MiniMind 学习笔记(二) - Tokenization
潘忠显 / 2025-10-30
在大型语言模型(LLMs)处理人类语言的复杂过程中,将文本转化为机器可处理的数值格式是首要任务。而Tokenization(分词/标记化),正是这一转换流程的开端,它是所有后续处理(包括 Embedding 和 Padding)的基础。
本文先介绍 Tokenization 的定义,然后介绍一下跟 Embedding 和 Padding的关系,最后结合 MiniMind 的代码介绍一下 Tokenizer 的使用。
一、Tokenization:构建语言的最小单元
Tokenization(分词) 是处理文本输入的第一步,它的任务是将连续的文本字符串拆解成更小的、可管理的、离散的单元,这些单元被称为 Token(标记)。
Tokenizer(分词器)是将文本转换为模型可理解格式的工具。它完成两个核心任务:
- 文本分割:将句子拆分成更小的单元(tokens)
- 编码映射:将每个 Token 映射到唯一的整数 ID,该映射关系是模型的固定词汇表(Vocabulary)。
一个 Token 可以是一个完整的词、一个词的一部分、一个标点符号,甚至是一个字符。
以文本输入:“The mouse ran up the clock.” 为例,其分词后得到一个 ID 序列:
"The", "mouse", "ran", "up", "the", "clock", "."
对应 ID 序列:
[123, 456, 789, 101, 123, 112, 999]
分词技术
传统的字符级和词语级分词方法存在词汇表过于庞大或无法有效处理集外词(Out-of-Vocabulary, OOV)的局限性。为了解决这些问题,现代 LLMs 普遍采用了子词分词(Subword Tokenization)技术。这种方法的核心思想是将一个词拆解成更小的、有意义的片段(子词),从而达到兼顾词汇量大小和解决 OOV 问题的目的。
