到底什么是「Embedding」
潘忠显 / 2025-09-10
近几年,“大语言模型”(LLM)凭借其强大的文本理解和生成能力,正在改变我们与数字世界的交互方式。
而在这背后,一个名为 Embedding 的关键技术,默默地扮演着连接语言与数学的“翻译官”角色。
1. 什么是 Embedding?
简单来说,Embedding 是一种将非结构化数据(如文本、图像、音频)转化为计算机可理解和处理的数值向量(一组数字)的技术。
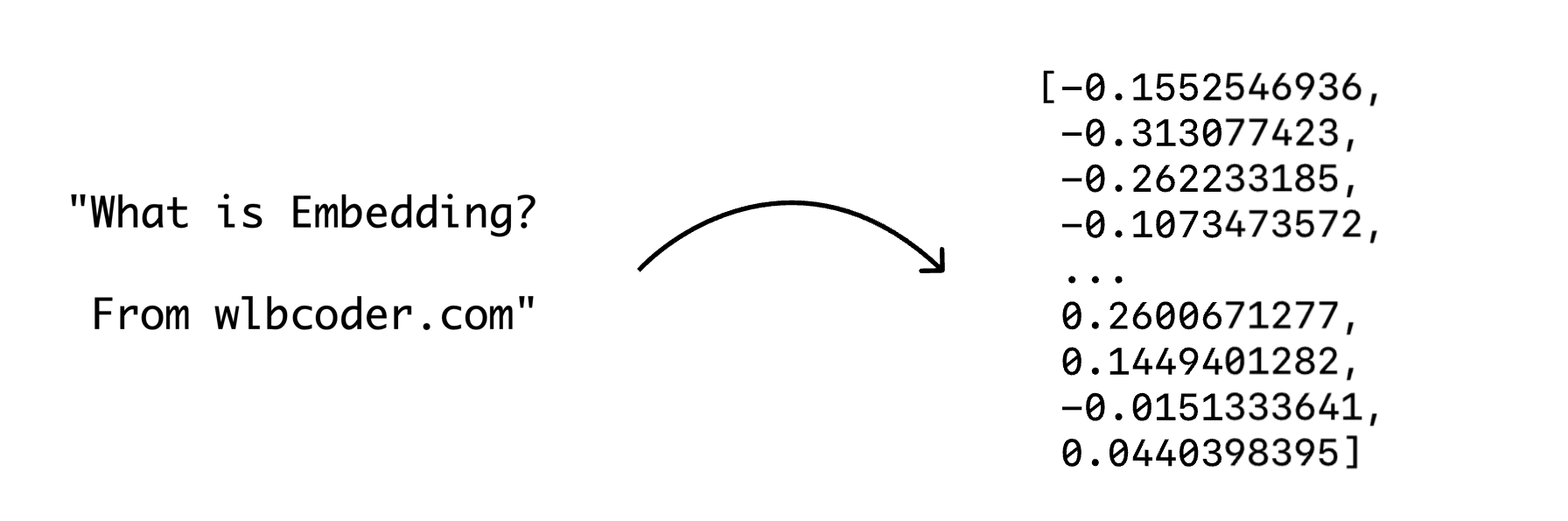
这种转换的核心思想是:语义上相似的数据,在向量空间中的位置也相近。例如,通过 Embedding,计算机能理解“北京”和“上海”是相似的,因为它们都是城市;而“北京”和“苹果”则相差甚远。这种距离的远近,让计算机能够像我们人类一样,感知和处理复杂的概念关系。
向量化的过程不是手动进行的,而是由模型自动学习和实现的。你可以通过调用本地模型或远程服务来完成这一转换。
例如,在使用 OpenAI 的 SDK 时,你可以根据需求调用不同的 Embedding 模型文档,向远程 API 发送请求,从而获得文本对应的向量。
from openai import OpenAI
client = OpenAI()
response = client.Embeddings.create(
input="Your text string goes here",
model="text-Embedding-3-small"
)
print(response.data[0].Embedding)
# 将会打印具体的向量内容
向量的“远近”如何计算?
