实验驱动推荐的服务框架
潘忠显 / 2025-10-23
前两年在做推荐服务的开发,一直使用之前大佬 peterruan 开发的框架。
近期切换使用新框架,于切换之际对老框架做个系统的学习,分享其中设计思想和智慧,优点能得以继续传承。
该框架除了考虑了性能和通用性之外,主要特点是**「算法实验驱动」推荐服务,使得工程人员关注开发插件,而算法同学能便捷地控制使用何种算法模型与参数,真正解耦两类人员的工作。**
1. 实验驱动的推荐服务
这是一个用Go语言开发的推荐系统框架,采用了插件化架构设计,支持召回(Match)、排序(Rank)、重排序(Rerank)等推荐系统的核心流程。该框架为服务框架,具体的排序算法相关,是通过请求额外的模型服务来实现的。
推荐服务整体框架大都类似如下:
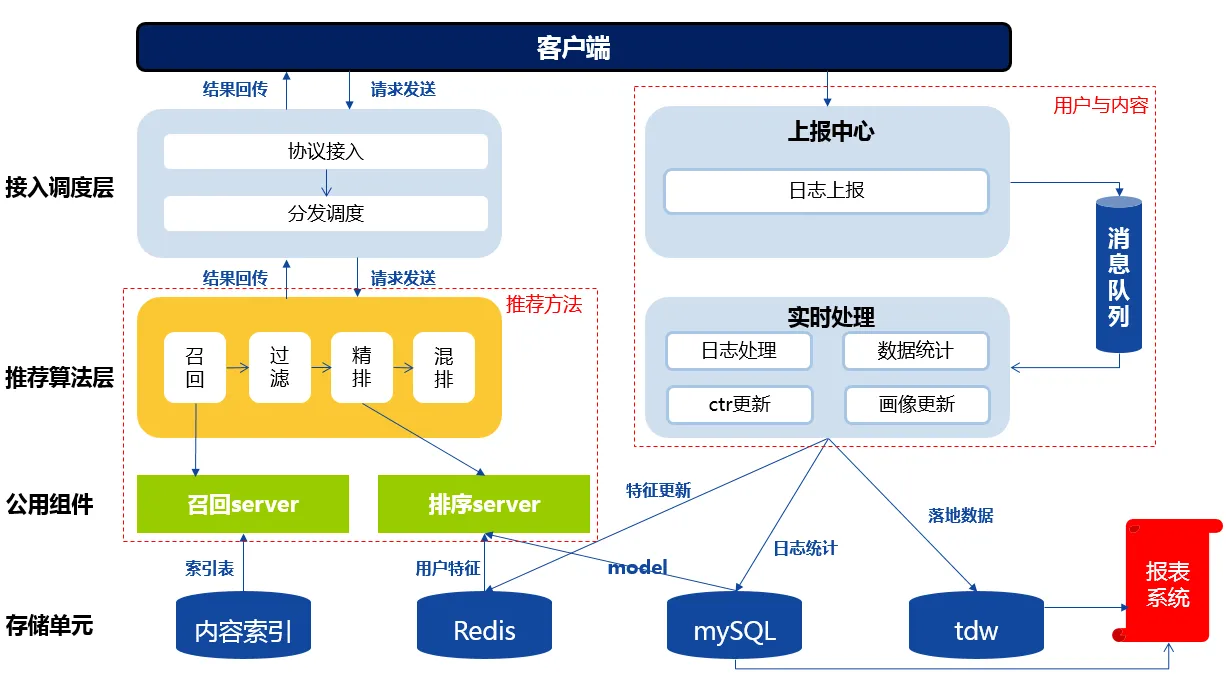
而单独拎出推荐服务部分,其逻辑的大概如下。这里将过滤、精排、混排都抽象为排序,而具体的逻辑包括请求模型、规则排序等:
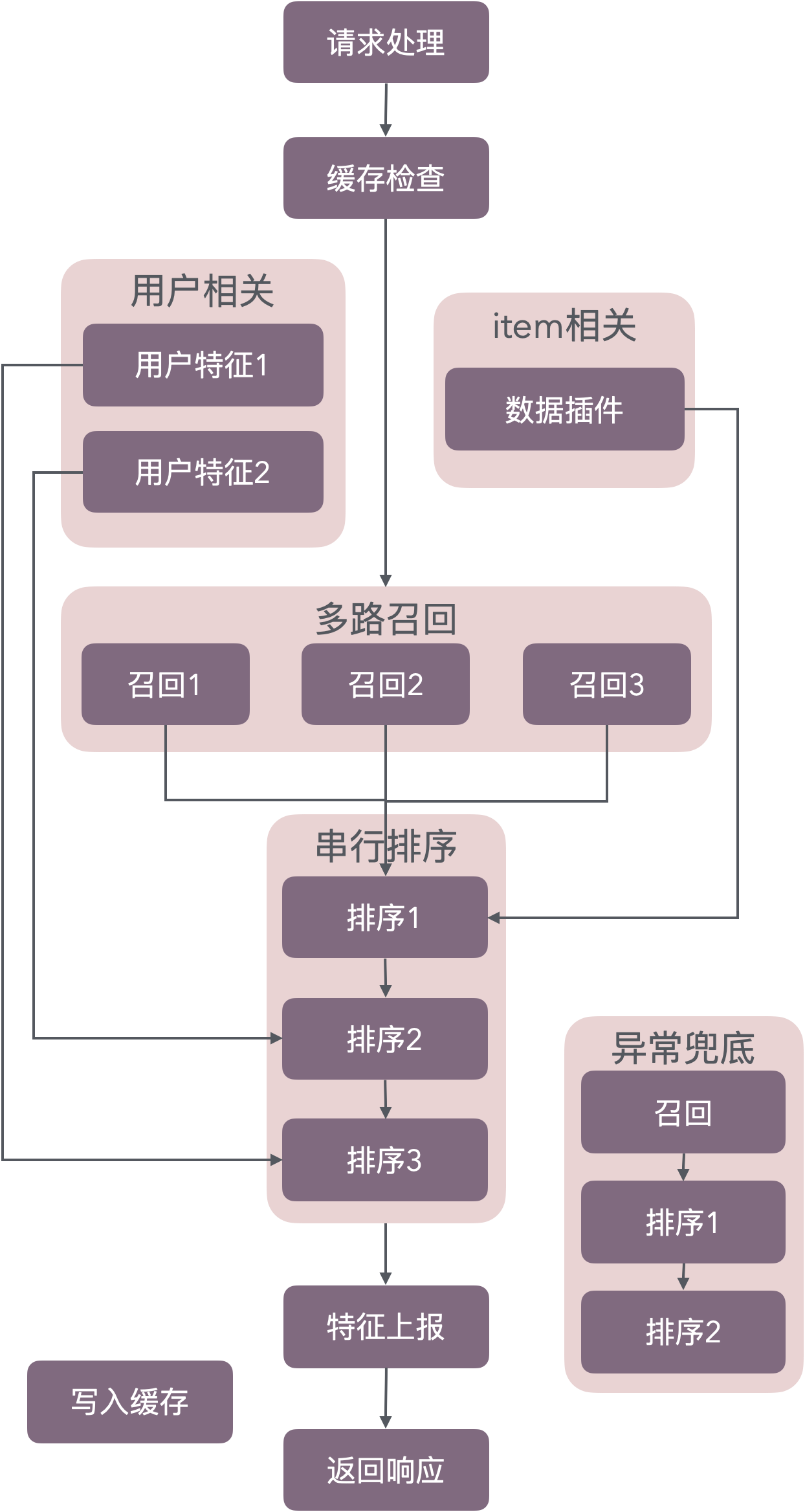
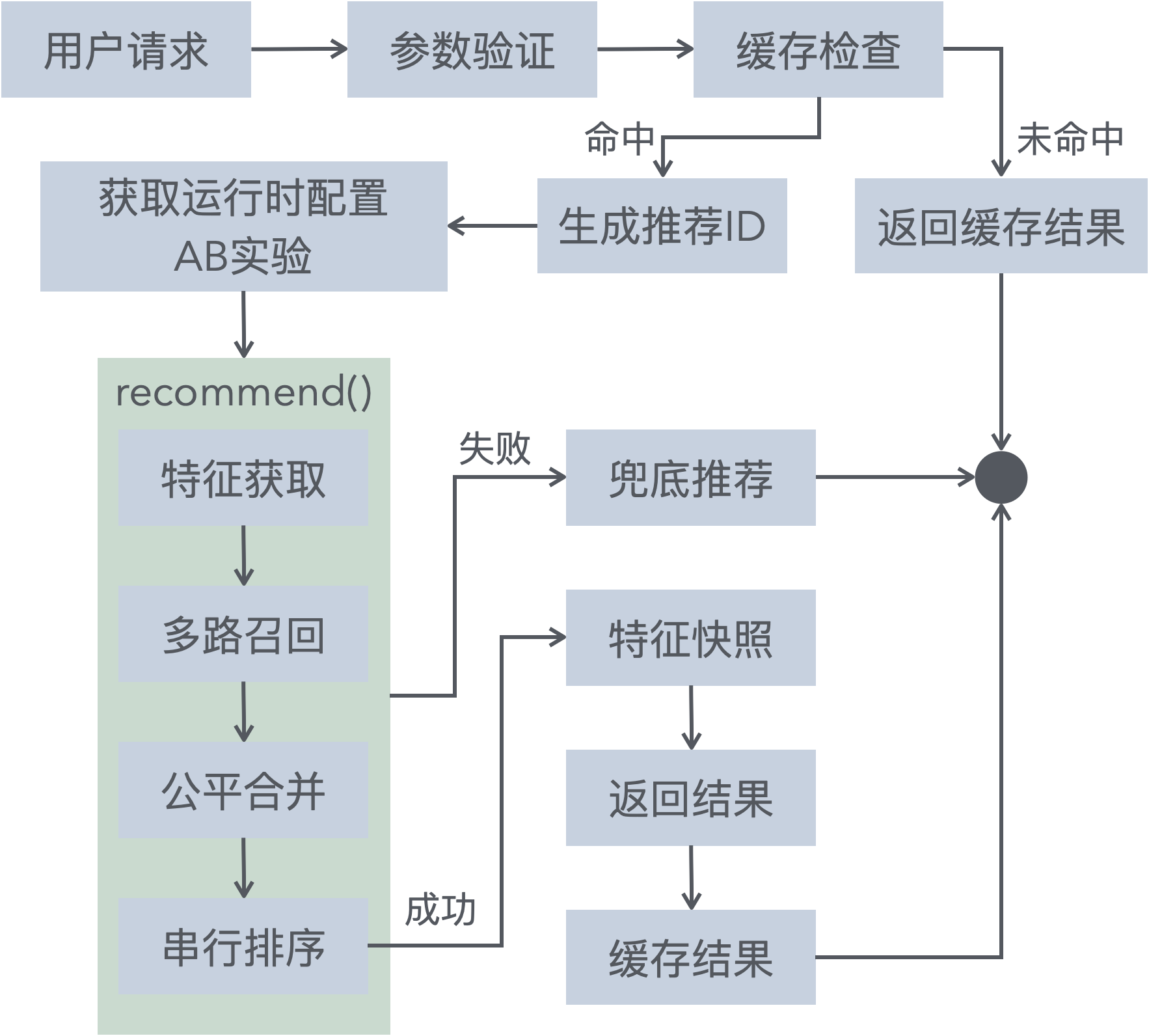
虽然上边的框图表达了推荐的基本流程,但实际过程往往在召回、排序阶段,会通过实验的方式针对不同用户使用多种不同的算法,动态优化推荐服务。实际的请求处理可能是如下(只展示召回、排序相关模块):
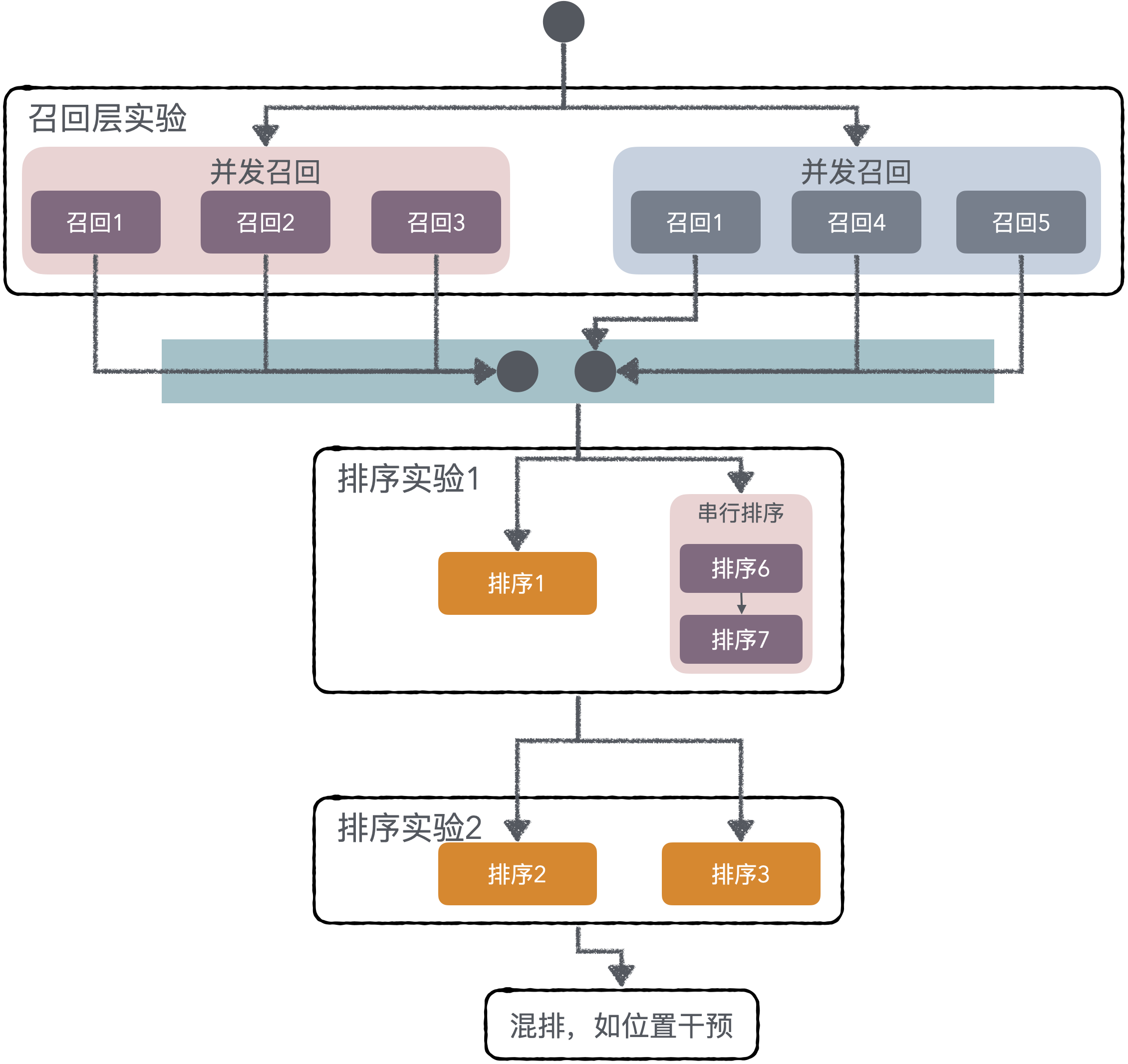
而该推荐服务框架的亮点,就是以「实验配置驱动的推荐服务」为核心思想。上边的推荐服务,只需要做简单配置即可实现。
这种方案让工程人员关注开发插件,而让算法同学能便捷地控制使用何种算法与参数,真正解耦两类人员的工作。
静态配置:server.yaml 定义基础流程——使用的实验APP ID、场景ID、实验名称。
appid: rec-sys-demo
exp: # 实验信息
appid: 1001
sceneid: 101
routine:
- name: match # 固定第1个插件为召回
alias:
- demo_cross_match
- name: prerank # 从第2个开始为排序插件
alias:
- demo_rank_layer1
- name: rank
alias:
- demo_rank_layer2 # 同一层域中,也可能存在多个实验
- demo_rank_layer3 # 不同用户可能命中不同的层域中的不同实验
