【Go】深入理解内存模型
潘忠显 / 2024-12-18
很多人点开过《The Go Memory Model》这个文档,但被前边几段文字劝退了而未读完。
本文就带你看懂文章讲的内容,搞清楚这到底是什么 Model!

首先你要知道,本文是介绍内存模型,它定义了在多线程或并发环境下,程序中不同部分之间如何共享和同步内存。而不包括内存分配、垃圾回收等内容,这些属于内存管理(Memory Management)。
The Go memory model specifies the conditions under which reads of a variable in one goroutine can be guaranteed to observe values produced by writes to the same variable in a different goroutine.
Go 内存模型指明了:保证在一个 goroutine 中读取某个变量能够观察到在另一个 goroutine 中写入同一变量所产生值的条件。
内存模型 是对编程的规则和约束,指导开发者如何正确编程,以确保在并发编程中内存操作的正确性和一致性。也不是底层实现原理介绍!
1. 引子
这里有一个典型的例子——服务中更新和使用配置:
- 一个 Goroutine,定时刷新写入
- 若干 Goroutine,随时读取
假设我们使用一个 map[string]string 变量来存储配置。
大家都知道,Go 中的 map 是非线程安全的,如果并发读写,需要使用锁或其他同步方式来控制。
非线程安全的原因也很容易理解:map 是通过哈希表实现的,而哈希表的操作(如插入、删除和查找)涉及到多个步骤,包括计算哈希值、定位桶、处理冲突等。这些操作在并发环境下可能会相互干扰,导致数据不一致或崩溃。
另外一点,map 是一种引用类型。当你执行 a := make(map[string]string) 的时候,实际上是 a 变量持有一个 map 的引用。而当你继续调用 b := a的时候,也是将该引用赋给了 b。
我们考虑一种设计:配置更新协程每次创建一个新的 map 更新内容之后,将这个 map 的引用赋值给全局的 cache 变量;而使用配置的协程每次读取这个引用,中间不使用任何原子或同步操作。
这样的场景中,引用的赋值是否是原子的?程序是否会崩溃?是否需要考虑数据竞争的影响?
所谓数据竞争是指针两个或多个goroutine同时访问同一内存位置,且至少有一个是写操作,并且没有使用同步原语来协调访问,就会发生数据竞争。
2. 理解单词 Model
可能有同学跟我一样,阅读完 Go Memory Model,也没明白到底哪里有个 model。
「Model」这个单词的一些用法,我们相对容易理解,比如:模特、飞机模型、OSI七层网络模型、机器学习模型等。想到这些用法中的 model,你脑子里应该都会出现对应的图像画面。
我们要理解 Memory Model,需要结合上下文看看:
The Go memory model specifies the conditions under which reads of a variable in one goroutine can be guaranteed to observe values produced by writes to the same variable in a different goroutine.
The memory model describes the requirements on program executions, which are made up of goroutine executions, which in turn are made up of memory operations.
通过这两处用法,我理解这里的 model 是一种规范,它描述了一系列必须要满足的规则。因为我们也在文章中,看到了 3 个 requiretments。
我还特意去牛津词典中找了一圈,可能下边这种用法与我们这里的 Memory Model 最为相似。

之前在开发管理端网站的时候,有接触到 MVC(Model-View-Controller)设计模式,这里的 model 是指 data model,类似于规范,但更倾向于将现实世界的物体建模成特定的数据表:
A data model is an abstract model that organizes elements of data and standardizes how they relate to one another and to the properties of real-world entities.
