GitHub每周热点(20260607)
潘忠显 / 2026-06-07
本周 GitHub Trending 周榜里,本周新增 Star 超过 1 万的项目一共有 4 个:
- microsoft/markitdown,本周新增 1.5 万 Star
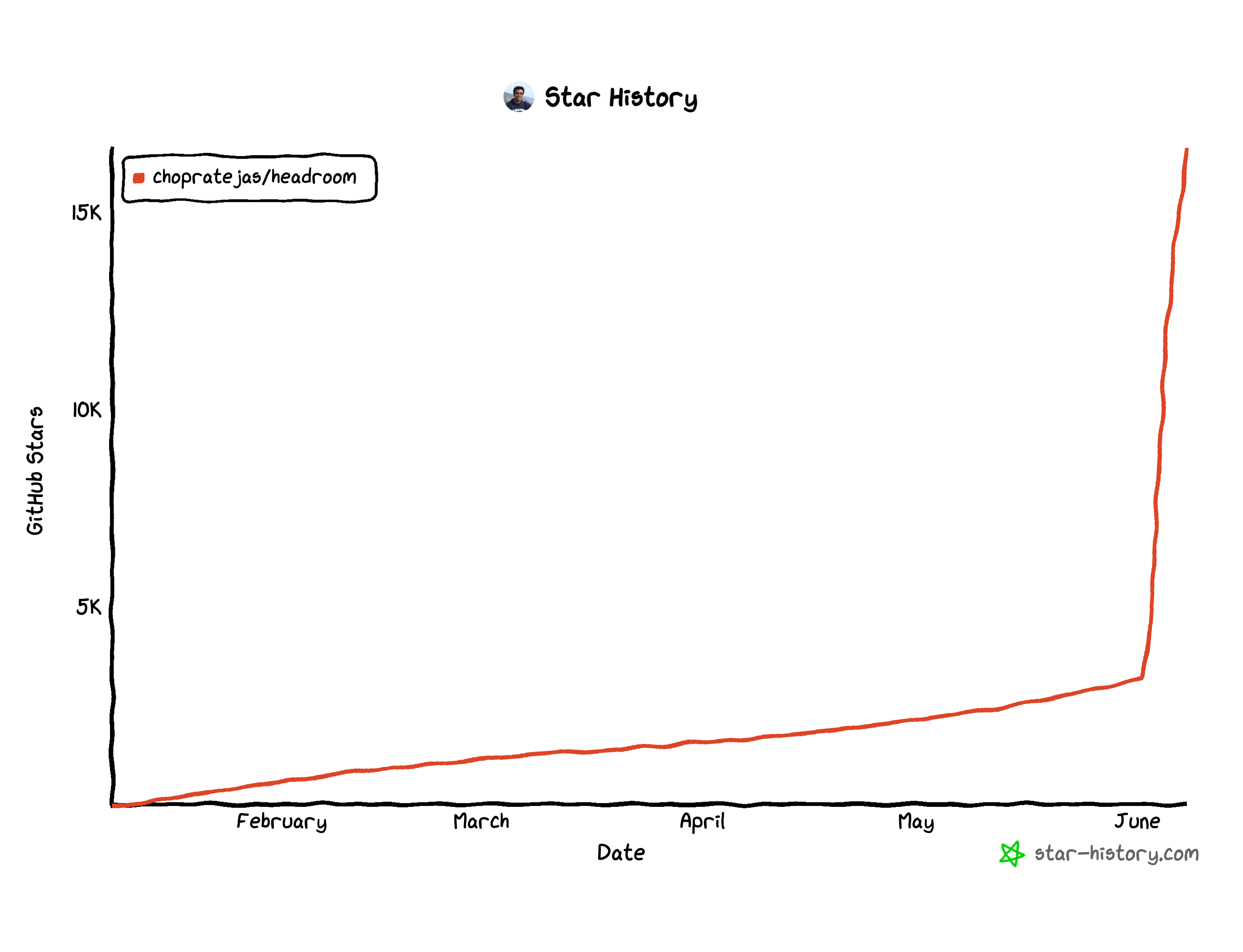
- chopratejas/headroom,本周新增 1.3 万 Star
- NousResearch/hermes-agent,本周新增 1.1 万 Star
- affaan-m/ECC,本周新增 1.0 万 Star
其中,markitdown 和 hermes-agent 之前已经介绍过了,这次就不重复展开:
- MarkItDown 在不少 AI 文档处理链路里都已经是基础工具了
- Hermes Agent 之前也单独介绍过,属于 2026 年很有代表性的 Agent 项目
另外一个达到 1 万新增 Star 的 ECC 也不是新项目,它面向 Claude Code、Codex、Cursor、OpenCode 等多个 Agent 工具,提供 skills、hooks、rules、memory、security scanning 等一整套增强能力,属于跨 Agent 的工程化全家桶。这次也不单独展开。
这次重点看本周真正的新面孔:headroom。
chopratejas/headroom
总 Star: 16614, 本周新增 Star: 13308
简介:在工具输出、日志、文件、RAG 检索结果真正送进大模型之前,先做一次压缩,目标是在尽量不影响效果的前提下,减少 60% 到 95% 的 token 消耗。
仓库:https://github.com/chopratejas/headroom
解决什么问题
这个项目解决的问题很直接:很多 AI Agent 真正贵的,并不是那一句 prompt,而是中间层源源不断灌进去的上下文。
比如搜索代码返回的大量结果、调试时塞进去的长日志、RAG 一次拿回来的很多 chunk,以及工具调用后返回的大段 JSON。这些内容并不一定没用,但如果原样全部喂给模型,token 消耗会非常夸张。
如果把 AI 编码或 Agent 系统想象成一个流水线,大模型其实只是最后做判断的“大脑”,而真正不断膨胀的是输入上下文。Headroom 做的事情,就是在 LLM 前面加一层“上下文压缩网关”。