字节对编码 (Byte-Pair Encoding, BPE) 最早是一种用于数据压缩的算法,后来被引入自然语言处理领域。它的工作原理是迭代地统计训练语料库中出现频率最高的相邻字节对(byte pair),并将这个最高频的字节对合并成一个新的子词,直到达到预定的词汇表大小时为止。这种方法简单高效,能够将常用词作为整体 Token 保留,同时将罕见词拆分成已知子词序列,彻底解决了 OOV 问题。因此,BPE 广泛应用于许多流行的 Transformer 模型,如 GPT 系列、BART 等。
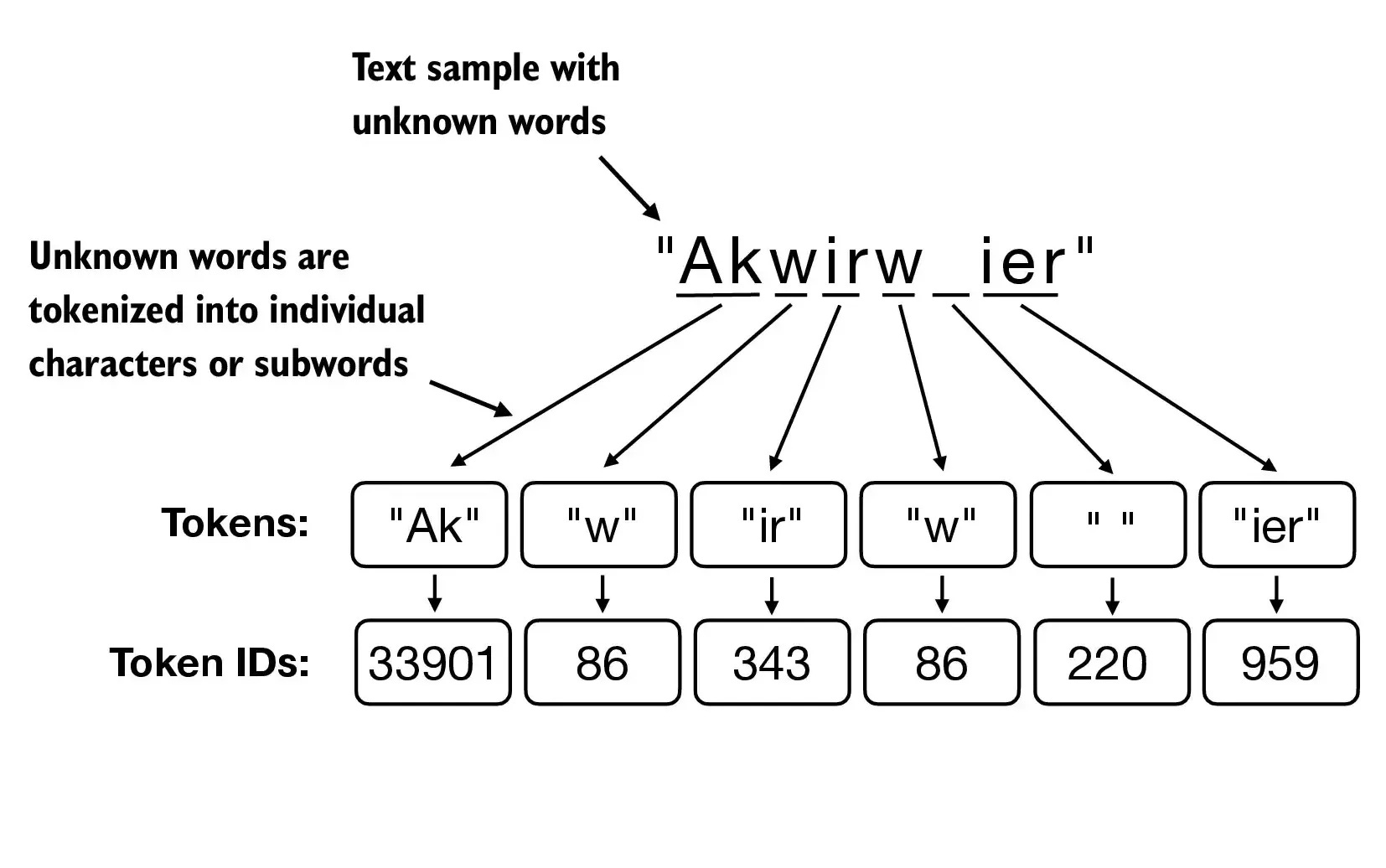
WordPiece 由 Google 提出,并在其模型中得到广泛应用。与 BPE 类似,但 WordPiece 合并的依据是选择合并后能使语料库的对数似然(Log-Likelihood)增加最大的相邻子词对。WordPiece 在合并子词时会考虑到合并后对整个语料库语言建模的贡献,通常能产生更优化的词汇表。因此,著名的 BERT、DistilBERT 和 T5 等模型都采用了 WordPiece 分词器。
Padding
深度学习模型,特别是 LLMs 中使用的 Transformer 架构,为了提高计算效率,通常采用批量处理(Batch Processing)的方式。这意味着模型会同时处理多条输入文本(例如 8 条或 16 条句子)。但经过 Tokenization 后的不同句子,其 Token 数量往往是不同的。
由于计算机在处理数据时需要统一、矩形的张量格式,这种长度不一的序列无法直接堆叠在一起进行高效的矩阵运算。因此,需要一种机制来统一批次内所有序列的长度。
