ElasticSearch 中的 keyword
潘忠显 / 2025-07-15
在现代数据驱动的世界中,ElasticSearch 作为一个强大的分布式搜索和分析引擎,广泛应用于各种场景。它能够处理海量数据,并提供快速的搜索和分析能力。
如果你用过 ElasticSearch,很可能见过 keyword 这个单词。但是 keyword 在 ES 中有2种含义,一种是作为数据类型,另一种是 text 类型中的字段名。这两种概念很容易混淆,本文就来介绍一下 keyword 作为类型和字段的不同用法,以及他们之间的关系。
keyword 作为数据类型
ElasticSearch 支持多种数据类型,包括字符串、数字、日期等,理解这些数据类型是有效使用 ElasticSearch 的关键。
其中,字符串类型分为 text 和 keyword 两种:
- text 类型用于全文搜索,支持分词和分析
- keyword 类型则用于精确匹配,不进行分词
比如下边这个图是腾讯云配置索引的操作界面:
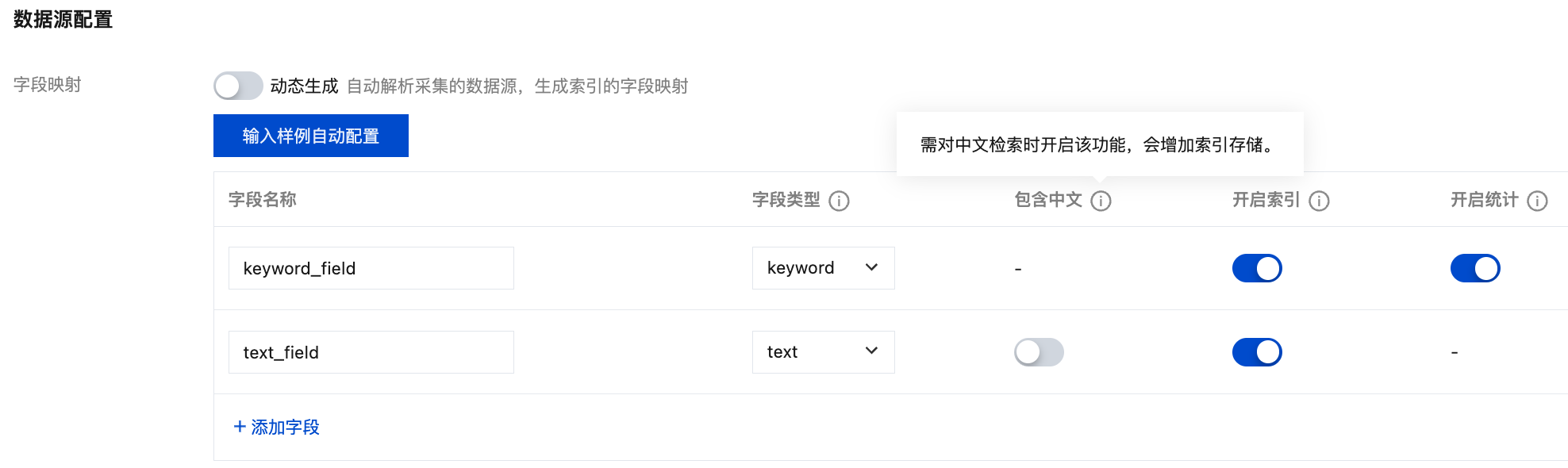
keyword 类型的主要特性是不进行分词,这意味着它适用于需要精确匹配的场景。
由于不分词,keyword 类型在存储和索引时更加高效,适合用于过滤、聚合和排序等操作。
它通常用于存储结构化数据,如电子邮件地址、用户名、标签等。
keyword 作为字段
text 类型的字段会进行分词和分析,适合用于全文搜索。
然而,在某些情况下,我们可能需要对同一字段进行精确匹配。
为此,ElasticSearch 提供了 fields 属性,允许在 text 类型中定义一个 keyword 子字段。这样,我们可以在同一字段上同时进行全文搜索和精确匹配。
text 类型的字段并不会默认创建一个 keyword 子字段。需要显式地在索引映射中定义这个子字段。
我们可以在腾讯云上实际创建前边图1中的索引。如果通过索引创建的图形界面,只能创建text_field的类型是个text,而没有子字段:

如果要加入 keyword 字段,则可以切换到 JSON 模式,比如这里新增一个 text_key_word_field 字段,这里的 fields 是我手动输入的:
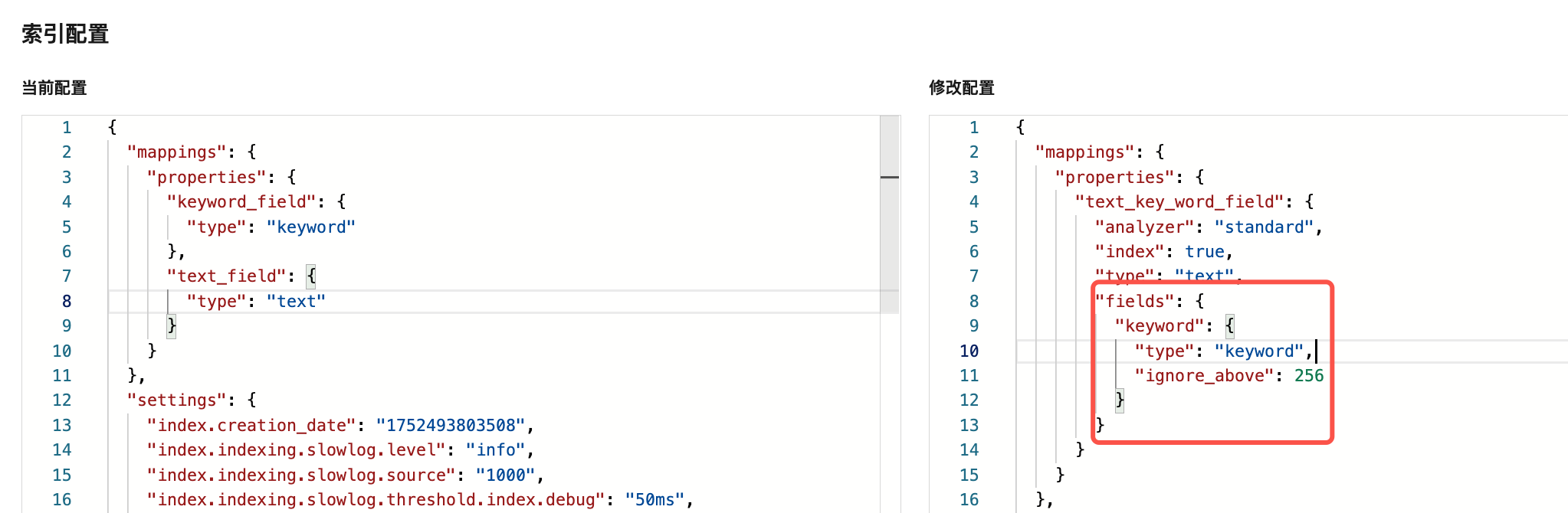
以上配置中有一个 ignore_above 配置,可以避免索引过长的字符串作为是keyword,达到优化索引性能的效果。
此外,避免在不必要的字段上使用 text 类型,以减少索引大小和提高查询性能。
Kibana Dev Tools 上实际操作
通过 kibana dev tools 我们也可以直接通过 GET tt/_mapping 来查看索引的字段信息:

上述索引中,mapping有三个字段:
- 一个 keyword 类型的字段
- 一个text但是没有 keyword 子字段
- 一个text字段有 keyword 字段
创建索引了之后,我们插入2条记录,以便后边进行测试:
POST /tt/_doc/1
{
"keyword_field": "exact_match_value",
"text_field": "This is a text field with full text search capabilities.",
"text_key_word_field": "This field supports both full text search and exact match."
}
POST /tt/_doc/2
{
"keyword_field": "another_exact_value",
"text_field": "Another text field with different content.",
"text_key_word_field": "Another field for testing both search types."