Headroom 的定位不是重新发明一个模型,而是插在模型前面,做三件事:
- 压缩:把长文本、日志、RAG 片段压短
- 路由:不同类型的内容走不同压缩策略
- 保留可恢复性:不是简单粗暴地截断,而是尽量做到压缩后还能回溯原文
它支持几种接入方式:
- Library:直接在 Python 或 TypeScript 里调用
- Proxy:通过本地代理拦截请求,做到“零代码改造”
- Agent Wrap:一条命令包住 Claude Code、Codex、Cursor、Aider、Copilot CLI 等工具
- MCP Server:给支持 MCP 的客户端直接提供压缩和检索能力
这也是它这周涨这么快的一个原因:它并不是只服务某一个 Agent,而是试图成为“多 Agent 通用的 token 基础设施”。
使用方法简单
最简单的方式,是先安装,然后在调用 claude 等指令时加一层包装:
pip install "headroom-ai[all]"
headroom wrap claude
上边指令的 claude 可以替换成其他工具指令,比如 copilot、codex、aider、cursor 等,使用起来基本无感。
工作原理
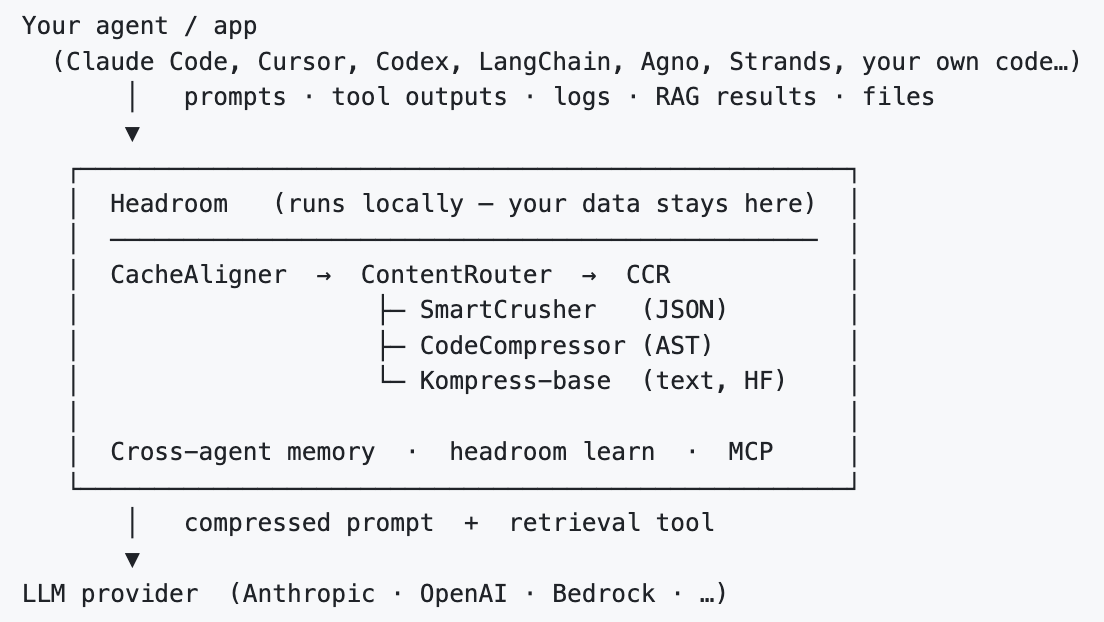
Headroom 的整体链路并不复杂,可以概括成一句话:先识别内容类型,再用对应的压缩器处理,最后把原文留在本地,只把压缩后的高密度上下文送给模型。
它处在 Agent 和大模型之间。上游无论是 prompt、工具输出、日志、RAG 结果还是文件内容,都会先进入 Headroom,再决定怎么处理后发给模型。
其中几个核心模块分工比较清楚:
- ContentRouter:先判断当前内容是什么类型,再选择合适的压缩路径
- SmartCrusher:处理 JSON、结构化工具输出这类内容
- CodeCompressor:处理代码,按 AST 和代码结构压缩
- Kompress-base:处理普通文本内容
- CacheAligner:尽量把前缀稳定下来,提高大模型服务商 KV cache 的命中率
- CCR:把原始内容留在本地,需要时再通过检索工具取回,而不是一开始全量塞进上下文
这里一个很自然的问题是:“识别”和“压缩”本身,会不会再调用一次大模型?如果会,那不是也要花 token 吗?”
