如何获得10倍性能提升
潘忠显 / 2024-11-17
背景
上周五,我看之前我在 Redis 上提的一个 Pull Request 有对话更新。看到有两个同学在讨论我那个 PR 是否会真的有性能提升。
讨论中有引用一个 PR #13558,该 PR 针对支持 AVX2 的 CPU 架构,做了优化,是的 PFCOUNT 指令和 PFMERGE 指令性能有12倍以上 的提升:
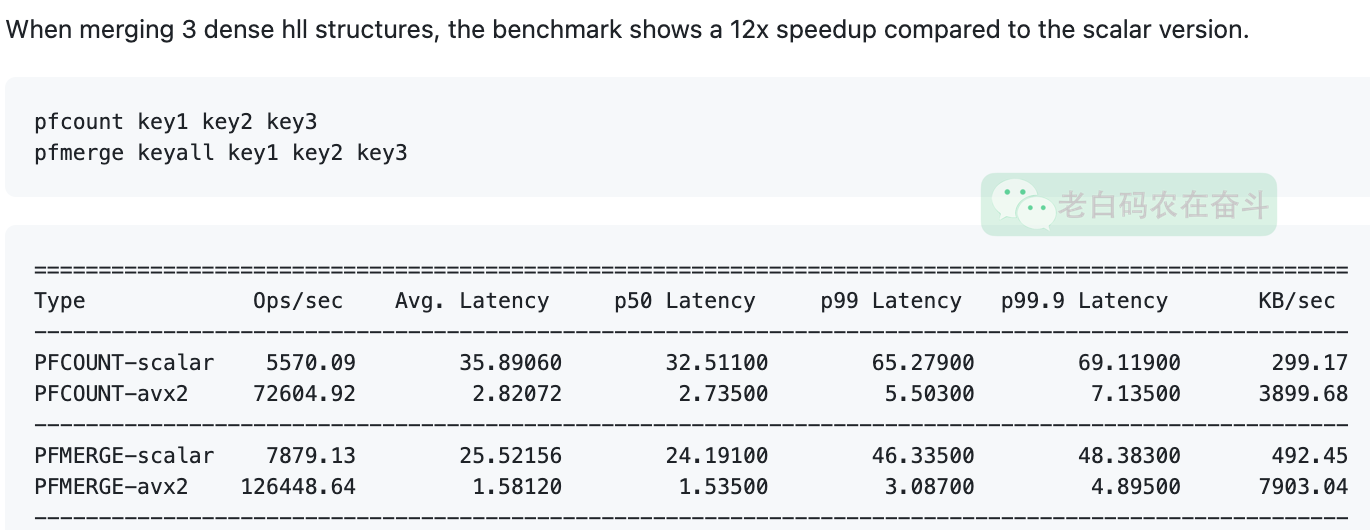
今天写篇小文,简单的聊聊其中的技术,更多的是聊聊给我带来的一些启示。
无知当聪明——什么是循环展开
我这里提的 PR,做了一件事情,就是将其重复的代码做了精简:原来16个register的处理,其中可以每四个的逻辑是重复的,我将其进行了简化。

本来以为 “聪明地” 发现了问题,但实际上,却反映了自己的无知:
在该 loop 之上就有一段注释,提到了:"we take a faster path with unrolled loops"。虽然当时有看到,但是没有仔细查阅其具体含义。

循环展开(Loop Unrolling)是一种编译器优化技术,它通过将循环体内的操作复制多次,减少迭代次数,进而改善程序性能。翻开《深入理解计算机系统》(简称/黑话 CSAPP),第5.8节就是 循环展开。
那么,为什么这种重复能提高性能呢?我们要将教科书往前翻一下,第5.7节-理解现代处理器中有这么几段介绍:
现代处理器可以同时对多条指令求值,这个现象称为指令级并行。 多条指令可以并行的执行,同时又呈现出一种简单的顺序执行指令的表象。
超标量(superscala)可以在每个时钟周期执行多个操作,而且是乱序的(out-of-order),意思就是指令的执行顺序不一定要与它们在机器级程序中的顺序一致。
现代处理器还采用了分支预测技术,会猜测是否会选择分支,同时还预测分支的目标地址。使用投机执行(speculative execution)技术,会开始取出位于它预测分支会挑到的指令,并对指令译码,甚至在他确定分支预测是否正确之前,就会去执行这些操作。 如果确定分支预测错误,会将状态充值到分支点的状态。
简单理解就是:处理器能够在指令级别并行不会相互依赖的代码。
PFCOUNT 中的代码操作一系列 register,这些 register 的值相互没有影响——每个循环中将统计结果赋值到不同的变量中。因此,通过循环展开可以:
- 增加指令级并行性,使处理器的流水线得到更充分的利用
- 减少循环控制开销,通过减少循环次数,可以减少循环迭代带来的执行条件判断和跳转指令的执行次数
- 减少分支预测失败,降低了上边提到的分支预测错误带来的性能损失
我修改之后的代码,减少了累积值数量,会降低程序的指令集并行度(参考 5.9 提高并行度)。
其实编译器可以很容易的做循环展开,带 -funroll-loops 调用 GCC 可以带来循环展开。但是直接展开的方式,可能只需依赖通用 -O3 等选项就能带来性能提升?