在 Embedding 中,我们用余弦相似度(Cosine Similarity)来衡量向量之间的“远近”。它计算的是两个向量在多维空间中的夹角。
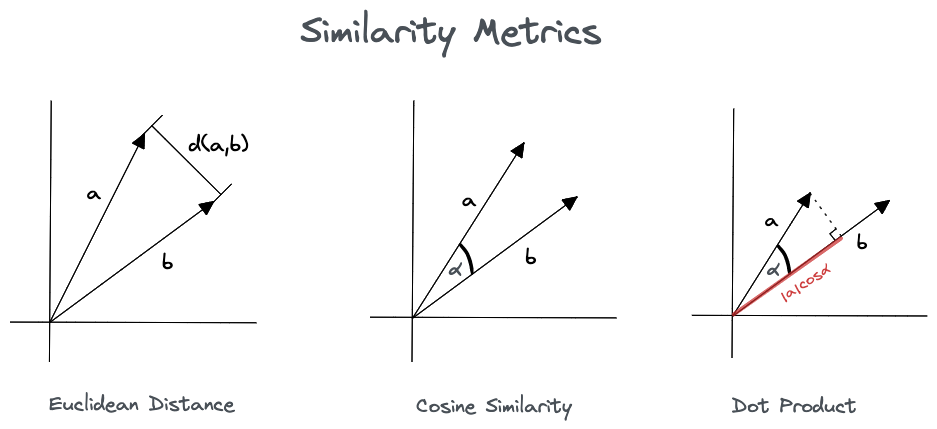
- 夹角越小,余弦相似度越接近 1,向量方向越接近,代表它们所代表的原始数据语义越相似。
- 夹角越大,余弦相似度越接近 0,向量方向越不相关,代表它们语义不相关。
相比于简单的欧式距离,余弦相似度更侧重于向量的方向,使其在衡量语义相似度时更加精确。
向量和张量的关系
机器学习中有一个概念是张量(Tensor),它与我们讨论的 Embedding 向量有着紧密的联系。
- 张量 (Tensor) 是一个更广义、更通用的概念,它是机器学习中所有数据表示的基石。可以将它理解为 N 维数组。例如,一个视频数据就可以表示为一个 4 维张量
(帧数, 宽度, 高度, 颜色通道)。 - 向量 (Vector) 是一种特殊的张量,它是一个一维数组,也就是 1 维张量。因此,向量是张量的一个子集。
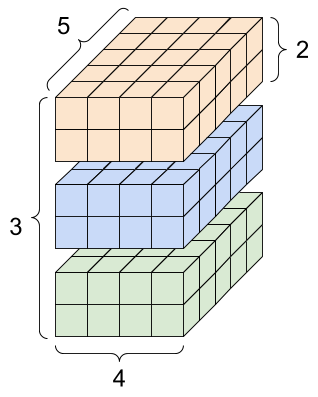
在大语言模型内部,虽然每个词或句子的 Embedding 结果是一个向量,但为了批量处理,这些向量会被组织成矩阵或更高维度的张量进行高效计算。
从词到句子的 Embedding 演变
早期的 Embedding 技术,如 Word2Vec,主要关注单个词汇。它通过上下文来学习。
例如,一个模型会学习到“猫”和“老虎”经常出现在“动物园”等相似的语境中,从而将它们的向量位置调整得更近。
然而,为了处理更复杂的句子和段落,现代模型引入了更强大的机制:
- 自注意力机制:该机制由 Transformer 架构引入。它让模型在生成一个词的向量时,能同时考虑到句子中所有其他词的重要性,从而理解长距离的依赖关系,生成能够代表整个句子语义的向量。
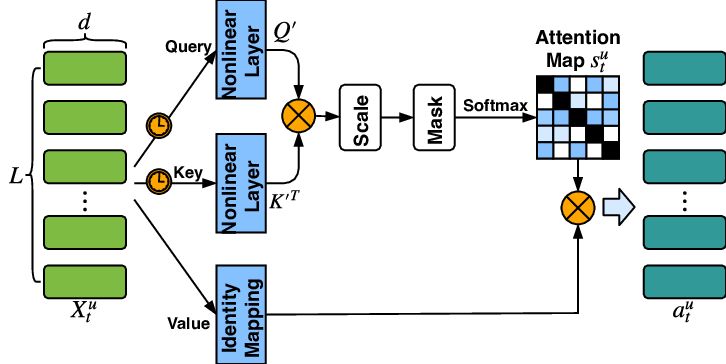
