VibeVoice-Realtime:超快流式输入TTS
潘忠显 / 2025-12-14
今天看到本周 GitHub 热点有一个非常火的项目,是微软的 VibeVoice-Realtime,周增6950🌟。
这个项目上周刚新开源了一个0.5B的实时语音模型VibeVoice‑Realtime‑0.5B,支持流式文本输入和强大的长篇语音生成功能。
非常小非常快,MacBook上就能运行,效果也非常好。
不过目前还只支持英语、德语、日语、韩语等语言,相信中国话很快也会支持。
VibeVoice-Realtime 是一款轻量级的实时文本转语音模型,支持流式文本输入和强大的长篇语音生成功能。它可用于构建实时文本转语音服务、为实时数据流配音,并允许不同的大语言模型(LLM)从其第一个词元开始发声(可插入您偏好的模型),而无需等到生成完整答案。它可在约 300 毫秒内生成初始可听语音(具体时间取决于硬件)。
注(多语言探索):虽然该模型主要针对英语构建,但我们发现它仍然展现出一定的多语言能力,甚至在某些语言中表现相当不错。我们提供了九种额外的语言(德语、法语、意大利语、日语、韩语、荷兰语、波兰语、葡萄牙语和西班牙语)供用户探索。这些多语言行为尚未经过广泛测试;请谨慎使用并分享您的观察结果。
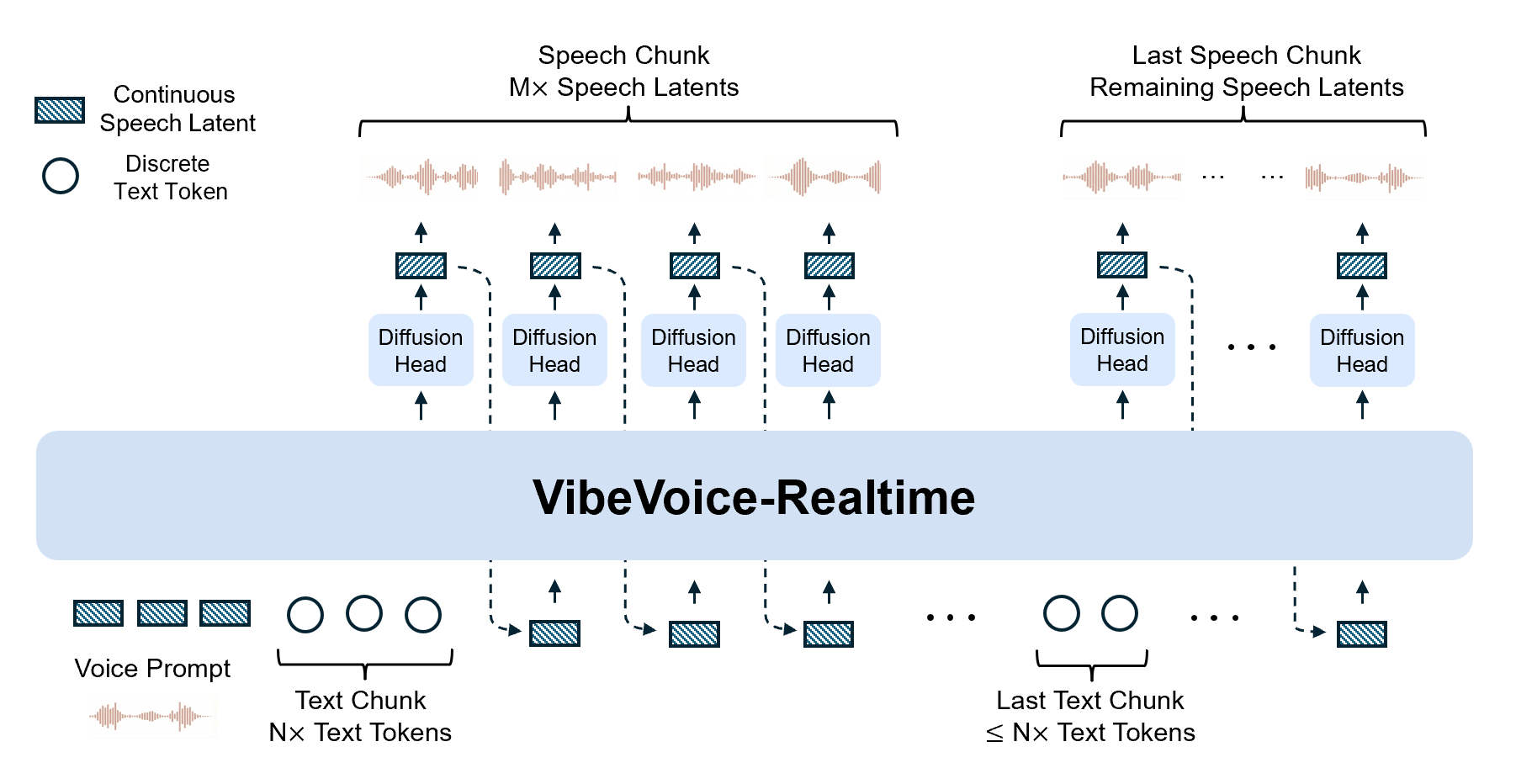
该模型采用交错窗口设计:它逐步编码输入的文本块,同时并行地从先前的上下文中继续进行基于扩散的声学潜在词生成。
与完整的多说话人长文本变体不同,这种流式模型移除了语义分词器,而完全依赖于以超低帧率(7.5 Hz)运行的高效声学分词器。
VibeVoice实时模型主要特点:
- 参数大小:0.5B(便于部署)
- 实时TTS(首次可听延迟约300毫秒)
- 上下文长度大约 8K
- 生成长度可以达到10分钟
- 流式文本输入
- 稳健的长篇语音生成
- 模型参数可以在HG下载
此实时版本仅支持单说话人。如需生成多说话人对话语音,请使用其他 VibeVoice 模型(长篇多说话人版本)。该模型目前仅适用于英语语音;其他语言可能会产生不可预测的结果。
为了降低深度伪造风险并确保首段语音的低延迟,语音提示采用嵌入式格式。
安装与使用
前面提到,这个模型非常小,可以直接在MacBook M4上运行。我这里尝试使用了一下,记录一下过程。
没使用 Docker,直接进行了安装。
从 GitHub 安装
git clone https://github.com/microsoft/VibeVoice.git
cd VibeVoice/
pip install -e .