plugins:
- name: hot # 同一层域中,可能有流量不走实验,使用默认插件
- name: mix # 没有实验,直接指定插件名称
plugins:
- name: demo_cross_mix
动态配置:AB实验平台控制具体策略,以上边的match插件为例:
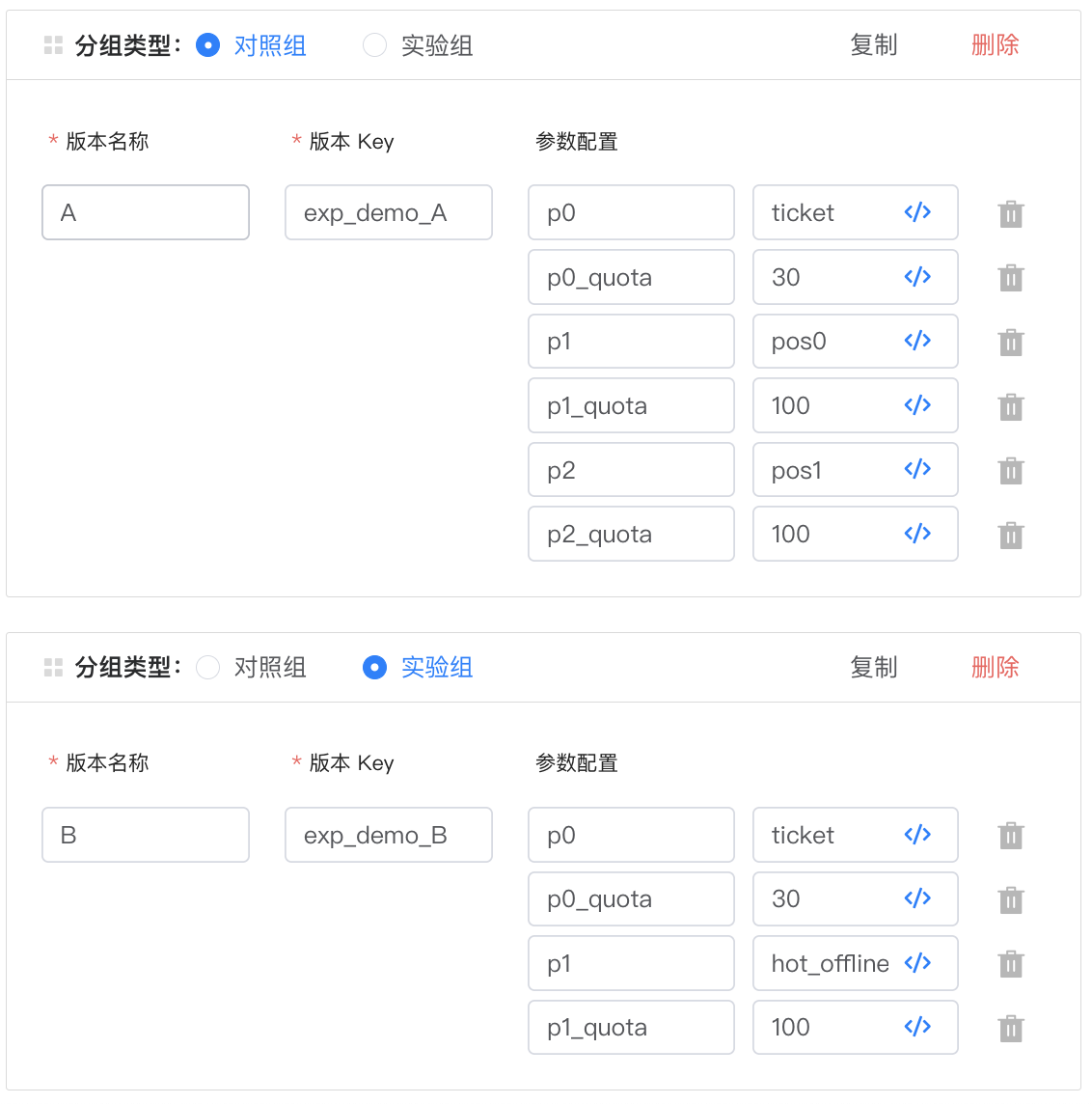
排序插件往往会配置若干参数,参数的格式由所使用的插件决定:

这样个性化的参数配置,非常清晰易于算法同学理解:
{"new_max_cnt":1,"hot_max_cnt":1,"fixed_pos":{"246":7,"250":8,"251":9,"255":12,"269":6}}
除了「实验驱动推荐服务」这一特点之外。框架还有其他一些特点:
- 国内海外无感切换:国内支持TAB实验平台,海外支持ABC实验平台,通过配置切换
- 监控完善:框架 Prometheus 指标 + Zap结构化日志,支持插件暴露个性化指标
- 插件化架构:除了提到的召回、排序插件,还有 Data、Feature、Fallback、Common 等插件类型
- 超时控制:API级别和步骤级别双重超时
- 公平合并:多路召回结果,按照配额分配和去重
- 类型安全:使用Go泛型实现编译时类型检查
- 内置与模型匹配的特征上报,仅需配置 appid 和 dump server 地址即可
- 支持兜底逻辑:通过配置 Fallback 插件,在主流程遇到异常时,返回兜底推荐
- 支持请求返回缓存
在文章的接下来的内容,将对其中的设计和实现,进行详细的介绍。
2. 项目架构概览
下图展示了针对单次请求,一个完整的推荐流程。
配置加载、路由配置、服务监听、插件加载等操作是前序完成的,不在图中展示。
插件类型
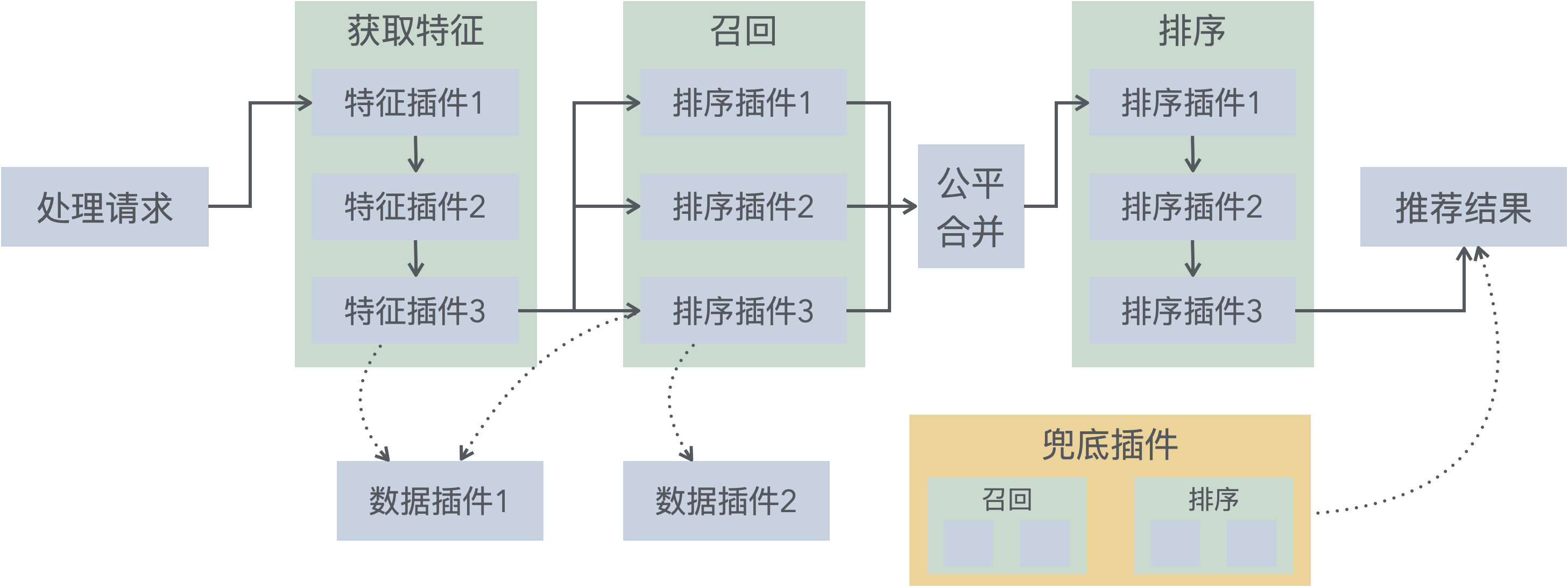
插件类型主要有5种,其关系如图(省略其他无关步骤):
Data插件
数据插件提供缓存、数据存储等基础能力。以全局单例的形式,为其他插件提供服务。
往往是每个请求都会用到的数据,但为了性能不需要每个请求都去获得一次。两个示例使用场景:
- 服务需要的动态配置,比如北极星上的配置,需要定时刷新
- 热销道具的获取,需要周期性拉取
Data插件没有要求 Plugin 之外的任何其他函数实现,所以具体有什么函数,都看其功能需要。
Feature插件
特征插件用于获取用户或者道具的特征,需要在请求之后、召回之前,获取之后通过上下文传递:
- 获得用户特征,比如新老用户、等级、已推荐道具列表等
- 获取物品特征,只限于请求中携带排序道具的场景,获得道具的价格、发布时间等
Feature 插件不能通过实验配置,所有代码指定的都会被串行执行。
Match插件
召回插件可以从不同渠道获得候选道具,所有的 Match 插件将会被并发调用。
插件只能返回召回的道具,不能修改上下文,因为并发可能发生数据竞争。
Match 的结果将会按照指定 Quota 进行配额合并,每个物品除了基本信息之外,还会携带来自哪个召回渠道——插件名称。
Rank插件
排序插件可以根据算法、规则,将召回并合并的物品数组,进行排序。
除了初始化之外,排序插件的排序函数输入和输出均为 []item 数组,因此多个排序插件可以串联。
支持配置多层 Rank 插件,而每层中又可以有多个 Rank。如果配置实验,多层之间就可以产生流量正交的效果。
Fallback插件
兜底插件 跟以上四类插件不太相同,他需要直接实现 Recommend(ctx *Context) (*Response, error) 函数,也就是直接返回对应的响应。
该插件无法配置,最多只能注册一个。用于异常不能返回结果时兜底推荐。
插件间消息传递
前面介绍了不同类型的插件,但是插件与插件之间,如何进行消息传递与流转的呢。主要是通过一个请求级上下文携带和推荐列表。
请求级上下文中
在接收到请求,调用 RecommendWithLog() 函数的时候,会创建一个请求级别的上下文。
其中内容包括:
Ctx context.Context用于控制整个过程中超时,传递框架上下文。RecId string推荐唯一ID,插入到返回中,用于调用端关联请求、上报、问题排查、实验效果分析Uid string用户ID,在特征拉取、召回中通常都会用到Feature SharedFeature共享特征,只允许特征插件写入,其他环节只读Data map[string]any通用的数据存储特征,通过封装函数支持并发读写(封装中使用了上下文中的Lock sync.RWMutex)
除了数据插件之外,其他几个插件的函数都会传递进来 Context:
FeaturePlugin的Fetch(ctx *Context) errorMatchPlugin的Match(ctx *Context, cfg string) ([]ItemBasic, error)RankPlugin的Rank(ctx *Context, cfg string, items []Item) ([]Item, error)