来源:https://www.researchgate.net/figure/llustration-of-the-self-attention-module-e-input-is-the-Embedding-matrix-of-the-latest_fig1_327134627
- 双向上下文理解:这一能力由 BERT 模型在 Transformer 架构的基础上实现。BERT 的名称(Bidirectional Encoder Representations from Transformers)就明确了它的核心特点:它通过在预训练阶段同时考虑一个词的左右两侧所有词,从而实现了真正的双向上下文理解。这使得模型能为同一个词(如“很长”),根据它在不同句子中的含义(“这条河很长”与“他当了很长时间的厂长”),生成不同的向量,从而更精准地捕捉语境。
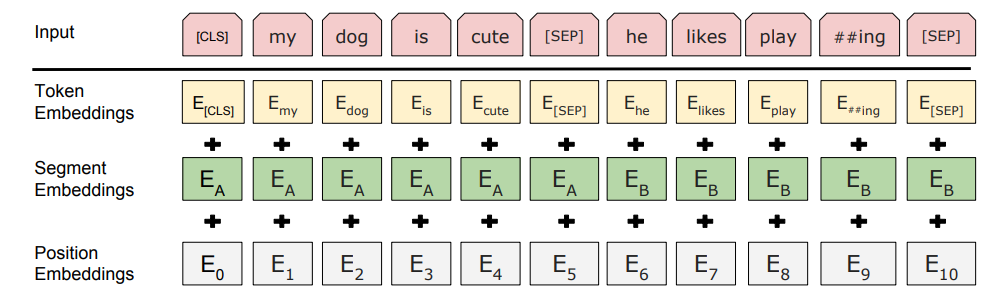
来源:https://pub.towardsai.net/understanding-bert-b69ce7ad03c1
向量数据库
为了高效地存储和检索这些高维向量,向量数据库应运而生。它是一种专门设计用来管理和搜索高维向量数据的数据库,其核心能力是执行相似性搜索,即根据向量的“距离”来查找与查询最相似的向量。
根据设计目的,向量数据库可以分为两类:
- 专用向量数据库:这些数据库完全为向量检索而构建,通常采用各种高级索引算法(如 HNSW、IVF)来确保在海量数据中的毫秒级查询。例如:Pinecone、Milvus 和 Weaviate。
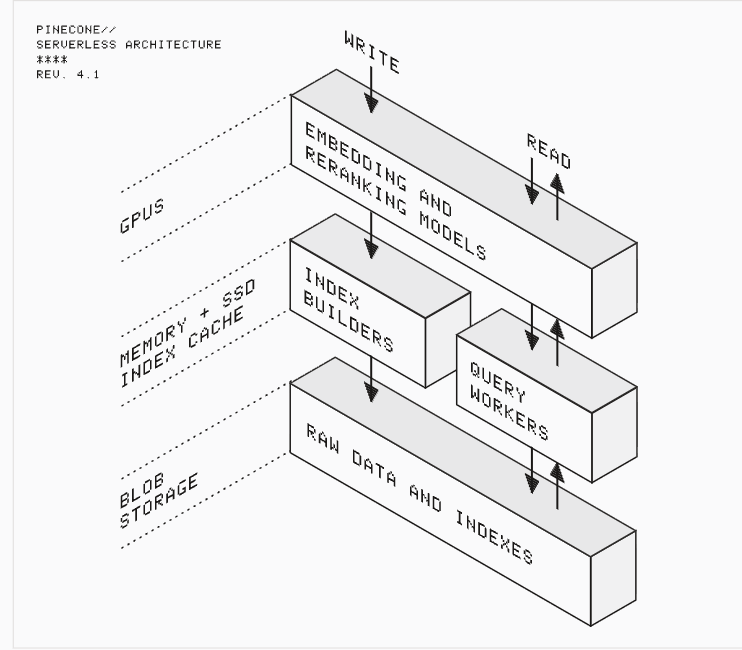
- 集成向量检索功能的通用数据库:这类是传统的数据库,通过插件或内置功能来支持向量检索。它们最大的优势是能同时处理结构化数据和向量数据,非常适合需要同时进行关键词搜索和语义搜索的混合检索场景。例如:Elasticsearch、PostgreSQL (通过 pgvector 插件) 和 Redis。