3. 内存模型
程序执行由 goroutine 执行组成,goroutine 执行由一组内存操作组成,多个goroutine可能在不同的CPU核上运行。
内存操作包括四个细节:
- 被操作的数据类型,是普通数据类型,还是同步操作——原子数据访问、通道、sync.Mutex等操作
- 该操作所处在程序中的位置
- 所访问的内存位置
- 该操作读出或写入的值
3.1 偏序(Partial Order)与全序(Total Order)
偏序(Partial Order) 是一种在集合中的元素之间定义的顺序关系,其中并不是所有的元素都必须是可比较的。换句话说,在偏序中,某些元素之间可能没有直接的顺序关系。偏序关系通常满足以下三个性质:
- 自反性(Reflexivity):对于集合中的任意元素 $a$,有 $(a \leq a)$
- 反对称性(Antisymmetry):对于集合中的任意元素 $a$ 和 $b$,如果 $a \leq b$ 且 $b \leq a$,则 $a = b$。
- 传递性(Transitivity):对于集合中的任意元素 $a$、$b$ 和 $c$,如果 $a \leq b$ 且 $b \leq c$,则 $a \leq c$。
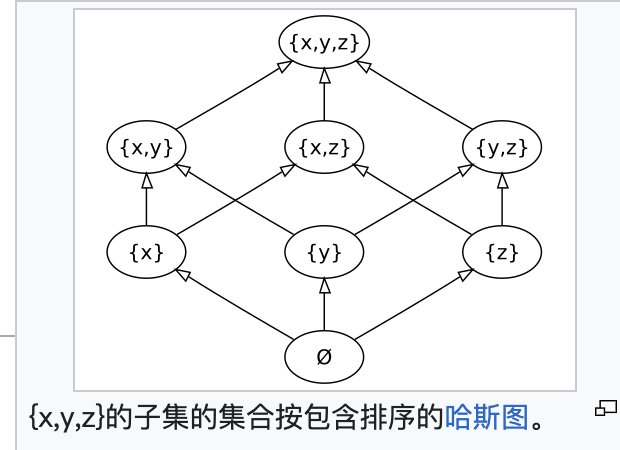
全序(Total Order) 是一种特殊的偏序关系,其中集合中的任意两个元素都是可比较的。换句话说,在全序中,对于集合中的任意元素 $a$ 和 $b$,要么 $a \leq b$,要么 $b \leq a$。全序关系除了满足偏序的三个性质(自反性、反对称性和传递性)外,还满足以下性质:
- 全性(Totality):对于集合中的任意元素 $a$ 和 $b$,要么 $a \leq b$,要么 $b \leq a$。
3.2 理解 DRF-SC
DRF-SC(Data-Race-Free Sequential Consistency)是一种内存模型,其核心思想是:如果一个程序是无数据竞争的(Data-Race-Free),那么它在任何执行中都将表现出顺序一致性(Sequential Consistency)。
假设有两个线程 $T1$ 和 $T2$:
- 线程 $T1$ 执行操作序列:$A1, A2$
- 线程 $T2$ 执行操作序列:$B1, B2$
在顺序一致性模型中,可能的全局顺序包括:
- $A1, A2, B1, B2$
- $A1, B1, A2, B2$
- $B1, A1, A2, B2$
- $B1, A1, B2, A2$
它要求所有的内存操作(读和写)在所有线程中都以某种全局顺序执行,并且每个线程的操作在全局顺序中保持它们在程序中的顺序。
3.3 R1: 单个 Goroutine 的执行模型和要求
单个 goroutine 执行 被建模为由单个 goroutine 执行的一组内存操作。
「sequenced before」关系:Go语言中控制流、表达式求值顺序等规定的顺序。
Requirement 1 强调了在每个 goroutine 内的内存操作必须按照程序中定义的顺序执行,确保读取和写入的值是正确的。
这种执行顺序必须与 Go 语言规范中定义的 “sequenced before” 关系保持一致。这包括程序的控制流结构和表达式的求值顺序。
3.4 R2: Go 程序的执行模型和同步
一个 Go 程序执行被建模为一组 goroutine 执行,以及一个映射 $W$,该映射指定每个读操作从中读取的写操作。不同的程序执行实例可能会有不同的执行路径。