推荐列表
上边的图和函数还展示出了一点,就是单个 Match 插件会产生 []ItemBasic,之后传递给 Rank 插件的则是 []Item。
ItemBasic 中包含了召回的ID,以及该ID的一些属性标签,通过 map 来存储。
Item 是在 ItemBasic 的基础上,加上了Channel 和 Score数组。Channel 用来标识该道具出自哪路召回;Score使用数组则是用来记录不同的 Rank 插件可能对道具进行的打分。
type ItemBasic struct {
Id string `json:"id"`
Tags map[string]string `json:"tags,omitempty"`
}
type Item struct {
ItemBasic
Score []float32 `json:"score,omitempty"`
Channel string `json:"-"`
}
3. 插件深度解析
本节会介绍一下该推荐系统框架的核心概念——插件,以及在此基础上「实验驱动推荐服务」的具体实现。
插件接口设计
插件接口设计比较简洁,所有的插件都要实现 Init() 和 Fini() 方法。Init的两个参数分别是:插件需要加载的初始配置,Prometheus的注册处。这两个变量在 Init 传入,插件如果需要使用,实现时应当使用相应的成员来存储:
// 基础插件接口
type Plugin interface {
Init(cfg []byte, registry *prometheus.Registry) error
Fini()
}
其他三个插件分别在 Plugin 的基础上,分别要求的实现对应的 特征获取 Fetch()、召回 Match()、排序 Rank():
// 特征插件
type FeaturePlugin interface {
Plugin
Fetch(ctx *Context) error
}
// 召回插件
type MatchPlugin interface {
Plugin
Match(ctx *Context, cfg string) ([]ItemBasic, error)
}
// 排序插件
type RankPlugin interface {
Plugin
Rank(ctx *Context, cfg string, items []Item) ([]Item, error)
}
泛型插件管理
框架使用了 Go 的泛型特性,实现了类型安全的插件管理:
type pluginMap[T Plugin] map[string]pluginRecord[T]
type pluginList[T Plugin] []pluginRecord[T]
var(
dataPlugins pluginList[DataPlugin]
featurePlugins pluginList[FeaturePlugin]
matchPlugins = make(pluginMap[MatchPlugin])
rankPlugins = make(pluginMap[RankPlugin])
)
// 类型安全的注册方法
func (m pluginMap[T]) registerOrDie(plugin T, name string, configable bool) {
if initialized {
panic("cannot register after initialized")
}
if _, found := m[name]; found {
panic("plugin name conflict")
}
m[name] = pluginRecord[T]{
name: name,
object: plugin, // 类型T,编译时检查
configable: configable,
}
}
类型安全是指在编译时就能确保类型正确性,避免运行时类型错误。在Go语言中,类型安全意味着:
- 编译时检查:在编译阶段就能发现类型不匹配的问题
- 避免类型断言:不需要在运行时进行类型转换和检查
- IDE支持:更好的代码提示和自动补全
- 减少运行时错误:避免因类型错误导致的 panic
框架使用者如果要注册 Match 插件,无法直接调用未导出的 registerOrDie() 函数,而只能调用封装了该函数的函数,能够保证不会将插件注册错:
// 注册插件 - 编译时类型检查
func RegisterMatchPluginOrDie(plugin MatchPlugin, name string, configable bool) {
matchPlugins.registerOrDie(plugin, name, configable)
}
框架中使用 matchPlugins.get(config) 也能保证获得的类型一定是 MatchPlugin。
插件的初始化和销毁
前边有列出插件接口定义,需要有 Init() 和 Fini() 函数。这些函数是在哪里调用的呢?