2. RAG 中的 Embedding:连接检索与生成
RAG(Retrieval-Augmented Generation,检索增强生成)是一种将大语言模型(LLM)与可搜索的外部知识库相结合的技术。它让模型能够访问并利用它在训练时未见过的新信息,从而大幅提升其回答的准确性和时效性。
而 Embedding 在 RAG 框架中扮演着不可或缺的角色,它充当了连接外部知识库与大语言模型的桥梁,实现了从“关键词匹配”到“语义匹配”的跨越。在 RAG 框架中,导入数据(Indexing)和查询(Retrieval)时,必须使用同一个 Embedding 模型。这被称为模型一致性原则,它是 RAG 框架能够有效运行的基石。
RAG 的工作流程如下:
- 知识库准备:首先,将海量的外部文档(如 PDF、网页等)分割成小块,并使用 Embedding 模型将每个文本块转换为向量,存储在向量数据库中。
- 查询与检索:当用户提出问题时,系统会将查询语句转换为一个查询向量。然后,在向量数据库中,通过余弦相似度计算,快速找出与查询向量最相似的 top-k 个文本块。
- 生成:这些被检索出的原始文本块,连同用户的查询,被一起作为上下文传递给大语言模型。大语言模型基于这些准确、相关的上下文,生成一个全面且精确的回答。
Embedding 模型的任务是确保最相关、最有价值的信息能够被准确地检索出来,并传递给大语言模型。如果 模型性能不佳,它可能会出现检索不准确、遗漏关键信息、引入噪音等问题,直接地影响着大语言模型在 RAG 框架下的表现。因此,一个高质量的 Embedding 模型是 RAG 成功的关键。
3. Embedding 在 LLM 中的作用
事实上,除了 RAG 会直接用到 Embedding 之外,大语言模型本身也离不开 Embedding。Embedding 是大语言模型(LLM)内部运行的基石,贯穿了整个处理流程。它不会在用户交互中直接作为结果呈现出来,但用户输入的每一个字,最终都变成了模型可以理解的 Embedding 向量。
