spdlog 中的 C++ 技巧
潘忠显 / 2022-07-01
spdlog 是一个用起来非常方便的 C++ 日志库。这里整理了在阅读 spdlog 源码时学到一些技术点:相对深入地介绍了头文件库和静态库的区别、锁应该如何使用、容器和容器适配器的关系、如何实现线程安全的队列、利用注册器带来编程便利等内容。也欢迎阅读另外一篇《gRPC代码中的C/C++技巧》
我自己写了一个处理日志的代理,实现通过配置创建多个接收器监听网络请求/本地文件变更,也能够配置多个导出器将经过不同处理的消息发送给不同的接收端。其中,就利用了 spdlog 库构造文件导出器。
一、头文件库 vs. 静态库
Header-only Library 是只需要 include 头文件即可,而不需要使用 .cc 源文件构建出静态库或动态库,这会给使用者带来很大的便利。我们如果提供给别人一些简单库时,也可以是使用 Header-only Library 的方式。
常用的这类库有 RapidJson、spdlog 等,但他们的实现形式上还稍有不同。
- RapidJson 中只有
.h文件类型,一个.h文件处理一块完整的逻辑,比如document.h - spdlog 中有
.h和-inl.h两种文件,大部分成对出现
spdlog 这种组织方式,是为了支持用户自行选择何种方式使用 spdlog:既可以选择以头文件库方式,也可以选择使用静态库的方式。
两种库的区别
既然头文件库这么便利,为什么还会有人选择使用静态库呢?**因为头文件库在提供便利的同时,也带来代价:每次的编译时间增加。**在第三方库没有变更的情况下:
- 以静态库的方式,每次构建主程序时只需要进行符号链接
- 以头文件库的方式,每次构建主程序都需要对库进行编译、链接
以 spdlog/example 的代码作为示范,分别展示使用两种方式进行构建的耗时:
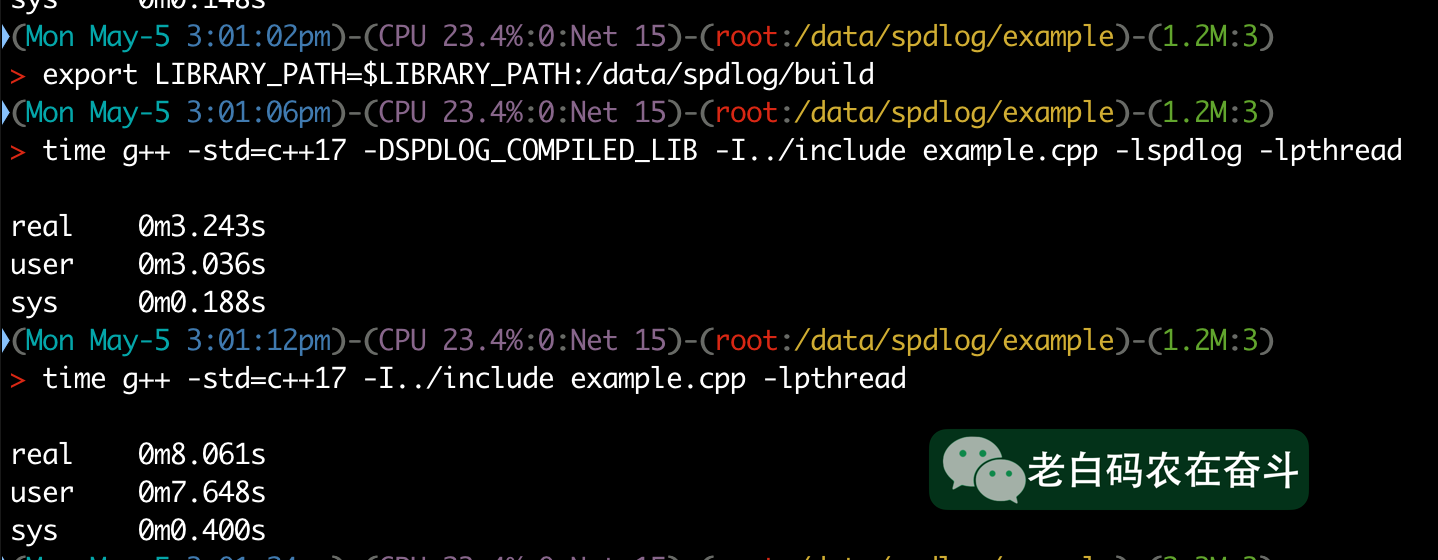
通过宏定控制库的类型
logger.h 中,先像普通的头文件一样,定义类、声明普通函数、定义模板函数,在文件最后的部分,有判断是否存在 SPDLOG_HEADER_ONLY 宏定义:
#ifdef SPDLOG_HEADER_ONLY
# include "logger-inl.h"
#endif