Padding(填充) 就是用于解决这一问题的预处理技术。它在逻辑上是紧接在 Tokenization 之后的步骤,作用于 Tokenization 的整数 ID 序列,操作添加的是 Token ID(本项目中约定为 0,即 <|endoftext|> 作为 pad),而不是 Embedding 向量。注意:项目中 <|endoftext|> 同时被用作 pad_token 与 unk_token,而生成结束标记(eos)为 <|im_end|>。
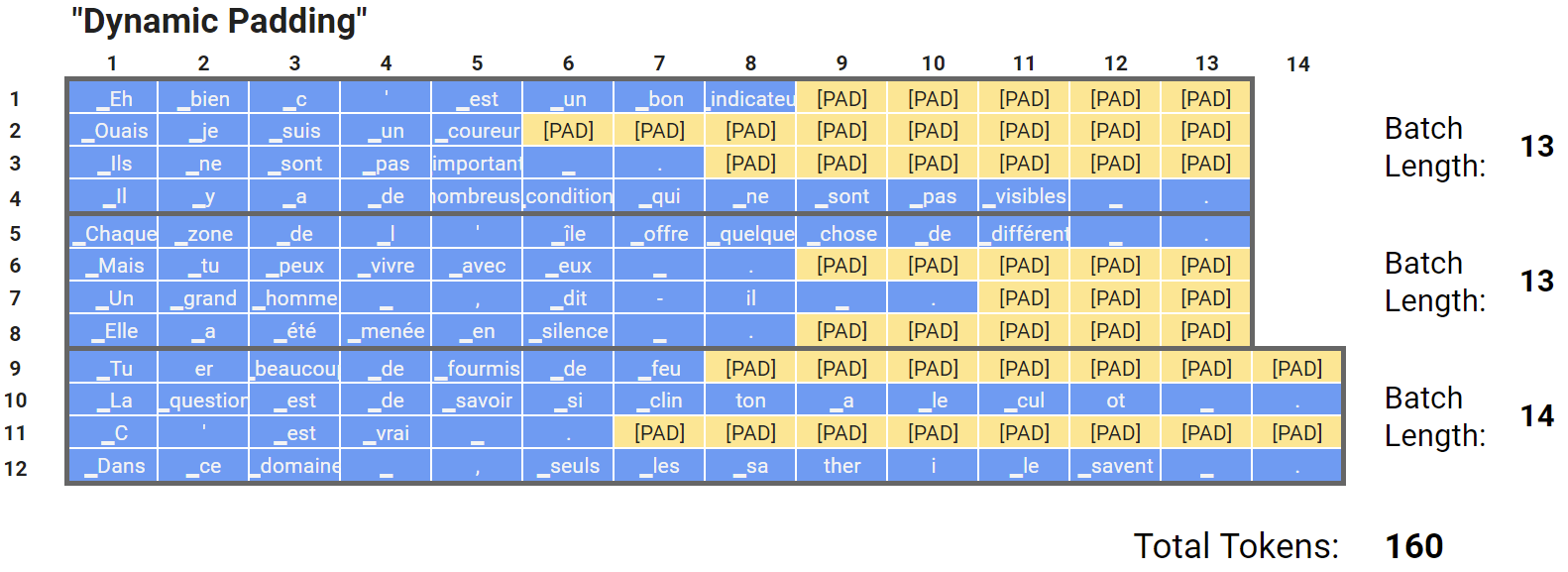
这些填充 ID 在进入 Embedding 层后,会查找对应的填充 Embedding 向量(通常是全零向量),但模型在后续的注意力计算中,会使用注意力掩码(Attention Mask)来告诉模型忽略这些填充位带来的计算结果,确保它们不影响真正的语义内容。
二、与 Embedding 的联系
前面简单介绍过《什么是Embedding》,其核心价值在于它能捕捉词语的语义(Meaning)和上下文关系(Contextual Relationship)。在嵌入空间中,意义相近的词语,其对应的向量在空间中的距离会更近。
很多资料会这样介绍:Tokenization 和 Embedding 是文本处理流水线中承上启下的两个连续步骤。Tokenization 的输出(Token ID 序列)直接作为 Embedding 步骤的输入,每个 Token ID 对应一个在嵌入查找表(Embedding Lookup Table)中预先训练好的向量,模型通过查找这个表来获取每个 Token 的初始 Embedding 向量。
这样介绍,很容易让人迷惑:token ID 是怎么查询出来的?Embedding 查询表又是哪来的?如果 token ID 映射错了,Embedding 结果还可靠吗?