LLM 内部工作流中,Embedding 是其第一道关口。当用户输入一个提示词(例如:“请写一首关于秋天的诗”),LLM 会在内部进行以下步骤:
- Tokenization(分词):首先,LLM 的分词器将你的文本输入拆解成一个个 token。这里的 token 可能是一个词、一个字或是一个词组。
- Embedding Lookup(向量查询):每个 token 都有一个唯一的 ID。LLM 内部有一个巨大的 Embedding 矩阵,就像一个字典。当它看到一个 token ID 时,就会在这个矩阵中查找对应的 Embedding 向量。
- Position Encoding(位置编码):除了每个 token 的语义向量,LLM 还会为每个 token 加上一个位置编码,以保留它在句子中的顺序信息。这对于理解语法和句子的完整含义至关重要。
- 向量处理:这两个向量(语义向量 + 位置编码)结合起来,形成了 LLM 可以处理的最终输入。这些向量会经过 LLM 内部的 Transformer 层进行一系列复杂的计算,以理解你的意图并生成回应。
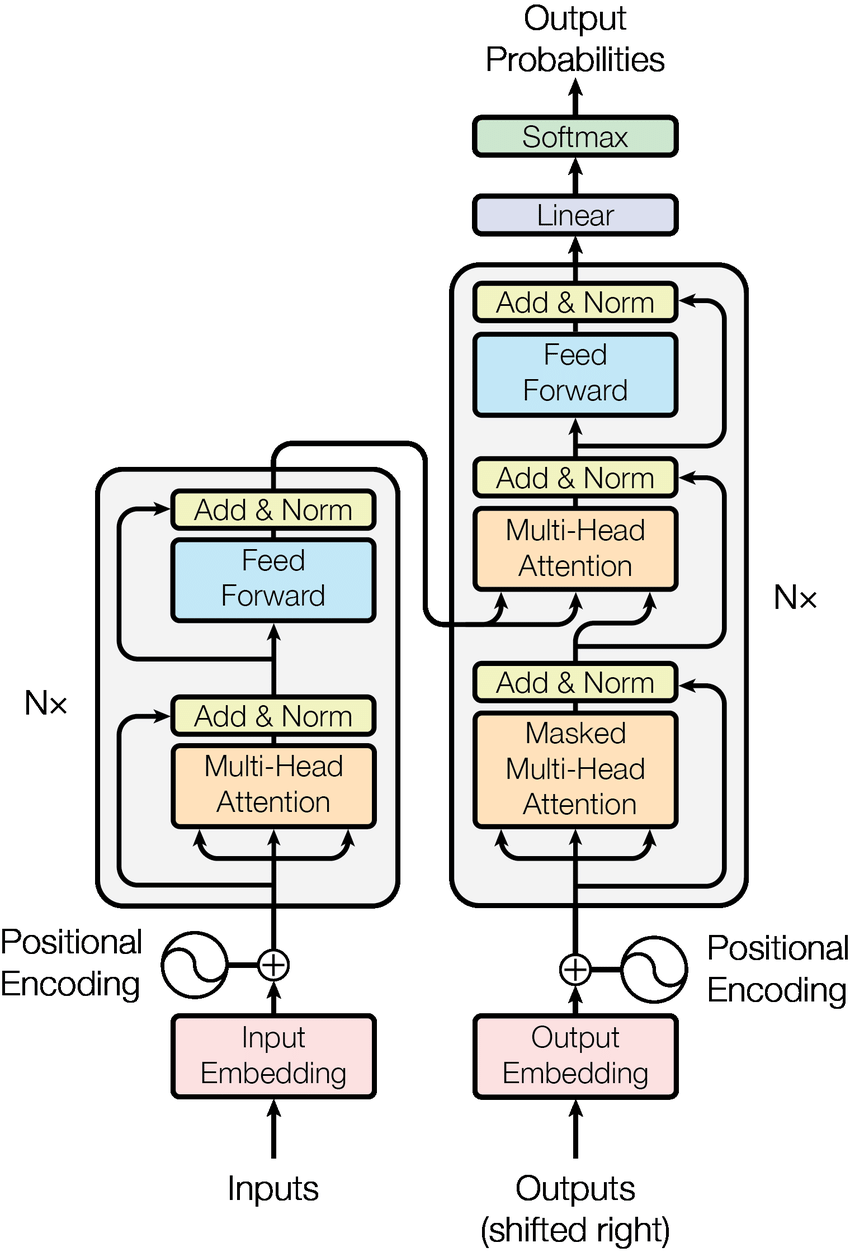
来源:https://www.researchgate.net/figure/The-Transformer-model-architecture_fig1_323904682
Embedding 是语言和数学之间搭建起的一座桥梁。它把人类可读的语言,转换为机器可计算的数字,从而让 LLM 能够进行推理、理解和生成。所有基于 Transformer 架构的大语言模型,其核心运行机制都离不开 Embedding。
RAG 则是在 LLM 的基础上,额外利用 Embedding 这一技术,来从外部知识库中检索信息,以增强模型的回答能力。
4. 本地部署的开源 Embedding 模型
尽管像 OpenAI 这样的在线服务方便易用,但它们会产生费用。比如下图是 OpenAI 提供的Embedding 模型的调用价格:
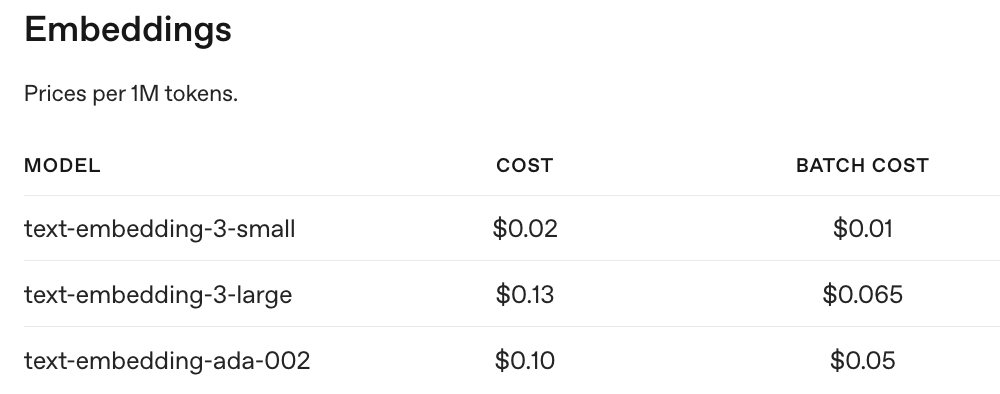
除了成本高之外,将本地文本传到远端的进行Embedding 还有数据隐私泄漏的风险。还好,开源社区提供了许多可以在本地使用的高质量 Embedding 模型。
本地使用 Embedding 模型又分为两种方式:进程内加载、本地服务部署。
Hugging Face 的 SentenceTransformers 库
SentenceTransformers 库是一个为句子、文本和图像做 Embedding 的 Python 框架。使用前需要安装:
pip install -U sentence-transformers
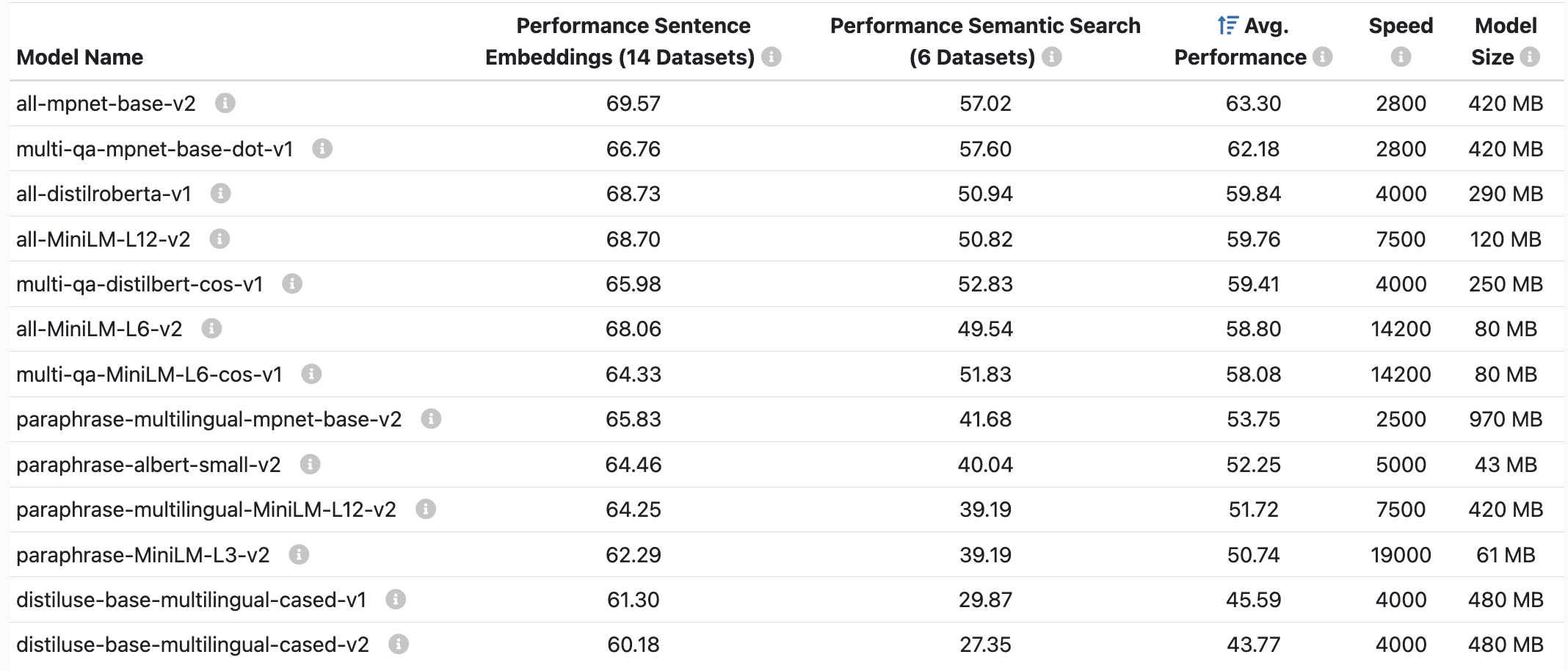
可以使用的模型以及其大小、速度如下:
这里有个官方的使用示例:
from sentence_transformers import SentenceTransformer
# 1. Load a pretrained Sentence Transformer model
model = SentenceTransformer("all-MiniLM-L6-v2")
# The sentences to encode
sentences = [
"The weather is lovely today.",
"It's so sunny outside!",
"He drove to the stadium.",
]
# 2. Calculate Embeddings by calling model.encode()
Embeddings = model.encode(sentences)
print(Embeddings.shape)
# [3, 384]
# 3. Calculate the Embedding similarities
similarities = model.similarity(Embeddings, Embeddings)