对于某一次具体的程序执行,映射 $W$ 中的同步操作必须能够通过某种隐含的全序来解释,这个顺序需要与程序的顺序、实际值的读写保持一致。
3.5 synchronized before 与 happens before
「synchronized before」关系是一个偏序关系,用于描述同步内存操作之间的顺序。这个关系是派生自上边的$W$ 映射。之所以是一个偏序关系,因为并不是所有的同步内存操作之间都有明确的顺序关系,只有那些通过 $W$ 映射直接观察到的操作之间才有这种关系。而对于 $W$ 观察不到的那些同步操作,它们之间没有定义明确的顺序关系,因此它们在「synchronized before」关系中是不可比较的。
这里「synchronized before」分析,针对的是特定的一次程序执行。
传递闭包(Transitive closure) 是数学和计算机科学中的一个概念,通常用于描述关系的扩展。具体来说,传递闭包是指在一个关系中,如果存在 A 关系 B,B 关系 C,那么通过传递闭包,我们可以得出 A 关系 C。
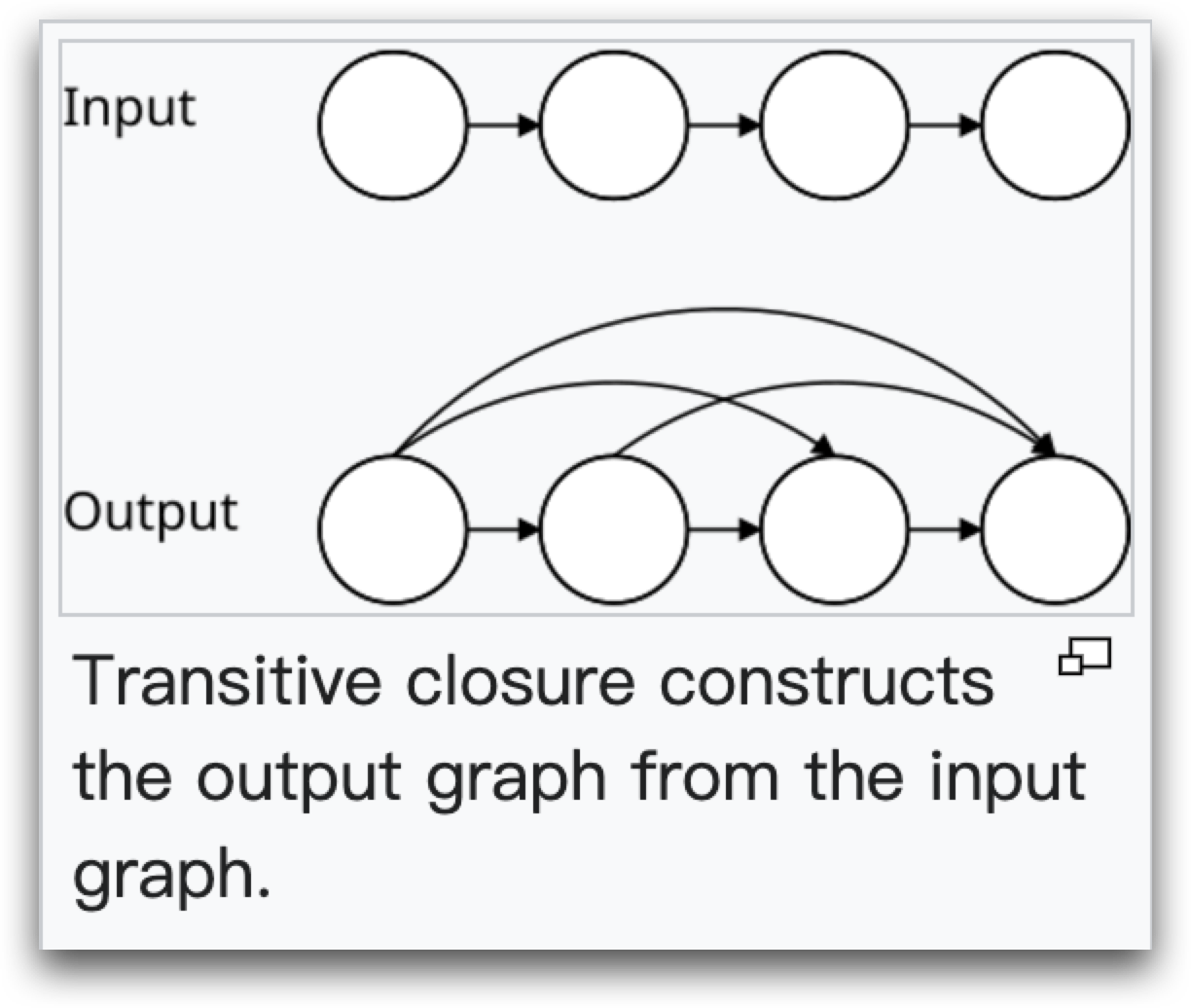
「happens before」关系,是通过将 「sequenced before」 和 「synchronized before」 关系联合起来,并进行传递闭包操作得到的。换句话说,A sequenced before B 或者 A synchronized before B 都是 A happens before B。
- “sequenced before” 适用于单个 goroutine 内的操作顺序
- “synchronized before” 适用于多个 goroutine 之间的同步顺序
- “happens before” 结合了这两种关系,适用于单个 goroutine 和多个 goroutine 之间的操作顺序
3.6 三种关系的分析示例
为了彻底搞清楚三种 before 关系,我这里提供一个简单的例子。根据代码,来分析一下这些关系。

「sequenced before」关系,发生在每个 goroutine 中:A关系B,B关系C;D关系E,E关系F;G关系H,H关系I
「synchronized before」关系,发生在协程之间,在一次特定的执行中:通过 mu1,C 关系 G,因为 mu1 的解锁操作同步了后续的锁操作;通过 mu2 同步的操作 F 没有与其他语句有「synchronized before」关系,因为只有 goroutine2 中有使用。
「happens before」关系,有 A 关系 B(通过sequenced before),有 C 关系 G(通过synchronized before),有通过两种关系进行传递闭包产生的 A 关系 H(因为 A “sequenced before” B,B “sequenced before” C,C “synchronized before” G,G “sequenced before” H。)
3.7 数据竞争
为了说明 Requirement 3,我们再明确一下,在数据竞争和无数据竞争的情况下,具体是发生了什么。
数据竞争:
- 读写数据竞争:在内存位置 $x$ 上的读操作 $r$ 和写操作 $w$ 之间,如果至少有一个是非同步的,并且它们在发生前关系中是无序的(即 $r$ 不发生在 $w$ 之前,且 $w$ 不发生在 $r$ 之前)。