服务启动相对比较简单,在监听端口之前,会调用 initPlugins 依次调用各类插件的初始化。而在服务接收到退出信号之后,会先进行HTTP服务的善后工作(关闭HTTP监听端口,停止接收新请求并等待在途请求完成,刷新关闭日志),最后再调用 finiPlugins 依次终止各类插件——通过defer来实现。
if err := initPlugins(cfgDir, registry); err != nil {
fmt.Printf("fail to init plugins: %v\n", err)
return 1
}
defer finiPlugins()
router := httprouter.New()
// call router.Handler, router.HandlerFunc
if err := utils.RunHttpServer(router, fmt.Sprintf(":%d", port)); err != nil {
return -1
}
插件的配置
插件的配置有两种类型:插件初始化时使用一次的初始化配置,每次运行都从实验配置获取的运行时配置。
初始化配置可以选择是否需要配置——configable控制:
func RegisterMatchPluginOrDie(plugin MatchPlugin, name string, configable bool)
配置需要写入到文件中,有一定的命名规则,如上边的 Match 插件注册名如果时 "simple",则需要创建对应的配置 match-simple.yaml 文件。
配置文件在调用插件的 Init(cfg []byte, registry *prometheus.Registry)的方法时被读取,并通过 cfg 变量传入使用。配置内容约定为 yaml 格式。
运行时配置 会在调用 Match、Rank 对应函数时候使用,框架会在拉取对应用户实验信息时,加载该配置,并传入对应函数。
type RankPlugin interface {
Plugin
Rank(ctx *Context, cfg string, items []Item) ([]Item, error)
}
运行时配置通过 string 传入,但其内容序列化取决于插件的实现,实际是一个 URL、一个 JSON、一个Yaml都是可以的。
Q:配置应该如何划分在初始化配置还是运行时配置?
A:需要对算法同学屏蔽的、长期不发生变化的,应当配置在初始化配置中,如 Redis/ES 地址;需要算法同学动态调整的、需实验检验效果的,应当配置在运行时配置中,比如 热销Key的前缀、模型地址等等。实验配置的修改,会实时地影响到推荐服务。
复杂实验的配置支持
在真正生产环境的,使用的实验并非都是简单的AB实验,而是会有复杂的层域设计。
比如下边的这个实验的层域设计,会留出20%的全局对照组,不进行任何的个性化算法推荐干预。实际场景中可能多个活动都会使用这个域作为全局对照组。
同时实验流量被分成两个隔离的域,每个域中会有各自的召回层、排序层。

所有请求到推荐服务的用户,都会被 Hash 到不同的域中,因此需要为不同的域的用户配置不同的插件配置。
这个配置也很简单,有配置实验的,就将插件所在层名配置进去,并配置一个默认的 plugins 供查询不到实验配置的流量,去使用的逻辑。
- name: match
alias:
- domain_1_match
- domain_2_match
plugins:
- name: simple
当然,这个配置可以进行简化——不使用任何实验,可以直接配置 plugins,这样就是一个不需要算法同学干预的服务了。
实验配置加载
上边对复杂实验的支持,是通过根据ExpUID获取实验配置+插件组织来实现,主要逻辑在下边的这个函数中:
// 每次请求都会获取最新的实验配置
func getRuntimeConfig(ctx *Context, req *Request) (*runtimeConfig, error)
对海外ABC和国内IEGAB的兼容,也是在上边这个函数中封装的,配置中通过一个oversea的flag进行控制。
因为实验平台只能配置 key-value 的列表,因此要转换成插件的配置,还需要有额外的约定:
- 插件标号作为 key 从
p0开始查找到p{N},对应 value 是插件名 p{N}_config会作为插件的配置传入- Match 插件还支持配置
p{N}_quota作为限额
# 召回实验配置
p0: items_from_model
p0_config: {"model_version": "v2.1", "top_k": 100}
p0_quota: 50
p1: content_based
p1_config: {"similarity_threshold": 0.8}
p1_quota: 30
# 排序实验配置
p0: collaborative_filtering
p0_config: {"model_version": "v2.0"}
p1: linear_fuse
p1_config: "[0.7, 0.3]"
实验标签追踪
前面的介绍中,有一个概念被反复强调:一个用户可以命中多个实验。用户命中哪个实验,对于分析算法的效果非常重要。
我们算法同学有两种方式关联人和实验:
- 通过实验曝光表,会记录某个UID在某个实验配置中,属于哪一个分组
- 推荐结果返回中会携带明中的实验标签,由调用方进行上报
这两种方式以后者更为精准,比如一些预拉取的场景下,推荐服务的结果并不一定真正的展示给用户。
框架中会自动在拉取用户实验时填充实验标签信息。因为可能有多个,所以使用数组进行保存:
func Recommend(req *Request) (resp *Response, err error)
// 系统会自动记录实验标签,便于效果分析
type Response struct {
RecId string `json:"recid"`
Items []RespItem `json:"items"`
ExpTags []string `json:"exp_tags,omitempty"` // 实验标签
