为什么HTTP连接复用须调用io.ReadAll?
潘忠显 / 2025-05-26
前面发了个小文《固定频率压测工具》,文中有提到「使用直接调用resp.Body.Close(),而前边没有调用io.ReadAll(resp.Body),造成了TCP连接被关闭而没有被复用,进而引起大量 TIME_WAIT,进而引起端口不够无法建立连接」的问题。
今天分别从代码层面、逻辑层面简单解释一下为什么。
代码层面
今天大概看了下 http 包中 client.go 和 transport.go 的代码,传输相关的主要在后者。
http.Client
我们创建一个HTTP Client 通常的方法是下边这样:
client := &http.Client{
Timeout: 10 * time.Second,
Transport: &http.Transport{
MaxIdleConns: 1000,
MaxIdleConnsPerHost: 1000,
},
}
我们简单看一下 Client 接口,可以看到 Transport 是 RoundTripper 接口,只要求实现一个函数:
RoundTrip(*Request) (*Response, error)
http.Transport
上边代码创建了一个 http.Transport 变量,这个 Transpor 结构就是 http 包实现的一个 RoundTripper,他支持 HTTP、HTTPS 等传输。
在 transport.go 中并没有定义的 Transport 的 RoundTrip(),而是被放在了 roundtrip.go 文件中,其封装的是 transport.go 中 Transport 的私有函数 roundTrip():
func (t *Transport) RoundTrip(req *Request) (*Response, error) {
return t.roundTrip(req)
}
我们看一下 Transport 结构中的一些内容,可以很清晰的看见到,空闲连接管理是在 Transport 中处理的:
type Transport struct {
idleMu sync.Mutex
closeIdle bool // user has requested to close all idle conns
idleConn map[connectMethodKey][]*persistConn // most recently used at end
idleConnWait map[connectMethodKey]wantConnQueue // waiting getConns
Client 和 RoundTrip 的关系
我们使用 http.Client 的典型用法是创建请求、依次调用 client.Do、io.ReadAll、body.Close():
req, err := http.NewRequest("POST", url, bytes.NewBuffer([]byte("{\"delay\": 1}")))
req.Header.Set("Content-Type", "application/json")
resp, err := client.Do(req)
body, err = io.ReadAll(resp.Body)
resp.Body.Close()
而在 Client.Do() 函数中,在简单处理完请求结构之后,就会调用 send() 函数,进而调用 client.Transport (如果没有设置,http包中有一个默认的DefaultTransport)
Transport.dialConn()
HTTP 连接管理有一个关键的函数,他就是 dialConn()。
为了清晰点,我这里列一下调用 dialConn() 函数点外部调用栈信息:
http.(*Transport).dialConn()
http.(*Transport).dialConnFor()
http.(*Transport).startDialConnForLocked.func1()
http.(*Transport).queueForDial()
http.(*Transport).getConn()
http.(*Transport).roundTrip()
http.(*Transport).RoundTrip()
这个函数的定义如下:
func (t *Transport) dialConn(ctx context.Context, cm connectMethod) (pconn *persistConn, err error)
他会返回一个 persistConn 指针,其中包含 net.Conn 是一个真实网络连接,还有一个 t 用于指向该持久连接所属的 Transport:
type persistConn struct {
t *Transport
conn net.Conn
tlsState *tls.ConnectionState
br *bufio.Reader // from conn
bw *bufio.Writer // to conn
// ...