疑问:我简化之后的代码在我和一个Collaborator的机器上测试,带 -O3 的编译选项也确实带来了一些速度的提升。这是因为 -O3 可能默认有做循环展开?
为了更聚焦,我就先介绍这些。详细的优化和原理,大家可以回去翻翻 CSAPP。书中有数据流图,非常清晰易懂。这里的原理和上边的疑问,我会在后边继续分析。
什么是 SIMD 和 AVX2
接下来介绍一下,背景中提到的分 12 倍以上的提升。@Nugine 做的优化,其实是针对的多个 key 的 PFCOUNT 和 PFMERGE。
我在前面介绍 Redis HyperLogLog 的文章中有介绍过,寄存器中的保存的是 pattern 0000…1的长度。如果要统计多个 Key 共同的计数值,只需要简单的将多个 HLL 的对应位置的寄存器值,取最大值即可,PFMERGE 功能类似,取最大值保存到新的寄存器即可。

Redis 中保存的寄存器是 dense 模式,也就是每个寄存器使用 6bit 来保存一个寄存器的值(保存50以内的数值,可以减少内存使用量)。因此要做上边对应寄存器取最大值,先要变成 raw 模式(以1Byte来保存每个值),然后进行 max。
优化之前,就是简单的通过按照位置与操作,通过掩码获得6位的值,然后通过移位操作,将其保存在 8bit 中,最后进行 max 操作。
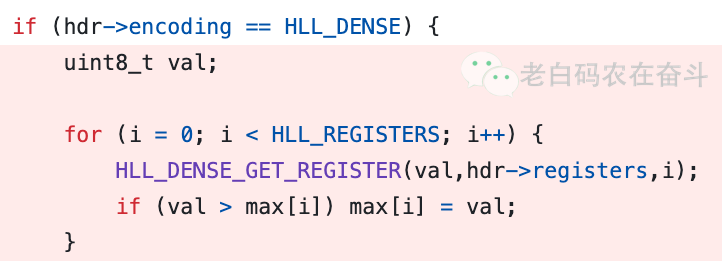
上述操作需要有循环寄存器个数的循环,而且每次循环中都需要多次位操作和一次比较操作。
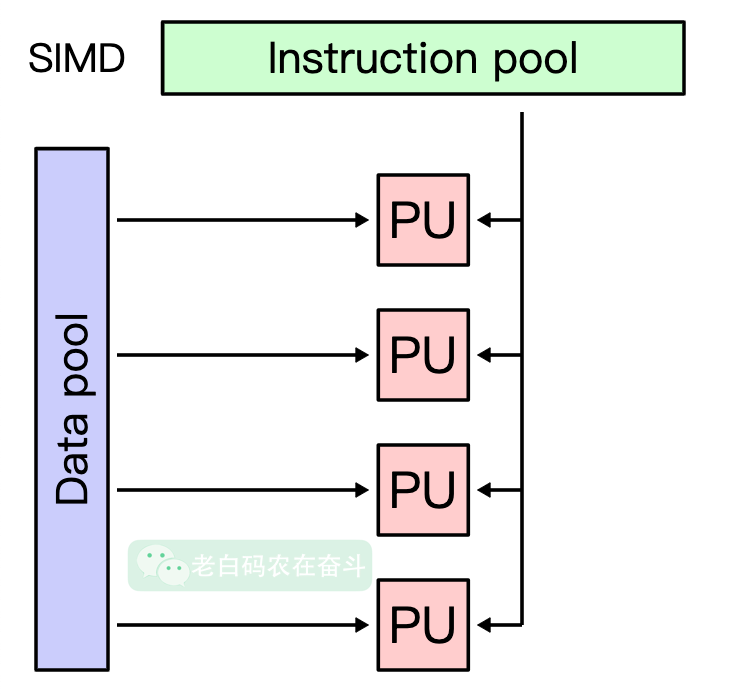
@Nugine 优化利用的是SIMD(Single Instruction, Multiple Data)计算机架构设计的技术,允许在同一时钟周期内对多个数据元素执行相同的操作。SIMD在图像处理、音频处理、科学计算和机器学习等领域有广泛的应用。
AVX2(Advanced Vector Extensions 2)是 SIMD(Single Instruction, Multiple Data)的一种具体实现。是 Intel 在其处理器架构中引入的一组指令集扩展,旨在提高数据并行处理的性能。AVX2 支持 256 位的宽度,这意味着它可以在单个指令中同时处理多个数据元素。
比如,优化中用到的几个函数:
_mm256_max_epu8:对两个 256 位的向量进行逐元素的无符号 8 位整数最大值比较_mm256_loadu_si256:从内存中加载一个 256 位的向量,支持未对齐的内存访问_mm256_shuffle_epi8:对两个 256 位的向量进行字节级别的重排,使用第二个向量中的字节作为索引_mm256_and_si256/_mm256_or_si256:对两个 256 位的向量进行逐元素的按位与操作 、 或操作_mm256_set1_epi32:创建一个 256 位的向量,其中所有的 32 位整数元素都被设置为相同的值_mm256_slli_epi32:对 256 位的向量中的每个 32 位整数进行左移操作,移动的位数由第二个参数指定
