistence and UI frameworks insist that application components subclass some supplied base class:
class Account
The Account class now carries all of the persistence class's API around with it. Instead, imagine an alternative using delegation, as in the following example:
class Account
def initialize(. . .)
@repo = Persister.for(self)
end
def save
@repo.save()
end
end
We now expose none of the framework API to the clients of our Account class: that coupling is now broken. But there's more. Now that we're no longer constrained by the API of the framework we're using, we're free to create the API we need. Yes, we could do that before, but we always ran the risk that the interface we wrote can be bypassed, and the persistence API used instead. Now we control everything.
Tip 53: Delegate to Services: Has-A Trumps Is-A
In fact, we can take this a step further. Why should an Account have to know how to persist itself? Isn't its job to know and enforce the account business rules?
class Account # nothing but account stuff end class AccountRecord # wraps an account with the ability # to be fetched and stored end
Now we're really decoupled, but it has come at a cost. We're having to write more code, and typically some of it will be boilerplate: it's likely that all our record classes will need a find method, for example.
Fortunately, that's what mixins and traits do for us.
Mixins, Traits, Categories, Protocol Extensions, …
As an industry, we love to give things names. Quite often we'll give the same thing many names. More is better, right?
That's what we're dealing with when we look at mixins. The basic idea is simple: we want to be able to extend classes and objects with new functionality without using inheritance. So we create a set of these functions, give that set a name, and then somehow extend a class or object with them. At that point, you've created a new class or object that combines the capabilities of the original and all its mixins. In most cases, you'll be able to make this extension even if you don't have access to the source code of the class you're extending.
Now the implementation and name of this feature varies between languages. We'll tend to call them mixins here, but we really want you to think of this as a language-agnostic feature. The important thing is the capability that all these implementations have: merging functionality between existing things and new things.
As an example, let's go back to our AccountRecord example. As we left it, an AccountRecord needed to know about both accounts and about our persistence framework. It also needed to delegate all the methods in the persistence layer that it wanted to expose to the outside world.
Mixins give us an alternative. First, we could write a mixin that implements (for example) two of three of the standard finder methods. We could then add them into AccountRecord as a mixin. And, as we write new classes for persisted things, we can add the mixin to them, too:
mixin CommonFinders {
def find(id) { ... }
def findAll() { ... }
end
class AccountRecord extends BasicRecord with CommonFinders
class OrderRecord extends BasicRecord with CommonFinders
We can take this a lot further. For example, we all know our business objects need validation code to prevent bad data from infiltrating our calculations. But exactly what do we mean by validation?
If we take an account, for example, there are probably many different layers of validation that could be applied:
- Validating that a hashed password matches one entered by the user
- Validating form data entered by the user when an account is created
- Validating form data entered by an admin person updating the user details
- Validating data added to the account by other system components
- Validating data for consistency before it is persisted
A common (and we believe less-than-ideal) approach is to bundle all the validations into a single class (the business object/persistence object) and then add flags to control which fire in which circumstances.
We think a better way is to use mixins to create specialized classes for appropriate situations:
class AccountForCustomer extends Account
with AccountValidations,AccountCustomerValidations
class AccountForAdmin extends Account
with AccountValidations,AccountAdminValidations
Here, both derived classes include validations common to all account objects. The customer variant also includes validations appropriate for the customer-facing APIs, while the admin variant contained (the presumably less restrictive) admin validations.
Now, by passing instances of AccountForCustomer or AccountForAdmin back and forth, our code automatically ensures the correct validation is applied.
Tip 54: Use Mixins to Share Functionality
Inheritance Is Rarely the Answer
We've had a quick look at three alternatives to traditional class inheritance:
- Interfaces and protocols
- Delegation
- Mixins and traits
Each of these methods may be better for you in different circumstances, depending on whether your goal is sharing type information, adding functionality, or sharing methods. As with anything in programming, aim to use the technique that best expresses your intent.
And try not to drag the whole jungle along for the ride.
Related Sections Include
- Topic 8, The Essence of Good Design
- Topic 10, Orthogonality
- Topic 28, Decoupling
Challenges
- The next time you find yourself subclassing, take a minute to examine the options. Can you achieve what you want with interfaces, delegation, and/or mixins? Can you reduce coupling by doing so?