训练和推理场景下的区别
事实上,所谓「Token ID 查询 Embedding 查询表」的过程是对推理过程的描述。例如,单词 “mouse” 首先被映射成 Token ID 456;然后,查询 Embedding 查找表,得到一个由浮点数组成的向量表示:
[-0.15, 0.62, 0.11, ..., 0.99];最后,使用该向量作为模型输入进行推理。
而在训练过程中,输入文本可能会按照固定的关系被映射成 Token ID 序列;然后,Token ID 序列作为 Embedding 层的输入,模型通过学习不断调整 Embedding 向量,使其更好地捕捉词语的语义和上下文关系;最后,训练结束会得到一个预训练好的 Embedding 查找表。
搞清楚 Tokenizer 和 Embedding 在训练和推理中的交互后,我们就能理解它们必须配套使用的原因了。
这些配套包括:
- 训练与推理应使用相同 Tokenizer
- Tokenizer 与 Embedding 配套使用
- 预训练与微调需保持一致
Tokenizer 和 Embedding 封装在一起
实际上很多库,会将上边两个步骤封装在一起,例如 HuggingFace 的 Transformers 库。

前面介绍过该库使用方法,可以调用 model.encode(sentences) 一个函数完成两步操作:
from sentence_transformers import SentenceTransformer
# 1. Load a pretrained Sentence Transformer model
model = SentenceTransformer("all-MiniLM-L6-v2")
# The sentences to encode
sentences = [
"The weather is lovely today.",
"It's so sunny outside!",
"He drove to the stadium.",
]
# 2. Calculate Embeddings and print
Embeddings = model.encode(sentences)
print(Embeddings)
在首次运行代码的时候,我们可以看到会先下载Tokenizer的配置和Embedding的模型:

三、MiniMind 中的 Tokenization
本节结合 MiniMind 项目中的 train_pretrain.py,学习一下如何做 tokenization,以及如何训练 Embedding。
主函数中的逻辑非常的清晰,我这里去掉了 ddp 相关的几行内容,展示一下主函数:
model, tokenizer = init_model(lm_config)
train_ds = PretrainDataset(args.data_path, tokenizer, max_length=args.max_seq_len)
train_sampler = None
train_loader = DataLoader(
train_ds,
batch_size=args.batch_size,
pin_memory=True,
drop_last=False,
shuffle=(train_sampler is None),
num_workers=args.num_workers,
sampler=train_sampler
)
scaler = torch.cuda.amp.GradScaler(enabled=(args.dtype in ['float16', 'bfloat16']))
optimizer = optim.AdamW(model.parameters(), lr=args.learning_rate)
iter_per_epoch = len(train_loader)
for epoch in range(args.epochs):
train_sampler and train_sampler.set_epoch(epoch)
train_epoch(epoch, wandb)
上边过程分为三个阶段
- 初始化
init_model(),PretrainDataset- init_model(lm_config):从 ../model/ 加载 AutoTokenizer 的配置与词表,构建 MiniMindForCausalLM 模型并移动到 args.device,返回 model, tokenizer。
- 加载数据
DataLoader - 训练循环,外层按 epochs 循环,逐 epoch 调用 train_epoch
接下来继续详细看看。
1. 初始化阶段
init_model() 的函数定义如下:
def init_model(lm_config):
tokenizer = AutoTokenizer.from_pretrained('../model/')
model = MiniMindForCausalLM(lm_config).to(args.device)
return model, tokenizer
tokenizer 使用 AutoTokenizer.from_pretrained('../model/') 从 ../model/ 目录加载 tokenizer 的配置,构建 Tokenizer 对象。
model 目录下有配置文件:tokenizer.json,这是使用 tokenizers 库训练得到的 Tokenizer 主文件,包含了 处理策略、BPE 模型的词表、合并规则。
"decoder": {
"type": "ByteLevel",
"trim_offsets": true,
"use_regex": true
},
"model": {
"type": "BPE",
"vocab": {
"<|endoftext|>": 0,
"<|im_start|>": 1,
"<|im_end|>": 2,
"!": 3,
"\"": 4,
"#": 5,
...
},
"merges": [
[ "Ġ", "t" ],
...
可以看到这里 vocab 中只有大概6000多映射,如何处理中文呢?