下边再看一下这段代码:
const uint8_t *r = reg_dense + 6 - 4;
uint8_t *t = reg_raw + 8;
for (int i = 0; i < HLL_REGISTERS / 32 - 1; ++i) {
__m256i x0, x;
x0 = _mm256_loadu_si256((__m256i *)r);
x = _mm256_shuffle_epi8(x0, shuffle);
__m256i a1, a2, a3, a4;
a1 = _mm256_and_si256(x, _mm256_set1_epi32(0x0000003f));
a2 = _mm256_and_si256(x, _mm256_set1_epi32(0x00000fc0));
a3 = _mm256_and_si256(x, _mm256_set1_epi32(0x0003f000));
a4 = _mm256_and_si256(x, _mm256_set1_epi32(0x00fc0000));
a2 = _mm256_slli_epi32(a2, 2);
a3 = _mm256_slli_epi32(a3, 4);
a4 = _mm256_slli_epi32(a4, 6);
__m256i y1, y2, y;
y1 = _mm256_or_si256(a1, a2);
y2 = _mm256_or_si256(a3, a4);
y = _mm256_or_si256(y1, y2);
__m256i z = _mm256_loadu_si256((__m256i *)t);
z = _mm256_max_epu8(z, y);
_mm256_storeu_si256((__m256i *)t, z);
r += 24;
t += 32;
}
其实这里的逻辑也不是很复杂:
- 我们知道6bit一个寄存器,所以4个寄存器占用3字节
- 上边的程序,从dense格式的内存中,加载了 256 bit 的内容,即32字节
- 但是经过shuffle,只保留了 24 字节,但是这24字节中有32个寄存器
- 接下来就有点奇幻了:
- 通过位与操作,分别将32个寄存器的内容,放在了4个256bit变量中
- 通过移位操作,将叫32个寄存器的内容,对齐到每个字节
- 通过256 bit 位或操作,将32个寄存器的内容,又合并到一个256bit的变量中
- 最后,将两个变量按字节比较大小,就得到了合并之后的结果
代码注释中有更好的解释,通过大写字母来表示字节,小写字母来表示 bit:
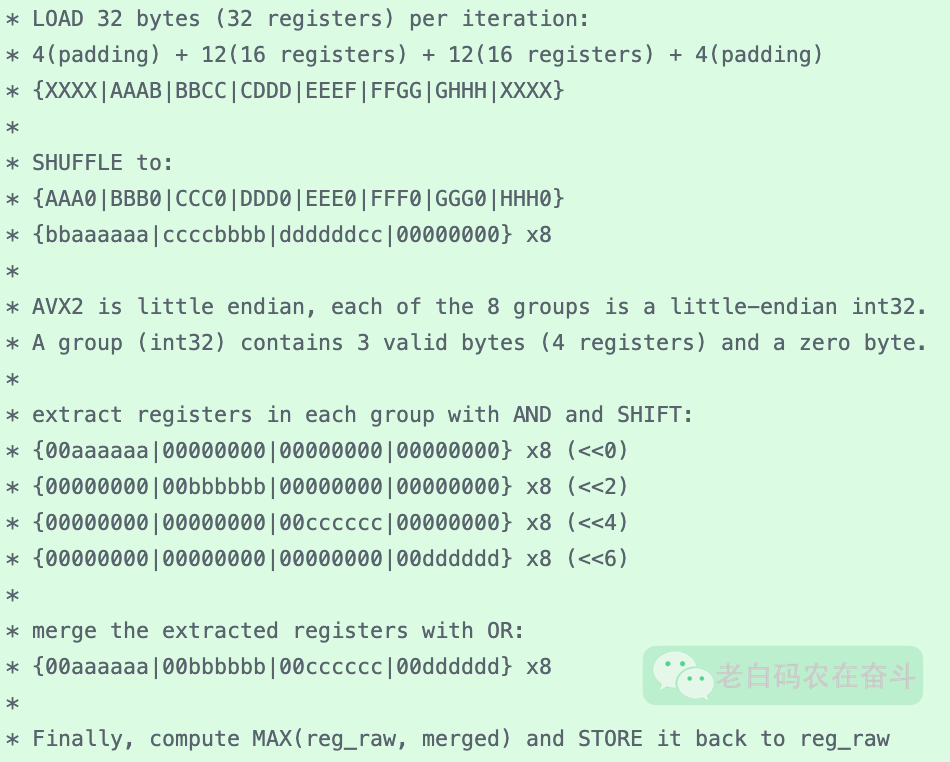
技术之外
或许因为快到35岁了,在学习技术之外,总会冒出点额外的思考。这里与大家分享一下。
成倍提升要跳脱当前层
很多的场景下,要解决问题,或者要提升性能,可能得跳脱当前层去思考。