答案是:默认情况下,不会调用远端大模型。 Headroom 的这一步主要依赖的是本地规则、本地统计方法和本地小模型,而不是把内容先发给 Anthropic、OpenAI 再让它帮你判断怎么压缩。
具体来说:
- 内容识别主要靠 Magika 这类本地 ML 检测,或者直接根据结构和模式匹配判断
- JSON、数组、日志这类内容,主要靠统计分析、采样、异常保留、模式聚类来压缩
- 代码压缩走的是 tree-sitter AST 解析,保留 import、函数签名、类型信息,再压缩函数体
- 普通文本压缩可以走 ModernBERT / LLMLingua 这类本地模型或文本压缩工具
所以它节省的不是“把一次大模型调用换成另一次大模型调用”,而是尽量用本地低成本计算先把上下文瘦身,再把更短的结果送进真正昂贵的 LLM。
当然,它也不是完全没有代价,只是这个代价主要体现在:
- 本地 CPU / 内存消耗
- 某些 ML 压缩组件的额外依赖和冷启动时间
- 压缩过深时,模型后续可能需要再通过
ccr_retrieve取回原文
但这跟直接把整段原始内容送进大模型相比,通常还是便宜得多。尤其是 JSON 数组、日志、搜索结果这类高冗余内容,本地做一遍统计压缩的成本,远低于把原文完整喂给模型。
最后送到模型侧的是压缩后的 prompt 和检索入口,而不是未经处理的大段原文。这样既能明显降低 token 消耗,也给模型保留了“需要时再回头取原文”的能力。
实际效果有冲击力
这个项目火得快,不只是因为“省钱”,更因为它抓住了一个已经非常明显的趋势:2026 年大家优化 Agent,不再只盯着模型本身,而是开始认真优化上下文工程。
大家关注的重点,正在从“模型、提示词、框架哪个好”,逐步转向“哪些内容该进上下文、该怎么压缩和摘要,以及怎样在效果基本不变的前提下把 token 成本降下来”。
Headroom 属于很典型的“第二层基础设施”项目。它不直接替代 Claude Code、Codex 或 Cursor,而是希望站在这些工具前面,帮你把上下文流量做一遍治理。
这个方向有几个很强的现实吸引力:
- 省钱:token 费用直接相关
- 提速:上下文变短以后,请求通常更快
- 跨工具复用:同一套压缩思路,可以服务多个 Agent
- 工程感强:比起一句“优化 prompt”,这类项目已经接近真正的基础设施
它给出了一些实际 workload 的压缩结果,比如:
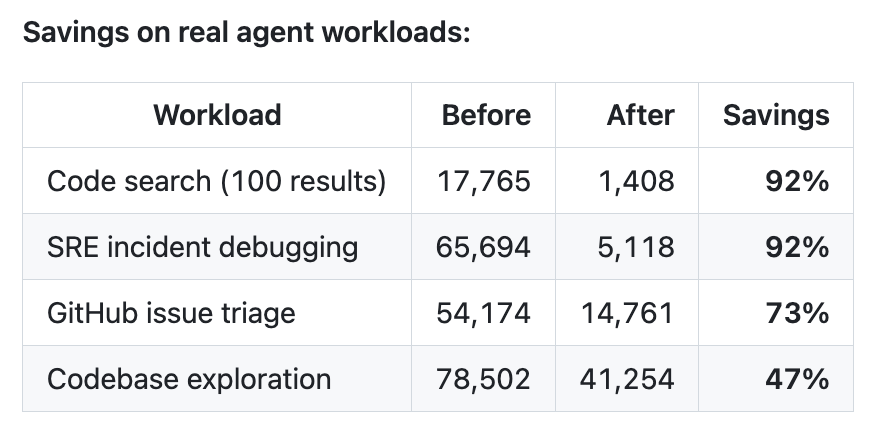