- 写写数据竞争:在内存位置 $x$ 上的两个写操作 $w$ 和 $w’$ 之间,如果至少有一个是非同步的,并且它们的 happens before 关系是无序的。
无数据竞争:如果在内存位置 $x$ 上没有读写或写写数据竞争,那么对 $x$ 的任何读操作 $r$ 只有一个可能的 $W(r)$:在发生前顺序中紧接在其之前的单个写操作 $w$。
3.8 R3: 普通数据读操作的可见性
对于内存位置 $x$ 上的普通(非同步)数据读操作 $r$,映射 $W(r)$ 必须是对 $r$ 可见的写操作 $w$,其中可见意味着以下两个条件都成立:
- $w$ 发生在 $r$ 之前(happens before)。
- $w$ 不发生在任何其他写操作 $w’$(对 $x$)之前,而 $w’$ 发生在 $r$ 之前。
这个要求是说如何能保证一个普通数据的修改可以被看到。再结合前边的数据竞争的描述,我们可以看到,如果有数据竞争的时候,上边这两个条件无法被满足,所以数据的修改也不能保证被看到:
- 读写竞争发生时,$w$ 不一定能发生在 $r$ 之前,不满足条件1
- 写写竞争发生时,不能保证 $w$ 不发生在 $w’$ 之前,不满足条件2
因此,当存在数据竞争时,应当使用同步机制,来保证变量的可见性符合预期。
4. 数据竞争的实现限制
4.1 ThreadSanitizer
通过调用 go build -race,可以启用 Go 语言的内置数据竞争检测器 ThreadSanitizer,这是 Go 语言团队开发的一个专门用于 Go 程序的数据竞争检测工具。
具体地,使用 go build -race 构建 Go 程序时,编译器会在生成的可执行文件中插入额外的代码,以监视并检测数据竞争。如果检测到数据竞争,程序会在运行时输出详细的错误报告,包括竞争发生的线程、内存地址、访问类型以及相关的源代码位置,不会停止程序的执行。
4.2 单字、多字的竞争
machine word 机器字是计算机处理器在一次操作中能够处理的最大数据单位,大小通常与处理器的位宽一致。如在一个 32 位处理器上,机器字通常是 32 位(4 字节)。
记得上学的时候,说 8bit 是一个 byte,而 2 个 byte 是一个 word。其实是受限于使用的教材,当时学的是8086处理器,其位宽恰好是 16bit,所以说 2 bytes 是一个 word。
single machine word 是一个完整机器字大小的数据单位,half-word 就是半字,multi-word 是多字,而 sub-word-sized memory 指小于一个机器字大小的内存单位。
Go 语言中,字符串、数组、结构或复数的实现,是多字数据结构(multiword data structures)占用多个机器字。比如字符串类型通常包含一个指针和一个长度字段,而切片类型包含一个指针、一个长度字段和一个容量字段。这些多字数据结构的读写,可以按任意顺序实现为对每个单独的子值(数组元素、结构字段或实部/虚部)的读写。
While programmers should write Go programs without data races, there are limitations to what a Go implementation can do in response to a data race.