Topic 32. Configuration
Let all your things have their places; let each part of your business have its time.
Benjamin Franklin, Thirteen Virtues, autobiography
When code relies on values that may change after the application has gone live, keep those values external to the app. When your application will run in different environments, and potentially for different customers, keep the environment- and customer-specific values outside the app. In this way, you're parameterizing your application; the code adapts to the places it runs.
Tip 55: Parameterize Your App Using External Configuration
Common things you will probably want to put in configuration data include:
- Credentials for external services (database, third party APIs, and so on)
- Logging levels and destinations
- Port, IP address, machine, and cluster names the app uses
- Environment-specific validation parameters
- Externally set parameters, such as tax rates
- Site-specific formatting details
- License keys
Basically, look for anything that you know will have to change that you can express outside your main body of code, and slap it into some configuration bucket.
Static Configuration
Many frameworks, and quite a few custom applications, keep configuration in either flat files or database tables. If the information is in flat files, the trend is to use some off-the-shelf plain-text format. Currently YAML and JSON are popular for this. Sometimes applications written in scripting languages use special purpose source-code files, dedicated to containing just configuration. If the information is structured, and is likely to be changed by the customer (sales tax rates, for example), it might be better to store it in a database table. And, of course, you can use both, splitting the configuration information according to use.
Whatever form you use, the configuration is read into your application as a data structure, normally when the application starts. Commonly, this data structure is made global, the thinking being that this makes it easier for any part of the code to get to the values it holds.
We prefer that you don't do that. Instead, wrap the configuration information behind a (thin) API. This decouples your code from the details of the representation of configuration.
Configuration-As-A-Service
While static configuration is common, we currently favor a different approach. We still want configuration data kept external to the application, but rather than in a flat file or database, we'd like to see it stored behind a service API. This has a number of benefits:
- Multiple applications can share configuration information, with authentication and access control limiting what each can see
- Configuration changes can be made globally
- The configuration data can be maintained via a specialized UI
- The configuration data becomes dynamic
That last point, that configuration should be dynamic, is critical as we move toward highly available applications. The idea that we should have to stop and restart an application to change a single parameter is hopelessly out of touch with modern realities. Using a configuration service, components of the application could register for notifications of updates to parameters they use, and the service could send them messages containing new values if and when they are changed.
Whatever form it takes, configuration data drives the runtime behavior of an application. When configuration values change, there's no need to rebuild the code.
Don't Write Dodo-Code
Without external configuration, your code is not as adaptable or flexible as it could be. Is this a bad thing? Well, out here in the real world, species that don't adapt die.
The dodo didn't adapt to the presence of humans and their livestock on the island of Mauritius, and quickly became extinct.[45] It was the first documented extinction of a species at the hand of man.
Don't let your project (or your career) go the way of the dodo.

Related Sections Include
- Topic 9, DRY—The Evils of Duplication
- Topic 14, Domain Languages
- Topic 16, The Power of Plain Text
- Topic 28, Decoupling
[37]So it's not really a law. It's more like The Jolly Good Idea of Demeter.
[38]https://media.pragprog.com/articles/jan_03_enbug.pdf
[39]Yes, we know that Ruby already has this capability with its at_exit function.
[40]https://media.pragprog.com/titles/tpp20/code/event/rxcommon/logger.js
[41]It seems that the first use of the characters |> as a pipe dates to 1994, in a discussion about the language Isobelle/ML, archived at https://blogs.msdn.microsoft.com/dsyme/2011/05/17/archeological-semiotics-the-birth-of-the-pipeline-symbol-1994/
[42]We've taken a liberty here. Technically we do execute the following functions. We just don't execute the code in them.
[43]In fact you could add such an operator to Elixir using its macro facility; an example of this is the Monad library in hex. You could also use Elixir's with construct, but then you lose much of the sense of writing transformations that you get with pipelines.
[44]https://www.quora.com/What-does-Alan-Kay-think-about-inheritance-in-object-oriented-programming
[45]It didn't help that the settlers beat the placid (read: stupid) birds to death with clubs for sport.