- 在预处理时会将输入文本先按 UTF-8 拆成字节流,并做 ByteLevel 的偏移管理。
- 使用 BPE。在字节序列上按训练得到的「合并规则」反复合并,得到若干子词 token。
- 最终得到的每个子词 token 按 vocab 字典查表,映射到唯一的整数 ID。
在反向解码(decoder)中,使用 ByteLevel 解码器把 token 序列还原为原始字节,可以还原出中文。实际实现中使用 ByteLevel 预分词与解码,且 add_prefix_space=False(详见 scripts/train_tokenizer.py)。
数据集里真正把文本转为 token IDs 的调用位置,是在 Dataset 的 __getitem__ 中用 tokenizer 完成的:
# 预训练数据集
class PretrainDataset(Dataset):
def __getitem__(self, index):
sample = self.samples[index]
# 构建输入文本
encoding = self.tokenizer(
str(sample['text']),
max_length=self.max_length,
padding='max_length',
truncation=True,
return_tensors='pt'
)
input_ids = encoding.input_ids.squeeze()
loss_mask = (input_ids != self.tokenizer.pad_token_id)
# 构造自回归训练数据(对齐为预测下一个token)
X = input_ids[:-1]
Y = input_ids[1:]
loss_mask = loss_mask[1:]
训练时按位应用 loss_mask 忽略 padding 位置的损失:
loss = loss_fct(logits.view(-1, logits.size(-1)), Y.view(-1)).view(Y.size())
loss = (loss * loss_mask).sum() / loss_mask.sum()
model 目录下还有另外一个文件:tokenizer_config.json,其中有特殊 token 的映射:
| Token | ID | 作用 | 使用场景 |
|---|---|---|---|
<|endoftext|> |
0 | Padding/UNK | 用于 padding='max_length',未知词替代(unk),解码可跳过 |
<|im_start|> |
1 | 开始标记(BOS) | Chat 模板中标记角色开始(system/user/assistant) |
<|im_end|> |
2 | 结束标记(EOS) | Chat 模板中标记角色结束、生成停止条件 |
注:配置中 unk_token 亦为 <|endoftext|>,而生成的结束标记为 <|im_end|>。
还有定义聊天消息格式的模板 chat_template,这个在与训练中没有用,在 SFT 的数据加载时有使用:
SFTDataset.__getitem__()
-> SFTDataset._create_chat_prompt ()
-> tokenizer.apply_chat_template(..) # 使用到chat\_template
MiniMind 使用 ChatML 格式的对话模板,用于结构化对话数据。将对话结构化成下边这样:
<|im_start|>system
You are a helpful assistant<|im_end|>
<|im_start|>user
你好<|im_end|>
<|im_start|>assistant
你好!有什么可以帮助你的吗?<|im_end|>
2. 预训练的训练阶段
前面提到说,Token ID确定之后,还需要训练 Embedding 模型,但是 MiniMind 的训练虽然也会训练 Embedding,但是没有将其单独的存放和暴露。
训练会更新词嵌入层(token embedding),因为交叉熵损失的反向传播会流到 embed_tokens.weight(且与 lm_head.weight 绑定在一起,权重共享)。
在 MiniMindForCausalLM 中定义并权重共享,在每步 loss.backward()、optimizer.step() 时被更新。
结果是模型里的“嵌入矩阵”(大小约为 vocab_size × hidden_size),不是单独产物。随整体模型 state_dict 一起保存在训练脚本定期保存的 checkpoint 文件里,如 .../out/pretrain_512.pth。
3. SFT 数据 Tokenizing
SFT 训练时,其 Tokenization 跟 PreTrain的略有不同,主要体现在 SFTDataset.__getitem__() 函数中。
def __getitem__(self, index):
sample = self.samples[index]
# 1. 构建对话提示(使用 chat template)
prompt = self._create_chat_prompt(sample['conversations'])
# 2. Tokenize
input_ids = self.tokenizer(prompt).input_ids[:self.max_length]
# 3. 填充到固定长度
input_ids += [self.tokenizer.pad_token_id] * (self.max_length - len(input_ids))
# 4. 生成损失掩码(只对assistant回答计算损失)
loss_mask = self._generate_loss_mask(input_ids)
其中 loss_mask 的生成通过在 token 序列中匹配 bos_token + 'assistant' 到 eos_token 的片段,仅对助手回答内容(且跳过回答起始的第一个 token)计入损失,其他位置为 0。这样可以确保仅监督助手回复,不对提示部分和其他角色内容回传梯度。
4. 推理阶段
推理阶段的对输入的 Tokenization 过程与训练阶段类似。
不同之处主要是推理阶段会调用模型的 generate() 方法生成 Token ID 序列,最后再调用 tokenizer.decode 解码成人类可读的文本。
model, tokenizer = init_model(args)
prompts = get_prompt_datas(args)
# Tokenize 用户输入
inputs = tokenizer(
new_prompt,
return_tensors="pt",
truncation=True
).to(device)
# 模型生成(generated_ids 含有 prompt + 新生成部分)
generated_ids = model.generate(inputs["input_ids"], ...)