}
persistConn.readLoop()
再深入到 dialConn() 中,我们能找到被调用 persistConn.readLoop() 函数,该函数中有调用 pc.t.tryPutIdleConn(pc),会将创建的连接放到 Transport 的空闲连接池中。
而我们前边**是否调用io.ReadAll(resp.Body)造成的区别在于,从 waitForBodyRead channel 中的返回的结果是 true 还是 false **:
- 如果调用了
io.ReadAll(resp.Body),bodyEOF 为 true,会将当前连接作为空闲连接保留使用 - 如果不调用,bodyEOF 为 false,当前连接就会被关闭
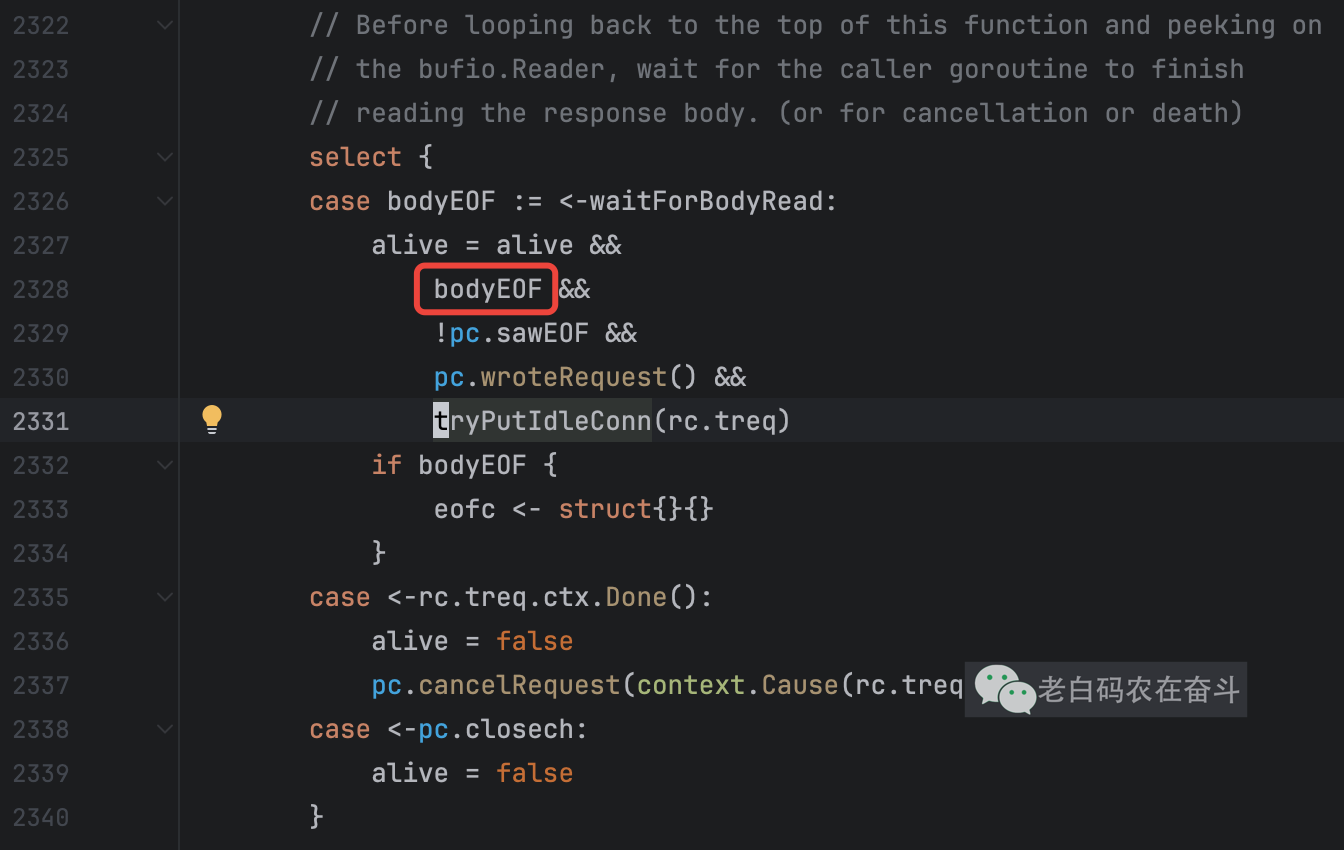
bodyEOFSignal.Close()
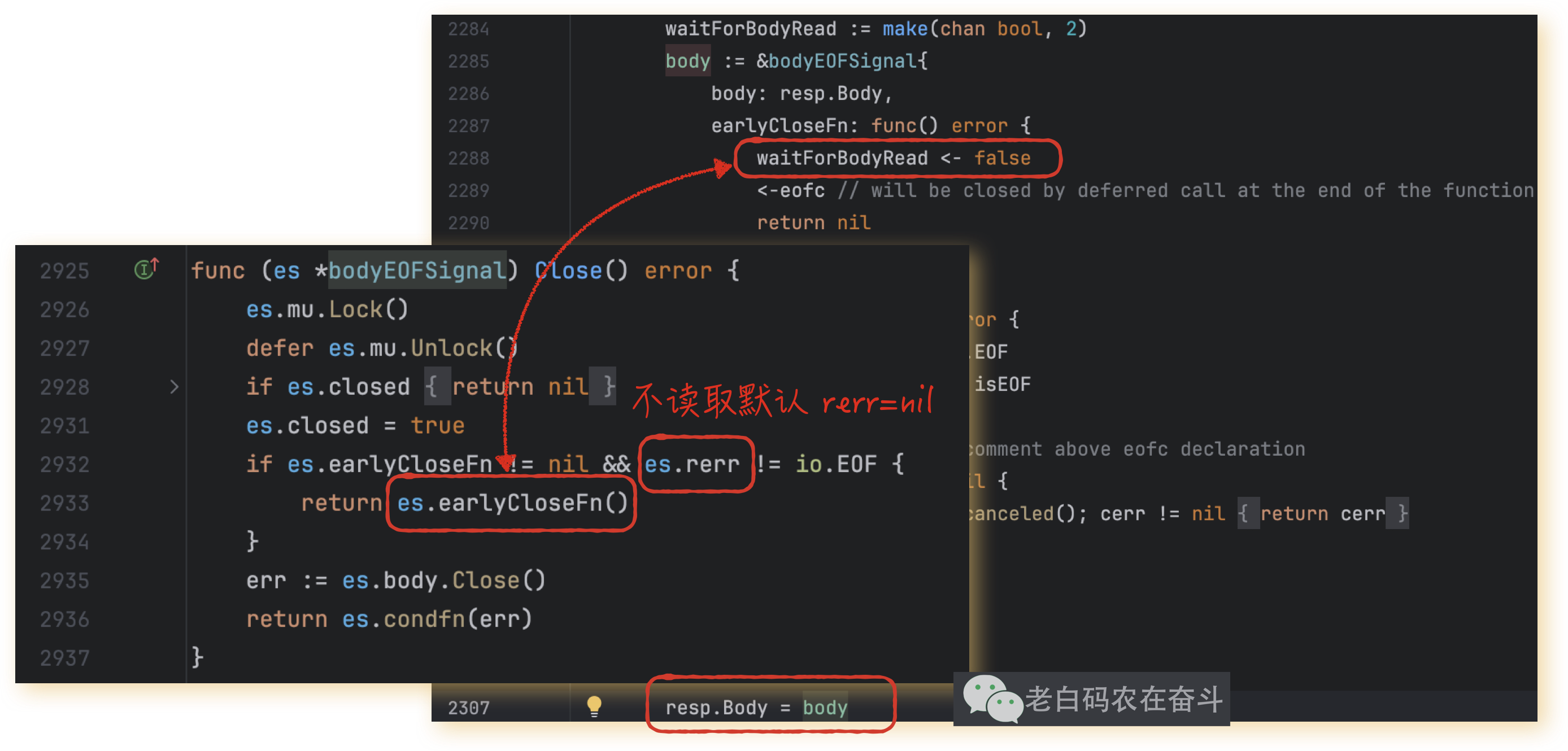
哪里触发的这个通道返回 true 还是 false?正是我们调用的 resp.Body.Close()。可以参考后边我附的代码看出来:
- 返回的 resp.Body 就是 bodyEOFSignal
- bodyEOFSignal 有一个 earlyCloseFn 可以调用
earlyCloseFn()往waitForBodyReadchannel 中塞入 false - 2932 行的 es.rerr 如果不调用