同时,作者还强调在一些 benchmark 上准确性基本保持不变。当然,这个标准是否具有普适性,还需要更多真实场景验证。
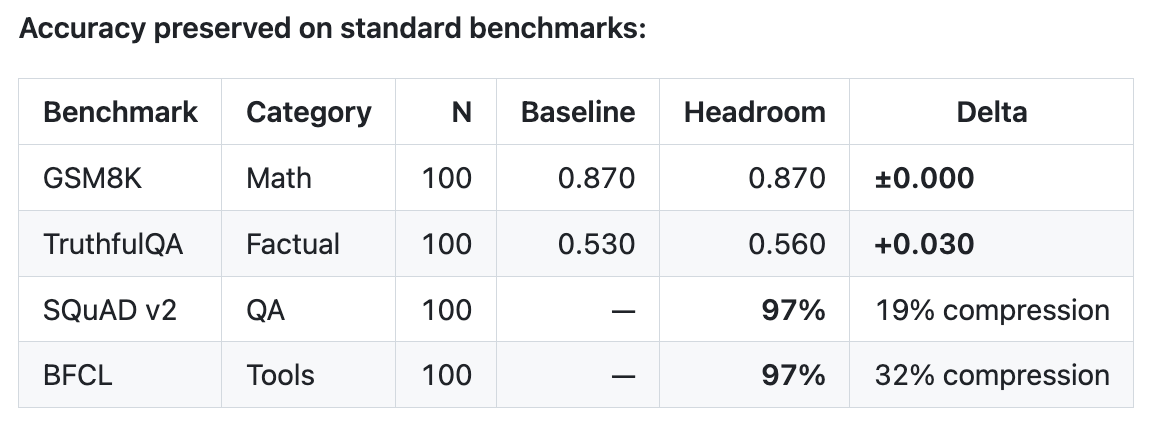
从“产品传播”的角度,这种表达很容易打动人:不是抽象地说我能优化上下文,而是直接把节省比例和落地场景给出来。
跟 CodeGraph 类项目有什么区别
上周热榜里的 colbymchenry/codegraph 其实也在解决一个很像的问题:尽量减少 Agent 在代码库探索阶段的 token 消耗。
但细看技术路径,这两个项目的思路差别很大。
CodeGraph 的核心路线是:提前建索引、提前建图谱。
它会先把项目代码做成一个本地的、预索引的 code knowledge graph,把符号关系、调用链、代码结构、全文搜索能力提前准备好。这样 AI Agent 在回答“这个函数被谁调用”“某个模块跟哪个入口有关”“某条链路怎么走”这类问题时,就不需要反复 grep、glob、Read 地扫描代码库,而是可以直接查询图谱。
一句话概括两者差异:
- CodeGraph 是“少找一些、但找得更准”,核心是预索引 + 结构化检索
- Headroom 是“拿到结果以后先压一遍再喂模型”,核心是压缩 + 路由 + token 治理
所以它们并不是互斥关系,反而可以互补:
- CodeGraph 解决“Agent 如何更高效地找到代码信息”
- Headroom 解决“找到的信息、日志和上下文怎样更便宜地送进模型”
也就是说,CodeGraph 更偏前置的代码理解基础设施,Headroom 更偏后置的上下文治理基础设施。前者主要减少探索成本,后者主要减少输入成本。
小结
这周新增 Star 超过 1 万的 4 个项目里,markitdown 和 hermes-agent 之前已经介绍过,ECC 更偏跨 Agent 的工程化增强全家桶,这次都不再展开。
本篇重点介绍的 Headroom,代表的是 Agent 时代越来越重要的一条路线:上下文压缩与 token 治理。
它的价值不在于替代某个现有 Agent,而是在 Claude Code、Codex、Cursor 这类工具之前,先把日志、RAG、JSON、代码结果这些高冗余输入做一遍治理,再把更短、更高密度的内容送给模型。
从这个角度看,AI 编码的竞争已经不只是“模型能力”本身,也越来越取决于上下文怎么组织、怎么压缩、怎么控制成本。