用法1. 启动实时 WebSocket 演示
注:NVIDIA T4 / Mac M4 Pro 在我们的测试中实现了实时性能;其他推理能力较弱的设备可能需要进一步测试和速度优化。
由于网络延迟,听到音频播放的时间可能会超过第一个语音块生成延迟约 300 毫秒。
python demo/vibevoice_realtime_demo.py --model_path microsoft/VibeVoice-Realtime-0.5B
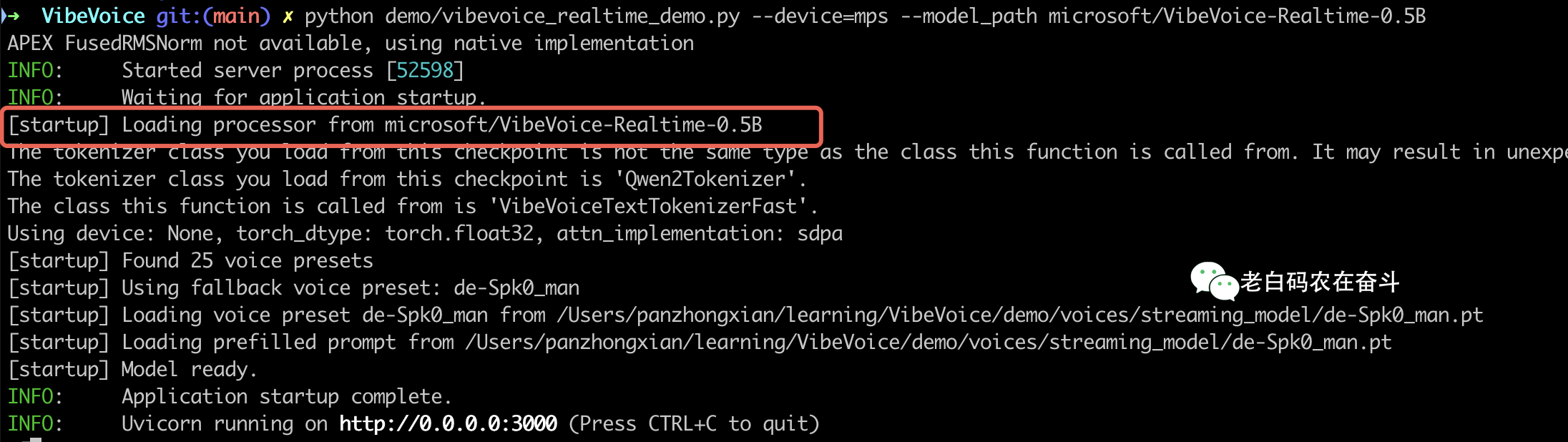
上边的代码,在 MacBook M4 运行会报错,因为 pytorch 默认使用 CUDA,而 MacBook 没有英伟达显卡,所以这里需要加一个选项 --device=mps 表示使用 Apple 的 Metal Performance Shaders (MPS) 框架进行硬件加速。
可以看到在运行服务之前,会先从 HuggingFace 下载模型:
至此,已经启动了 WebSocket 的服务,可以直接通过浏览器进行体验,地址是http://localhost:3000。我这里随便从网上找了个新闻让他朗读一下。
用法2. 直接从文件中推断
项目中还提供了一些对话脚本,可以直接将文本进行转换:
# We provide some example scripts under demo/text_examples/ for demo
python demo/realtime_model_inference_from_file.py \
--model_path microsoft/VibeVoice-Realtime-0.5B \
--txt_path demo/text_examples/1p_vibevoice.txt \
--speaker_name Carter
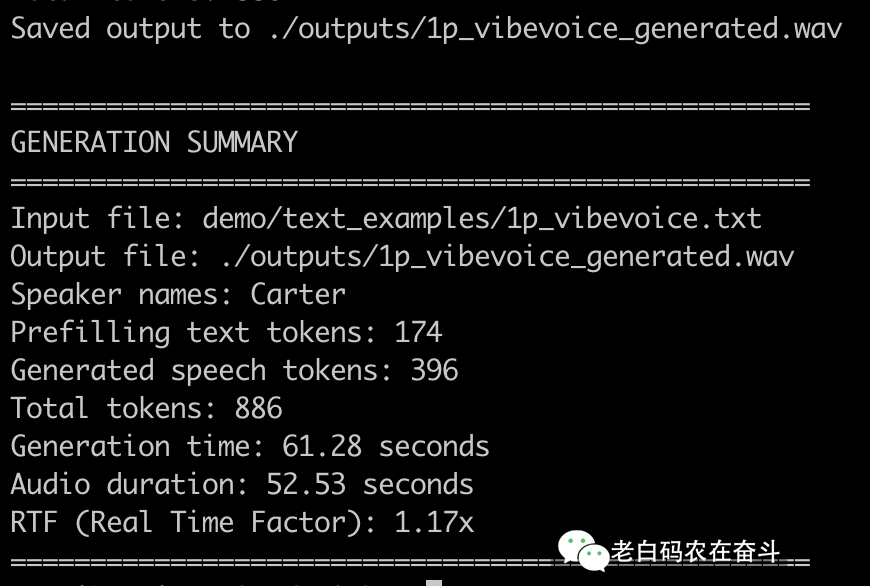
我这里也运行了。通过转换的总结,我们可以看出这个模型真的是非常的实时。
衡量语音合成实时性的关键指标是 RTF (Real Time Factor,实时因子)。
关键指标是 RTF (Real Time Factor,实时因子)。
$$\text{RTF} = \frac{\text{生成音频的耗时}}{\text{音频本身的持续时间}}$$
看到这里的实时因子是 1.17x,虽然略慢于 1.0x。
考虑到我这里只是使用了 M4 芯片,这仍然是非常高效的,特别是对于一个高质量的文本转语音模型而言。
而且,VibeVoice 的核心优势并不在于总体的 RTF,而在于它对流式输入和低首字延迟的支持。
测试结果