场景一:这次优化中,单从程序编码层面来说,相信很多开发的思维都是 SISD(Single Instruction, Single Data,处理器在每个时钟周期内只能执行一条指令,并且每条指令只能操作一个数据元素)。而使用 SIMD 的优化,则是从编码层跳脱出来,到更底层的编译器层、处理器层。
场景二:对于 HyperLogLog 来说,也是不是改良了 HashSet 或者其他数据结构,而是从 算法层 上做了全面的革新,才得到了 O(1) 的 PFCOUNT。
场景三:HTTP2 固然能比 HTTP1 提高了网络性能和效率,但是我们今日能随时随地的刷短视频, 依赖的是3G、4G
场景四:前面文章有介绍过一次硬盘空间问题的排查记录,当时CVM遇到一个问题,查了一顿没任何线索,找运营商从母机上一个 fsck 就修复了
人可能也是这样,有时候当前环境遇到的问题,可能你做再多的努力去优化,收效甚微。
苟一苟也不一定是什么下策。
在我们自身之外,还有很多不同的层次,小到所在的单位,大到所在的时代,这些层次的一点点涟漪,都会给我们个人带来惊涛骇浪。
The more different things you know, the more valuable you are.
上边这句话,来自最近在看 《程序员修炼之道(第二版)》的英文原版,有一小节讲 Building your portfolio,其中的第二点提到的就是 Diversity。

蹭一蹭十月大家股市狂转的热点,这里有句本杰明富兰克林名言:An investment in knowledge always pays the best interest.
我这里顺便分享一下 Building your portfolio 这样小节的几个小点:
- Invest regularly: 书中有些具体的建议,比如每年学习一门新语言、每月读一本技术书,阅读非技术书籍,参加课程、会议、本地研讨,尝试使用不同的开发环境等
- Diversity: 无论是技术上知识,还是非技术上的技能,你了解的越多,你就越容易适应变化,这也让你个人变得更有价值
- Manage risk: 有些技术可能低风险高回报,但也有的是高风险低回报,记得不要把所有技术鸡蛋放在同一个篮子里
- Buy low, sell high: 提前发现并学习一些有价值的语言、技术,在他火起来的时候,会有丰厚的回报
- Review and rebalance: 软件开发是个动态发展的行业,个人应当经常性的刷新自己的技能库,在遇到合适的新工作机会的时候能快速适应
不必气馁
那是不是需要因为我想不到 SIMD 的优化,或者不知道上边这些256bit操作的函数,我就得气馁呢?倒也不至于。
反过来想想,我能从别人的提交中,学到了知识,也算一种进步吧。我还认真的看了 @Nugine 同学针对单 key 的利用 AVX2 做优化的一些压测和讨论,看完了之后,我就关闭了我的提交。在赞美别人的同时,也能收获到对方的肯定。
你看完了这篇文章,知道了这些 SIMD 的一些知识,是不是也比周围的人,也多了一点点知识?