介绍这么多,为了说明:如果有数据竞争,单字的变量可能导致读到不一致的数据,但通常不会有内存问题;而多字结构的竞争,可能造成内存破坏! 比如,如果并发更新slice,一个slice的地址被写入,另外一个slice的长度和容量被写入,这时候就会有内存破坏或程序崩溃。
5. 同步
通过前边「synchronized before」的介绍,你应该理解了,这里提到同步,是在并发场景下的一些描述。Memory model 中也是有专门的一大节,介绍各种各样的同步场景。文档的这部分,非常容易理解,我这里不做赘述,只简单总结一下:
- 初始化:init 都完成之前再开始 main.main; 被导入的一定先执行并完成
- goroutine的开始,同步早于其执行
- 没有同步机制的goroutine不能保证其中数据更新被观察到,甚至可能被删除(不被执行)
- 同步机制还包括:通道、sync.Mutex、sync.Once、sync/atomic,以及条件变量、无锁map、资源池、WaitGroup等
- 终结器,我没用过 ;-)
之前写过一篇小文《透彻理解“阻塞/非阻塞”、“同步/异步” 》,有兴趣的同学也可以看看。
5.1 channel 容量控制并发
在 Go 语言中,通道(channel)是一种用于在 goroutine 之间传递数据的机制。通道可以是无缓冲的(unbuffered)或带缓冲的(buffered)。
- 无缓冲通道:发送操作和接收操作必须同时进行,否则会阻塞。
- 带缓冲通道:通道内部有一个固定大小的缓冲区,可以存储一定数量的元素。发送操作在缓冲区未满时不会阻塞,接收操作在缓冲区不为空时不会阻塞。
The kth receive on a channel with capacity C is synchronized before the completion of the k+Cth send from that channel completes.
如果通道 ch 的容量为 3,第 1 次接收操作会在第 4 次发送操作完成之前完成。
使用通道容量控制并发数,非常典型。经过通道的元素总数数对应于总的需要处理的次数,而通道容量则对应并发的最大数量。通过往通道发送获取信号量,从通道接收来释放信号量。
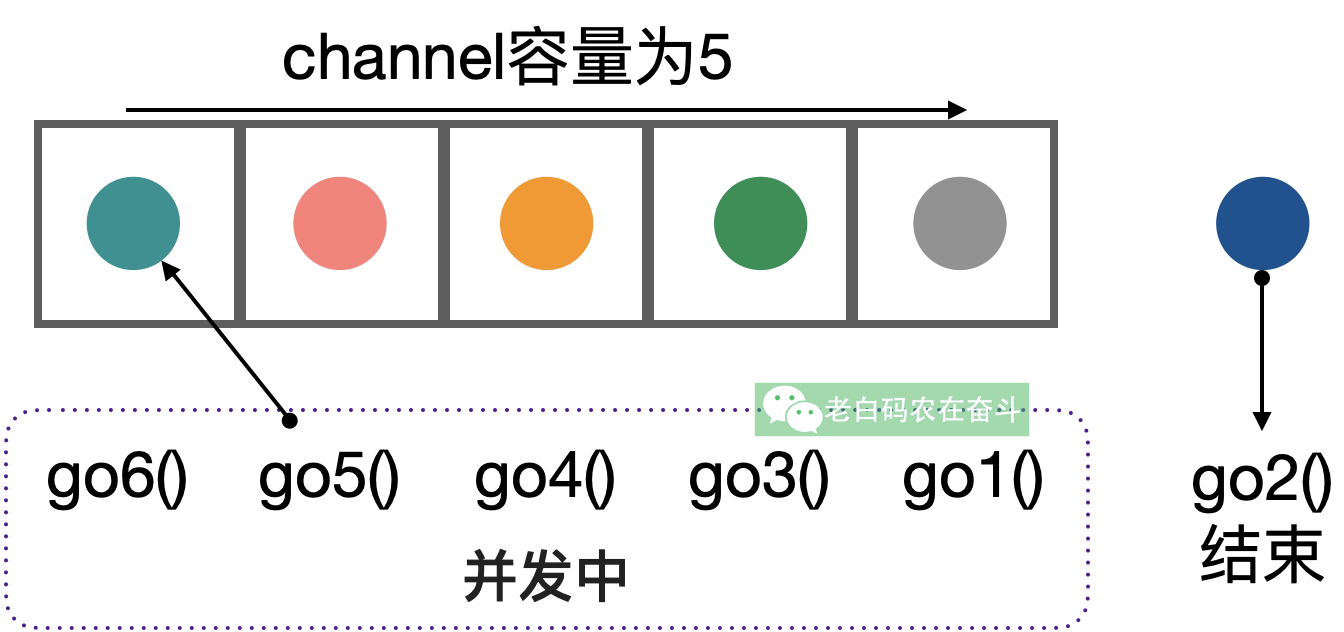
5.2 一个线上问题
这两天遇到一个问题,恰好可以用 channel 控制并发数量。
线上某服务在自动扩容的时候,一直因为就绪检查不成功而启动失败。
看了一下代码逻辑,是会先拉取一个长度超过 4万的列表,然后从 Redis 中串行拉取列表中每项的信息,都拉取之后才会启动端口监听。这一过程超过了4分钟,远超过了就绪检查的周期。
为了修复这个问题,就使用 goroutine 并发的去请求 Redis。但是因为怕并发过高带来副作用,所以需要限制并发数量,就是用了上边的带缓冲的 channel 控制。
修改后,这段代码同时用到了 sync.WaitGroup、sync.Mutex 以及 channel:
var wg sync.WaitGroup
var mu sync.Mutex
// 顺序可能有影响,所以先并发获取数据,再串行获取数据
dataMap := make(map[string]*Data, len(keyList))
sem := make(chan struct{}, 400)
for _, k := range keyList {
wg.Add(1)
sem <- struct{}{} // Acquire a slot
go func(k string) {
defer wg.Done()
defer func() { <-sem }() // Release the slot
// ...执行Redis查询的逻辑,并转换成Data结构指针...
mu.Lock()
dataMap[k] = data
mu.Unlock()
}(k)
}
wg.Wait()
ret := make([]*Data, 0)
for _, k := range keyList {
ret = append(ret, *dataMap[k])
}
修改后也按照预期解决了之前服务加载慢的问题:
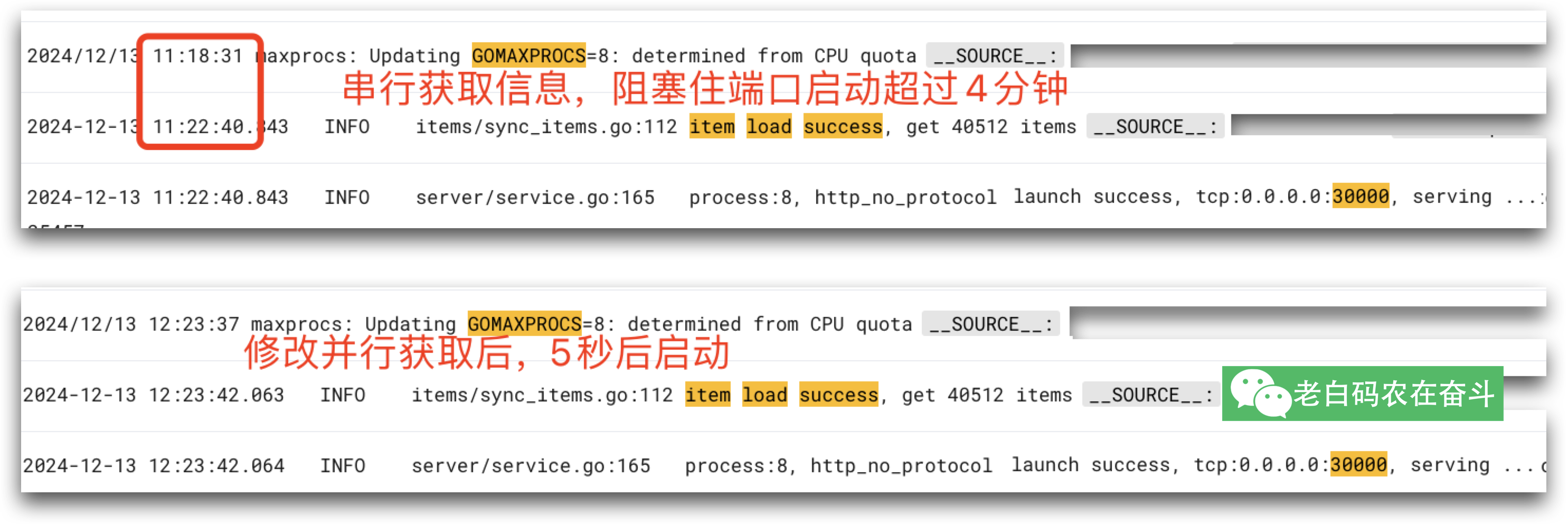
5.3 多核处理器的数据竞争
在 Model 一文中有提到一个例子,我们来看看这个代码可能有哪些输出情形:
var a, b int
func f() {
a = 1
b = 2
}
func g() {
print(b)
print(a)
}
func main() {
go f()
g()
}
我们很容易直接理解的一些情形:
2 1:f()执行完了g()才执行0 0: 执行g()时f()还没执行0 1: 两函数同时执行,给a赋值了,但是还没有个b赋值
还有一种输出结果,可能不太好理解:2 0,也就是文章中有提到这种情况,两函数同时执行,给 b 赋值了,但是还没有给 a 赋值。
因为 f() 和 g() 之间有数据竞争,而没有任何的同步是措施,所以没有 synchronized before 关系。
在多核处理器环境下,是有一些机制会导致 g() 中只看到了 b 被设置,而 a 未被设置。这些机制和问题包括:
- 指令重排序(Instruction Reordering):编译器和处理器为了优化性能,可能会对指令进行重排序。重排序不会改变单线程程序的语义,但在多线程环境中可能导致意外行为。
- 缓存一致性问题(Cache Coherence Issues):多核处理器上,每个核心都有自己的缓存;多个核心同时访问和修改同一个内存位置,可能导致缓存一致性问题。
- 内存可见性问题(Memory Visibility Issues):一个线程对共享变量的修改,可能不会立即对其他线程可见;处理器和编译器可能会对内存访问进行优化,例如将变量的值缓存在寄存器中,而不是立即写回内存。
另外一个错误示例,是不使用同步机制,而是忙等待一个标志:
var a string
var done bool
func setup() {
a = "hello, world"
done = true
}
func main() {
go setup()
for !done {
}
print(a)
}
有了前边的经验,我们知道:即使主线程中观察到 done 已经被设置成了 true,也可能打印出的 a 并未被设置。
但文中提到另外一点:Worse, there is no guarantee that the write to done will ever be observed by main, since there are no synchronization events between the two threads. The loop in main is not guaranteed to finish. 因为没有任何同步措施,main 可能永远不会观察到 done 被设置为 true。
6. Be clever or not?
文章开篇就提到了,「如果您必须阅读本文档的其余部分才能理解程序的行为,you are being too clever. Don’t be clever.」

「Don’t be clever」,是为了让你在老老实实遵循前边的要求:Programs that modify data being simultaneously accessed by multiple goroutines must serialize such access. 程序中有多goroutine 操作数据的时候,应该使用同步机制来序列化其访问。
遵循了通过同步机制,保护的并发数据访问,就不会需要理解后边的深层原理。
但理解原理仍然是有必要的。一方面,在我们写并发代码的时候,这些知识会不断提醒我们加同步措施;另一方面,在排查问题的时候,这些原理也能助我们快速地定位问题。
之前看到 StackOverflow 上有个问题 “Is assigning a pointer atomic in Go?” 看完本文,我们也能回答这个问题。即使这个指针是个 word,在并发设置时候程序不会崩溃,也无法保证其顺序性和对其他 goroutine 可见。
Go 语言中的 sync/atomic 包,提供的原子操作是保证顺序一致的(sequentially consistent)——所有线程都能看到一致的操作顺序。这种保证不仅仅是原子性,还包括了内存可见性。
跟之前类似的,我们应该遵循规范,使用明确、有保障的技术来实现我们的功能,而不要自作聪明,徒增烦恼。不遵循规范的小聪明可能当前有效,但在Go版本升级之后或者在不同的平台上,这些小聪明如沙上建塔,很容易出问题。
很多编程的原则都是类似的,Python之禅也有类似的指导。通过 python -c "import this" 你能看到这些:
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
...