}
实验标签示例:
["match:collaborative_v2:exp_a", "rank:tfctr_v2:exp_b"]
4. 多路召回与公平合并
出于对整体推荐延迟的考虑,框架中使用并发执行所有的召回插件。而多路召回之后如何选择这些结果,框架采用了一种公平合并的方法。
并发过程
Match的过程可以配置一个整体超时,框架实现上看上去比较巧妙,就是在并发调用Match插件之前,将请求级别上下文中的 context.Context 进行了替换:
if matchTimeout > 0 {
tCtx, cancel := context.WithTimeout(ctx.Ctx, matchTimeout)
defer cancel()
ctx.Ctx, tCtx = tCtx, ctx.Ctx // 临时换掉
defer func() { ctx.Ctx = tCtx }()
}
但是这种实现方式是有问题的。如果本身服务超时设置的比 matchTimeout 短,会造成服务的响应的耗时可能比总体的超时时间长。可以改为判断 remaining 和 matchTimeout 的大小再决定是否替换。
其他一些细节:
- 并发之前创建数组,来让每个goroutine有独立的数据空间来保存召回结果和错误,而无需使用锁
- 每个协程中会统计单个插件的延迟
- 并发完成之后,会统计 Match 阶段的延迟
公平合并算法 (fairMerge)
框架针对多路召回的情况,即只要不是所有召回路都失败,就不认为是失败。接下来,我们考虑如何合并多路召回的结果。
召回源再配置的时候,都支持配置独立的 Quota 配额,当然这个 Quota 可以为0。框架采用了一个非常精妙的设计,确保各召回通道按配额公平分配。
并发召回之后,根据配额缺口——quota - len(result)——从大到小排序,然后使用两个链表 main 和 rest 来保存未满足配额的和已满足配额的召回源。
输入:
- 源A: quota=3, list=[item1,item2,item3,item4,item5] (缺口=3-5=-2)
- 源B: quota=2, list=[item6,item7] (缺口=2-2=0)
- 源C: quota=0, list=[item8,item9,item10] (缺口=0-3=-3)
排序后:源B → 源A → 源C (按缺口从大到小)
分类后:
有配额 main队列: 源B → 源A (有配额)
无配额 rest队列: 源C (无配额)
接下来优先满足有配额的数据源,遍历 main 队列,从其中数据源取出一个元素,并将配额减1,如果某个数据源的配额降低到0,则移入 rest 队列:
第1轮:从源B取item6,配额变为1
第2轮:从源A取item1,配额变为2
第3轮:从源B取item7,配额变为0 → 源B移到rest队列
第4轮:从源A取item2,配额变为1
第5轮:从源A取item3,配额变为0 → 源A移到rest队列
满足完有配额的数据源之后,再处理候补 rest 队列,继续补充召回结果:
rest队列: 源A(item4,item5) → 源C(item8,item9,item10)
第1轮:从源A取item4
第2轮:从源C取item8
第3轮:从源A取item5
第4轮:从源C取item9
第5轮:从源C取item10
总结下来其主要特点包括:
- 配额优先分配:初次分配按配额,确保每个通道都能获得应有的份额
- 公平轮询:在满足配额的前提下,公平地从各个源取数据
- 去重处理:使用
book映射避免重复推荐 - 候补机制:配额用完后进入候补队列,为了考虑总量,可以使用后补队列继续补充
召回结束之后,每个物品都会标记来源渠道 (Channel)——也就是上边提到的源,便于后续排序、分析和调试。
5. 通用插件
除了核心的推荐框架功能外,项目还开发了丰富的通用插件。设计这些通用插件,也是为了更高效的开发。
这些插件按照功能,又可以区分成 3 类:
- 功能明确,避免重复开发,比如 Shuffle插件,提供物品随机打乱功能,支持加权随机。
- 功能通用,解耦服务功能和召回、排序逻辑,比如 TFCTR 插件可以请求模型服务排序,Remote召回插件可以请求HTTP服务获得召回内容。
- 功能基础,实现者可以在此基础上,快速实现功能更复杂的插件。比如 Cache 插件封装了Redis 获取、设置、过期等操作,可以继续封装
这些通用插件使用起来非常灵活,既可以直接配置,又可以作为别的插件的一部分被调用。因为这些通用插件,大多初始化无需任何初始化配置,而一些必要的参数又直接通过 Rank() 或 Match() 的配置传递。
通用插件列表
按照前面介绍的插件类型,这些插件覆盖了推荐系统的数据存储、特征处理、召回、排序、监控等各个环节。
- 数据插件(Data Plugins)
- Cache插件 - 封装了Redis的获取、设置、过期等操作,支持压缩和自定义缓存键策略
- TDBank插件 - 封装了日志上报功能,通过CGO调用TDBank C++库进行异步数据上报
- 特征插件(Feature Plugins)
- Extra Log插件 - 根据用户ID动态调整日志级别,实现精细化日志控制
- 召回插件(Match Plugins)
- Static插件 - 基于YAML配置的静态物品列表召回
- Sorted插件 - 基于Redis的离线推荐召回,支持全局和个性化模式
- Remote系列插件:调用远程召回服务,支持 HTTP JSON协议、tRPC协议、HTTP Protobuf协议
- 排序插件(Rank Plugins)
- Filter插件 - 按物品ID列表过滤推荐结果
- Fillback插件 - 将过滤的物品重新加入推荐列表
- Shuffle插件 - 物品随机打乱,支持加权随机
- Noise插件 - 在推荐列表中注入噪声增加随机性
- Probe插件 - 监控和统计推荐结果的分数分布
- Rectify插件 - 基于离线排序结果矫正在线推荐列表
- Linear Fuse插件 - 线性融合多个分数,支持多模型融合