该模型在短句基准测试中取得了令人满意的性能,但该模型更侧重于长篇语音生成。
LibriSpeech 测试集上的零样本 TTS 性能
| 模型 | 工作错误率 (%) ↓ | 说话人相似度 ↑ |
|---|---|---|
| VALL-E 2 | 2.40 | 0.643 |
| Voicebox | 1.90 | 0.662 |
| MELLE | 2.10 | 0.625 |
| VibeVoice-Realtime-0.5B | 2.00 | 0.695 |
SEED 测试集上进行零样本 TTS 性能测试
| 模型 | 工作错误率 (%) ↓ | 说话人相似度 ↑ |
|---|---|---|
| MaskGCT | 2.62 | 0.714 |
| Seed-TTS | 2.25 | 0.762 |
| FireRedTTS | 3.82 | 0.460 |
| SparkTTS | 1.98 | 0.584 |
| CosyVoice2 | 2.57 | 0.652 |
| VibeVoice-Realtime-0.5B | 2.05 | 0.633 |
待办事项
- 添加更多声音(扩展可用扬声器/音色)
- 实现流式文本输入功能,以便在音频仍在生成时输入新的标记。
- 将模型合并到 HuggingFace 的官方
transformers存储库中
风险和局限性
README中最后的「Risks and limitations」其实就是免责声明,大家也可以看看。
尽管已尝试通过各种技术对其进行优化,但它仍然可能产生意料之外、有偏差或不准确的输出。VibeVoice 会继承其基础模型(在本版本中具体为 Qwen2.5 0.5b)产生的任何偏差、错误或遗漏。
深度伪造和虚假信息传播的潜在风险:高质量的合成语音可能被滥用,用于创建以假乱真的虚假音频内容,以进行身份冒充、欺诈或传播虚假信息。用户必须确保转录文本的可靠性,核实内容的准确性,并避免以误导性方式使用生成的内容。用户应合法使用生成的内容并部署模型,完全遵守相关司法管辖区的所有适用法律法规。在分享人工智能生成的内容时,最佳实践是披露人工智能的使用情况。
仅限英文:非英文的文字稿可能会导致意外的音频输出。
非语音音频:该模型仅专注于语音合成,不处理背景噪音、音乐或其他音效。
代码、公式和特殊符号:该模型目前不支持读取代码、数学公式或非常用符号。请预先处理输入文本,移除或规范化此类内容,以避免出现不可预知的结果。
输入文本非常短:当输入文本非常短(三个字或更少)时,模型的稳定性可能会降低。
我们不建议在未经进一步测试和开发的情况下将 VibeVoice 用于商业或实际应用。此模型仅供研究和开发用途。请谨慎使用。