HyperLogLog 简单介绍
潘忠显 / 2024-04-08
在前段时间的工作中,我这边有用到 Redis 的 HyperLogLog 来统计一些 UGC 内容的曝光 UV。
HyperLogLog 是一种用于估计大规模数据集基数(即集合中不同元素的数量)的概率性算法。使用的过程中,我发现它非常非常神奇:
- 内存使用量极低:使用最多 12KB 左右的数据,可以记录(估算)上亿甚至上亿亿的 UV
- 计算复杂度低:插入、查询的算法复杂度都是 O(1)
- 支持多个数据集的并集:可以将多个 Key 的 UV 进行去重合并,复杂度是 O(1)
- 结果是估计值,但其估计误差也非常的小
这篇短文只简单直观地介绍下 HyperLogLog 的工作原理,不涉及理论和证明,作为下一篇文章《透彻解析Redis中HyperLogLog的实现》的背景。
下一篇是对 redis 仓库中 hyperloglog.c 的详细解释说明,更值得一看。
即使你了解原理、看懂实现,再回头来看,依然会觉着这算法非常的神奇。
基数——唯一元素的计数
网站当日访问的去重 IP 数量,或者访问某个短视频的用户总数,就是所谓的“唯一元素的计数”。有个更专业的词表示这一概念:在数学集合论中,基数(cardinality,或翻译为势),即集合中包含的唯一元素的“个数”。
通常,这种计数需要记录截至当前遇到的所有唯一元素,以便在下一个元素到来时,判断是否是已经被计数过,仅当该元素以前从未出现过时才增加计数器。但是记录完整唯一元素的方法,在元素大到一定程度之后(比如短视频 APP 有1亿活跃用户,1亿条视频播放,要实时统计每条视频的UV),无论使用 Hash 表、搜索树、位图,其内存消耗会大到不能接受。
有一类随机算法,可以使用估算集合的基数。神奇的是这类算法只使用少量&固定的内存空间,且插入和统计的算法复杂度都是 O(1)。其中,HyperLogLog 算法就非常出色,使用非常少量的内存,同时可以很好地估算基数。HyperLogLog 之所以叫 HyperLogLog,是因为它在 LogLog 算法基础上做的改进,而之前还有Linear Counting算法。
在 Redis 中实现的 HyperLogLog,每个 key 仅使用 12kB + 16B 进行计数,标准误差为 0.81%(standard error 如何定义的),并且可以计数的项目数量几乎没有限制(除非基数接近 2^64 -> 18亿亿)。而且 HLL 还可以 O(1) 的算法复杂度 merge 两个计数器!
HyperLogLog 由 Philippe Flajolet 在 原始论文《HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm》 中提出。Redis 中对 HLL 的三个 PFADD/PFCOUNT/PFMERGE,都是以 PF 开头,就是纪念 2011 年已经去世的 Philippe Flajolet 。