- TFCTR系列插件:调用TFCTR排序服务,支持 HTTP JSON协议、tRPC协议、HTTP Protobuf协议
- Rerank系列插件:调用重排序服务,支持 HTTP JSON协议、tRPC协议、HTTP Protobuf协议
- 兜底插件(Fallback Plugins)
- General Fallback - 通用兜底插件,支持配置召回和排序
- General Fallback V2 - 支持多路召回的兜底插件
远程调用插件
TFCTR 应该是 TensorFlow Controller 的缩写,这系列插件用于通过网络调用 TensorFlow 模型排序服务。
所有涉及的代码都在 plugins/rank/tfctr/ 目录中。
这个目录中有三个类似的插件,他们分使用不同的协议调用TFCTR排序服务:
- Simple - HTTP JSON协议
- Standard - tRPC协议
- Hybrid - HTTP Protobuf协议
类似的插件还有召回的Remote插件、排序中的Rerank插件都是通过远程调用获得结果,都支持多种协议。
6. 与模型服务的交互
调用模型服务是推荐系统的常规操作。该推荐框架将对模型的调用,除了做了上边 tfctr 的插件封装之外,还有特征上报等操作。
对于上边的 TensorFlow 的服务我们后边有机会再介绍,该服务相对通用,启动之后,都会支持 .proto 中定义的三个接口:
service Predictor {
// 单次评估
rpc Evaluate(EvaluateRequest) returns (EvaluateReply) {}
// 批量排序
rpc Rank(RankRequest) returns (RankReply) {}
// 特征上报
rpc DumpFeature(DumpFeatureRequest) returns (DumpFeatureReply) {}
}
这里的单个评估接口在框架中通常不会用到。
Rank 接口会被封装在排序插件中进行 RPC 调用,比如 tfctr 的 StandardPlugin 插件的 Rank() 函数实现中:
proxy := pb.NewPredictorClientProxy(client.WithTarget(cfg))
resp, err := proxy.Rank(ctx.Ctx, req)
而特征上报函数 DumpFeature(),不是通过TFCTR插件调用,而是框架直接调用.
框架通过读取配置文件中的 dump_server 配置,异步创建一个独立的 proxy 来调用 DumpFeature 接口:
if dumpServer.trpc {
proxy := pb.NewPredictorClientProxy(client.WithTarget(dumpServer.address))
_, err = proxy.DumpFeature(context.Background(), obj)
} else {
err = adapter.HttpPostPb(context.Background(),
dumpServer.address, "/dump-feature", obj, nil)
}
特征上报的内容包括:应用ID、用户信息、上下文信息(包括命中的实验配置)、推荐结果列表等。收集的数据会被用于:离线模型训练、效果分析和评估、特征重要性分析、推荐策略优化等方面。
框架中对特征上报,只支持配置一个服务地址,即使服务中有多个模型的调用。但是这大部份情况下是可以满足的,因为对于同一场景,不同的模型多是参数不同,而使用的特征类似。
当然这个配置可以留空,就不进行特征上报。
7. 兜底插件
当主推荐流程失败时,即 recommend() 函数返回错误时,框架会判断是否有兜底插件,如果存在则会运行返回提供备用方案。
recommend() 报错可能是推荐过程中任何一个步骤报错:
- 实验配置获取失败:当
getRuntimeConfig()返回errFallback时 - 特征获取失败:当
fetchFeatureWithPlugins()失败时 - 召回失败:当
matchAndMerge()失败时 - 排序失败:当
rank()失败时 - 超时:当
recommend()超时时
Fallback 插件,类似是将框架的 recommend() 函数删繁就简的一个浓缩版本:
- 可以配置单路/多路召回,支持多路排序
- 去掉了可能导致失败的非核心步骤(实验配置、特征获取、特征上报)
通常在 Fallback 中要配置一些相应更快的召回和排序,比如固定规则召回、随机排序等,这样能够减少依赖、降低失败率。这样能在异常情况下,专注于可用性而非质量。
8. 框架通用特点
该框架也采纳了其他很多框架的一些优点,这里简单一提。
技术栈
- 语言: Go 1.19+ (使用泛型特性)
- Web框架: 自定义HTTP服务器 + httprouter
- 配置管理: YAML配置文件
- 监控: Prometheus + Grafana
- 缓存: Redis
- 实验平台: 腾讯TAB / 海外ABC
- 服务发现: 支持北极星、南天门网关、ODP地址等
- 日志: Zap + Lumberjack
日志系统特性
- 结构化日志:使用Zap进行结构化日志记录
- 日志轮转:使用Lumberjack进行按大小或按天的日志轮转,自动压缩历史日志
- 动态日志级别:除了直接配置,也支持HTTP接口动态调整日志级别,
PUT /loglevel DEBUG - 链路追踪:通过为每个请求分配的唯一trace ID,来串联日志
监控体系
- 系统监控:请求量、延迟、错误率
- 插件监控:各插件自定义指标
- 延迟分布统计与状态监控:请求级、步骤级、插件级
请求-步骤-插件三层监控体系。
9. 总结
该推荐系统框架通过实验驱动的设计理念,实现了工程与算法的有效解耦。框架采用插件化架构,支持召回、排序、重排序等核心流程的灵活配置,让算法同学能够通过AB实验平台便捷地控制算法选择与参数调优,而工程人员则专注于插件开发,真正做到了职责分离。
本文介绍了框架的一些实现细节,充分了解该框架的基础上,掌握其设计亮点,可以应用于其它系统的设计。