# Decode 仅新生成的部分
new_tokens = generated_ids[0][inputs["input_ids"].shape[1]:]
response = tokenizer.decode(new_tokens, skip_special_tokens=True)
四、训练 Tokenizer
MiniMind 提供了训练 Tokenizer 的脚本 scripts/train_tokenizer.py,可以根据自己的数据集训练一个定制的 Tokenizer。
为什么要训练 Tokenizer?
训练 Tokenizer 的核心目的是通过针对特定语言和数据集进行优化,提升模型效率:预训练的英文 tokenizer(如 GPT-2)对中文等语言的分词效果较差,需要训练定制化的 tokenizer 以适应目标语言的词汇结构;通过从数据中学习最频繁的子词片段,为常用词/短语保留完整 token、为生僻词合理拆分,从而优化词表并减少 token 数量(例如"人工智能"可从 10 个 tokens 降至 2 个);同时可以定义项目所需的特殊 token(如对话格式标记)以支持特定任务格式。
train_tokenizer.py 中的代码比较简单,这里提取一下关键步骤:
from tokenizers import decoders, models, pre_tokenizers, trainers, Tokenizer
import os
# 1. 初始化 BPE Tokenizer
tokenizer = Tokenizer(models.BPE())
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=False)
# 2. 定义特殊 Token
special_tokens = ["<|endoftext|>", "<|im_start|>", "<|im_end|>"]
# 3. 配置训练器
trainer = trainers.BpeTrainer(
vocab_size=6400,
special_tokens=special_tokens,
show_progress=True,
initial_alphabet=pre_tokenizers.ByteLevel.alphabet()
)
# 4. 读取训练数据
texts = read_texts_from_jsonl(data_path)
# 5. 训练
tokenizer.train_from_iterator(texts, trainer=trainer)
# 6. 设置解码器
tokenizer.decoder = decoders.ByteLevel()
# 7. 保存
tokenizer_dir = "../model/"
os.makedirs(tokenizer_dir, exist_ok=True)
tokenizer.save(os.path.join(tokenizer_dir, "tokenizer.json"))
tokenizer.model.save("../model/")
输出文件
训练完成后,model/ 目录下会生成:
tokenizer.json:tokenizer 的主文件tokenizer_config.json:配置文件vocab.json和merges.txt:BPE 模型参数
五、总结
Tokenization 是 LLM 处理文本的第一步,它将连续的文本转换为离散的 token ID 序列,为后续的 Embedding 和模型处理奠定基础。通过 BPE 等子词分词技术,既能保留常用词作为完整 token,又能将罕见词拆分成已知子词序列,从而平衡词汇表大小和处理能力,彻底解决 OOV 问题。Token ID 序列作为 Embedding 层的输入,通过查找嵌入表获取向量表示;而 Padding 则用于统一批量序列长度,支持高效的批量处理。
MiniMind 项目使用 tokenizers 库训练定制化的 BPE tokenizer(vocab_size=6400),采用 ByteLevel 处理支持中文等多语言文本。通过三种特殊 token(<|endoftext|>、<|im_start|>、<|im_end|>)分别处理 padding、对话格式标记和生成终止,并实现 ChatML 格式的对话模板。在训练过程中,embed_tokens 与 lm_head 共享权重,随模型参数同步更新,最终保存在模型 checkpoint 中。
理解 Tokenization 的原理和实现,有助于更好地理解 LLM 如何处理和生成文本,也为优化模型性能提供了基础。