print(similarities)
# tensor([[1.0000, 0.6660, 0.1046],
# [0.6660, 1.0000, 0.1411],
# [0.1046, 0.1411, 1.0000]])
SentenceTransformers 库还支持用户自己加载和训练 Embedding 模型,然后推送到 Hugging Face。
Ollama 及其 SDK
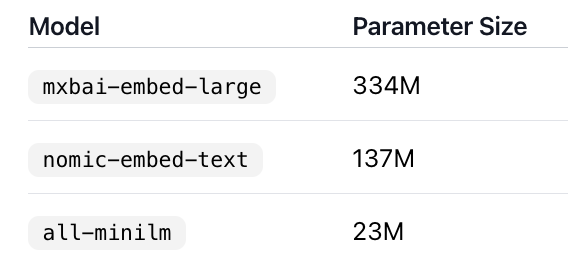
著名的开源项目 Ollama 可以让你在本地运行 LLM 模型,它还可以支持运行 Embedding 模型。具体地,你可以在Ollama网站上直接通过标签来查看支持哪些 Embedding 模型。
使用 Ollama 提供模型的前提是你得安装和启动 Ollama,然后使用命令行工具拉取对应的模型即可:
ollama pull mxbai-embed-large
成功之后可以直接使用 curl 指令测试,可以直接得到响应:
curl http://localhost:11434/api/embed -d '{
"model": "mxbai-embed-large",
"input": "Welcome to access wlbcoder.com"
}'
Ollama 还提供了不同语言的库封装了 Restful 访问。
ollama.embed(
model='mxbai-embed-large',
input='Llamas are members of the camelid family',
)
两种方式的比较
直接使用 SentenceTransformers 库的方式,会直接将模型的参数加载到你 Python 脚本所在的进程中(占用内存或显存),整个 Embedding 转换计算都在这个进程内部完成。