Read(),默认是空,只有调用io.ReadAll()或者其他读函数之后,才可能得到 io.EOF 跳过分支(io.ReadAll会循环调用Read方法,直到读取到 EOF 或发生错误)
小结
通过以上的代码阅读和分析,我们能够清晰的看出,为什么不调用 io.ReadAll() 会造成连接没有被复用——其实也就是没有被放到空闲连接池中。
协议逻辑层面
我们知道 HTTP 是一种基于 TCP的一问一答应用层协议,即:一个 TCP 连接上,发出请求之后,必须受到完整的回答才能发送下一个请求。
考虑有些场景不需要知道返回内容,因此不调用 io.ReadAll() 直接调用 resp.Body.Close(),如果此时直接将 TCP 连接放回空闲连接池,那该连接如果被别逻辑使用,读取 Body 的时候,将会读到前一个请求的残留数据。
基于此,没有被读取完 Body 数据的 TCP 连接是不能作为空闲 HTTP 连接复用的。
公众号有评论:「为什么不在 resp.Body.Close() 里面执行 io.ReadAll() 呢?非得开发者手动调用吗?」
在某些情况下,调用 resp.Body.Close() 也不一定是消息已经接收完毕了,如果把 io.ReadAll() 放在 Close() 里边应该就会阻塞住 Close()—— 这应该不是Close() 预期的功能。