2013 年 Google 的 一篇论文《HyperLogLog in Practice: Algorithmic Engineering of a State of The Art Cardinality Estimation Algorithm》 深入介绍了其实际实现和变体。
HyperLogLog 简单原理
接下来,将根据这篇文章中的一个非常智慧的示例,来介绍一下 HyperLogLog 的工作原理。
我们来考虑一个这样的场景:我要求你花一段时间来抛硬币,并记录连续抛硬币中连续正面最多的次数,我会用它来猜测你抛硬币的总次数。直观地讲,如果你花了一段时间抛硬币若干次,而你看到的最长连续正面次数是 3,我可以猜到你抛硬币的总次数一定不多。而如果你告诉我你看到了连续 100 个正面朝上,我猜你已经抛硬币很长很长时间了。

当然,你可能很幸运,会在从一开始就连续抛出了 10 次正面,然后停止抛硬币(这是个小概率事件,但是确实可能发生)。那根据这“连续抛出10次正面”的描述,我将会提供一个错的离谱的抛硬币总数的估计值。
所以,可以改进一下这个实验,我会给你10个硬币和和10张纸,你需要轮换着来抛这10枚硬币,每张纸记录每个硬币连续正面最多的次数。这样可以观察到更多的数据,我再评估就会更准确。
HyperLogLog 的原理类似:它对要加入的每个新元素进行 Hash 处理。Hash 的一部分用于索引寄存器(对应前面前面的示例中的某对【硬币+纸对】,作用是将原始集合分成 m 个子集);另一部分用于计算哈希中最长的前导零序列(对应前面硬币连续正面的最大次数)。
HyperLogLog 根据寄存器数组中的值(这些寄存器被设置为迄今为止针对给定子集观察到的最大连续零),计算出估计的基数,并应用修正公式来纠正估计误差, 能够提供非常好的近似基数。
Redis 中的实现
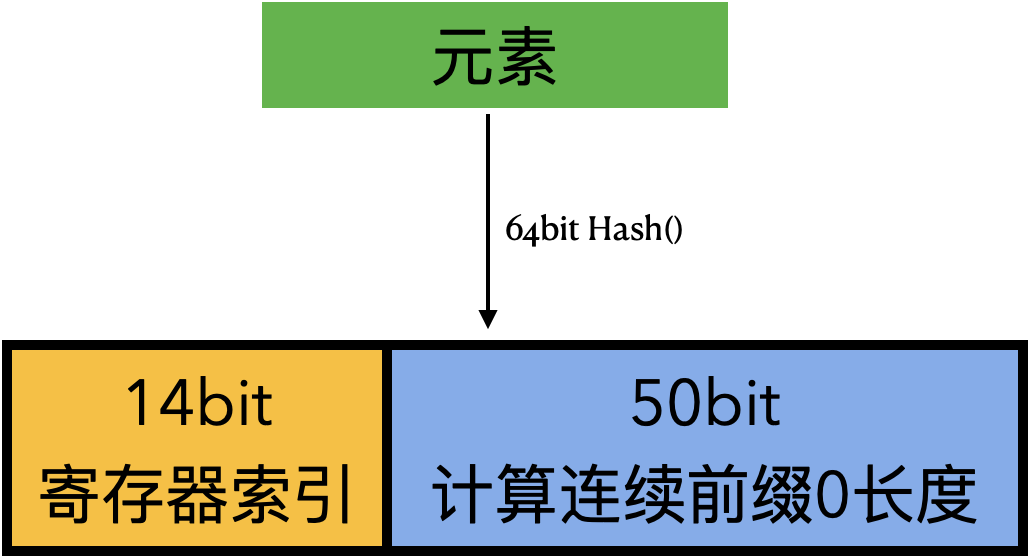
Redis 中,HyperLogLog 使用 64bit 的 Hash 函数,14bit 用于寄存器索引,剩下的 50bit 用于计算前导 0 的个数。
具体地,Redis 中 HLL 有 16384(2^14)个寄存器,其中存的值的范围是 0 ~ 50(实际是0~51,在Redis实现 HLL的文章中有介绍)。我们使用 6bit 就可以存储下 0~50 的所有值,所以需要的存储空间是 16384 * 6bit / (8bit/Byte) = 12288 Byte 也就是开头说的 12KB。
实际上 Redis 中对 HyperLogLog 的存储也是个 字符串,只不过这个字符串有个固定格式的头部(16字节)。
HyperLogLog 的标准误差为 1.04/sqrt(m),其中 m 是使用的寄存器数量,因此 Redis HLL 标准误差为 0.81%。
关于 HyperLogLog 有三个指令:
PFADD var element1 element2 ...:向一个 key 中加入一个或多个元素PFCOUNT var:获取一个 key 中的基数评估PFCOUNT var1 var2 ...:获取多个 key 合并后的基数评估PFMERGE dst src1 src2 ...:将多个 key 合并成1个存储到 dst 中