}
case1: 查询 keyword_field 的精确匹配(这个只会找到 id=1 的文档)
GET /tt/_search
{
"query": {
"term": {
"keyword_field": "exact_match_value"
}
}
}
case2: 查询 text_field 的全文搜索(这个查询结果包含 id=1和id=2的文档,因为第一个文档包含了“full text search”,而第二个文档包含了“text”)
GET /tt/_search
{
"query": {
"match": {
"text_field": "full text search"
}
}
}
case3: 查询 text_key_word_field 的精确匹配(查询结果只包括 id=1 的文档)
GET /tt/_search
{
"query": {
"term": {
"text_key_word_field.keyword": "This field supports both full text search and exact match."
}
}
}
case4: 查询 text_key_word_field 的全文搜索(查询结果包括id=1和id=2文档)
GET /tt/_search
{
"query": {
"match": {
"text_key_word_field": "supports both search"
}
}
}
case5: 查询 text_field 的「精确匹配」(查询结果为空,因为 text_filed 并没有 keyword 字段,不会报错)
GET /tt/_search
{
"query": {
"match": {
"text_field.keyword": "This is a text field with full text search capabilities."
}
}
}
case6: 误用 keyword_field 的精确匹配(查询结果为空,因为 keyword 并没有 keyword 字段,不会报错)
GET /tt/_search
{
"query": {
"term": {
"keyword_field.keyword": "exact_match_value"
}
}
}
通过上边的5个测试,我们得到了以下结论:
- keyword 的查询是精确匹配
- text 如果要使用精确匹配,需要添加 keyword 的子字段
- text 创建了 keyword 子字段之后,正常插入即可更新该子字段
- keyword 类型和没有 keyword 子字段的 text 类型都不能通过加 .keyword 来精确匹配
- text 字段可以全文模糊搜索
全文搜索与匹配打分
上边的 case 2 和 case 4 都是使用了全文搜索。我们可以看看 case 2 中具体的返回结果:

返回的 hits 数组中,除了 id 和 source 之外,还有一个 score。
我们搜 “full text search”,这三个单词在 id=1的 doc 中都有,分数是1.49;而在 id=2 的doc中只有 “text” 的单词,分数是 0.2。
_score 字段在 ElasticSearch 的查询结果中表示文档与查询的匹配程度,它是一个浮点数,通常用于排序查询结果。分数越高,表示文档与查询的相关性越高。
ElasticSearch 使用一种称为 BM25 的算法(以及其他可能的评分机制)来计算这个相关性分数。
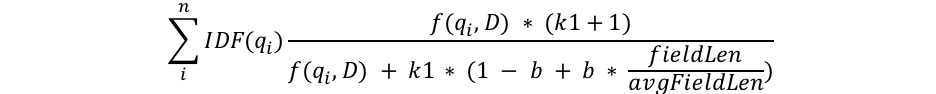
以下是一些影响 _score 的因素:
- 词频(Term Frequency, TF):在文档中某个词出现的次数越多,相关性越高,分数也越高。
- 逆文档频率(Inverse Document Frequency, IDF):某个词在整个索引中出现的次数越少,说明这个词更具辨识度,相关性越高,分数也越高。
- 字段长度规范化(Field Length Normalization):较短的字段更可能是相关的,因此在较短字段中出现的词会有更高的分数。
- 查询中的词项:查询中包含的词项越多,匹配的词项越多,分数越高。
- Boosting:查询可以携带
boost参数,人为地提高某些字段或词项的权重,从而影响_score的计算。
需要注意的是,_score 的值是相对的,主要用于比较同一查询结果中的文档,在不同的查询中可能没有绝对的意义。
小结
keyword 类型适用于需要精确匹配的场景,如过滤、聚合和排序。典型的应用包括日志分析中的状态码、用户 ID、标签等字段。
text 类型则适用于需要全文搜索的场景,如文章内容、评论、描述等。
text 类型字段增加 keyword 子字段可以支持精确匹配。
只有需要精确匹配 text 类型时,查询条件才加 “.keyword”,其他两种都不应该加。
text 类型全文搜索会对性能有一定的影响。当我们考虑减少索引大小和提高查询性能时,可以通过避免在不必要的字段上使用 text 类型、合理设置字段的 ignore_above 属性等方式进行改善。