其优点是使用简单,没有外部依赖,但缺点也比较明显:每次运行脚本都需要重新加载模型、不适合多个应用共享同一个模型的场景、不适合其他开发语言。
使用 Ollama 本地服务的方式,依赖长期后台有一个后台服务,专门负责加载和运行模型。客户端通过本地网络向这个服务发送 API 请求。
后者的优缺点恰好反过来,使用标准的 HTTP API 支持不同的语言访问,模型只需加载一次,多应用共享。缺点就是依赖额外启动和管理一个服务进程。
前面我们也提到,无论使用哪种方式,都有开源社区提供的丰富模型库。
5. Elasticsearch 的语义检索
在前面提到的 RAG 流程中,向量数据库扮演了关键的存储角色。而 Elasticsearch 则是一个出色的集成式解决方案。它通过内置的 dense_vector 字段和 kNN(最近邻)搜索功能,将 Embedding 的转换、存储和检索封装在了一起。
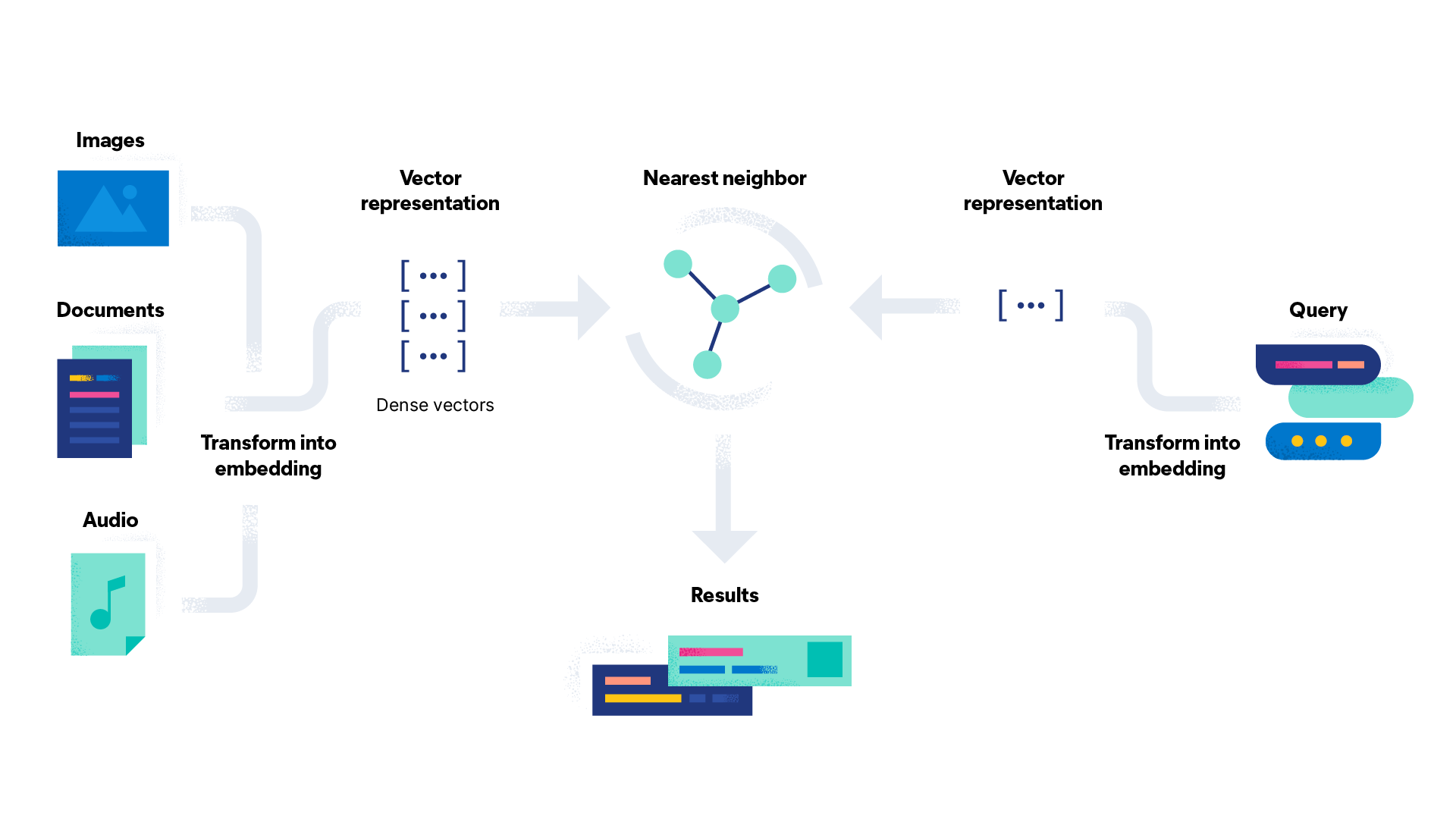
这意味着,你可以直接将 Elasticsearch 作为 RAG 框架的向量存储来使用。当你导入文档时,可以配置一个处理管道,让 Elasticsearch 自动调用模型将文本转换为向量并存储。当进行查询时,它会同样自动将查询转换为向量,并在内部执行高效的相似性搜索。
以著名的RAGFlow开源项目为例,其默认使用的就是 Elasticsearch,你也可以通过配置切换成向量存储 Infinity。
6. 小结
Embedding 技术是大语言模型以及诸多 AI 应用的核心基石。它不仅把复杂难解的自然语言等非结构化数据,转化为可计算的数字空间,让机器获得“理解”和“推理”能力,还在语义检索(如 RAG)等实际应用中实现了从关键词到语义级、内容级的智能跨越。
本文介绍了Embedding 的基本原理、在 LLM 和 RAG 中的核心作用、主流的本地和开源 Embedding模型、以及 Embedding 在向量数据库和语义检索系统中的应用,希望能帮助读者理解 Embedding,为后续在相关领域的学习和实践提供参考。