logger-inl.h 中,在文件的开头,判断是否存在 SPDLOG_HEADER_ONLY 宏定义,若没有定义,则像普通的 C++ 源文件一样,#include 对应的头文件:
#ifndef SPDLOG_HEADER_ONLY
# include <spdlog/logger.h>
#endif
上边提到的 SPDLOG_HEADER_ONLY 宏定义在 common.h,所有的 spdlog 的头文件都会 include 最基础的头文件:
#ifdef SPDLOG_COMPILED_LIB
# undef SPDLOG_HEADER_ONLY
# define SPDLOG_INLINE
#else // !defined(SPDLOG_COMPILED_LIB)
# define SPDLOG_API
# define SPDLOG_HEADER_ONLY
# define SPDLOG_INLINE inline
#endif // #ifdef SPDLOG_COMPILED_LIB
这么做的原因是:spdlog 可能认为更多的人会选择头文件库的方式去使用,所以只有需要静态库的方式才需要额外的编译选项,而 SPDLOG_HEADER_ONLY 则是为了更好的代码可读性。
伴随 SPDLOG_HEADER_ONLY 一起定义的还有另外两个:
#define SPDLOG_API用于兼容不同平台的函数定义#define SPDLOG_INLINE inline表示在以头文件库提供时,函数以 inline 的方式编译
剩下的工作就是编写 CMakeList.txt 用于构建出静态库了(头文件库不需要做额外的操作)。
spdlog ISSUE #120 中讨论了静态库的支持工作。
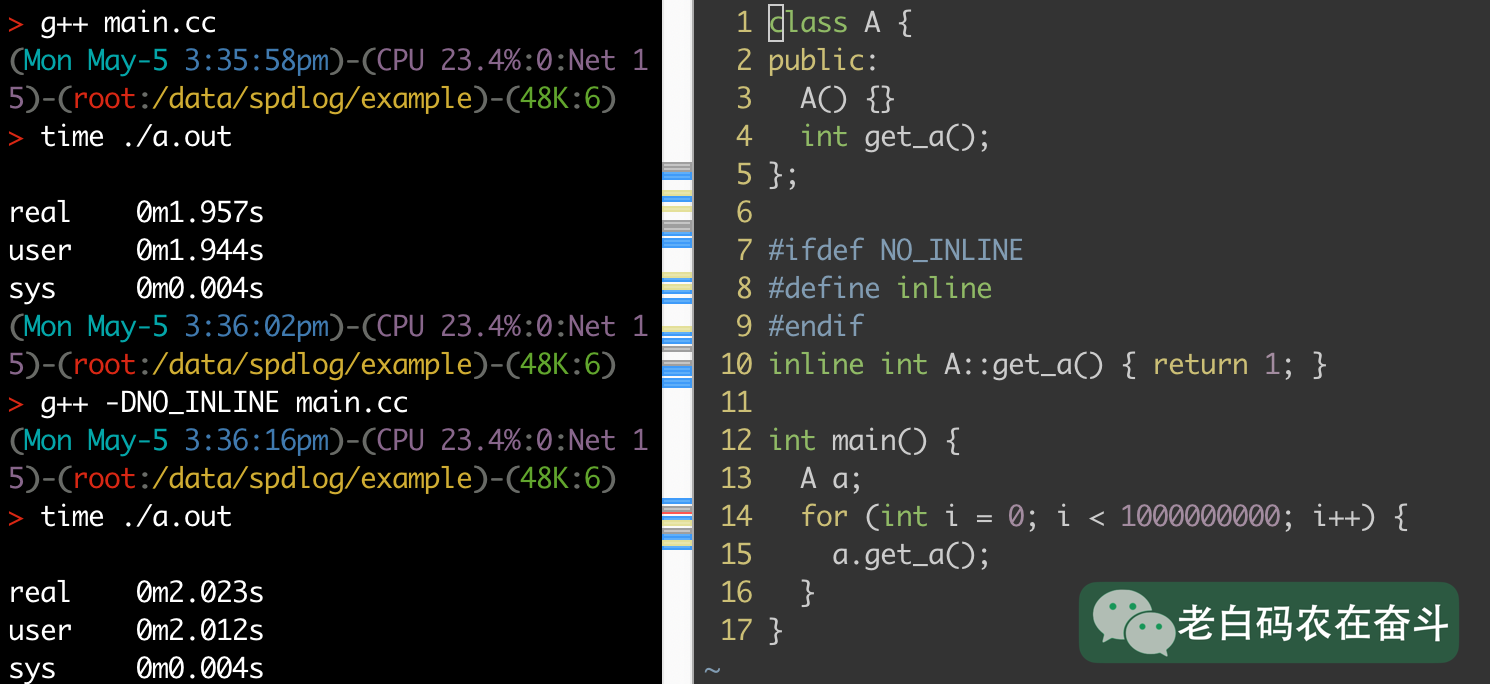
inline 编译
接下来聊聊为什么 头文件库的时候,需要将函数定义为inline,而静态库的时候不要。
inline “不能” 放在 .cpp 文件中
这里说不能是加引号的,C++ FAQ 中有提到,除非一个 inline 函数在对应头文件的 .cpp 文件中使用,不然外部使用该函数时,会报 “undefined reference to xxx” 的错误。
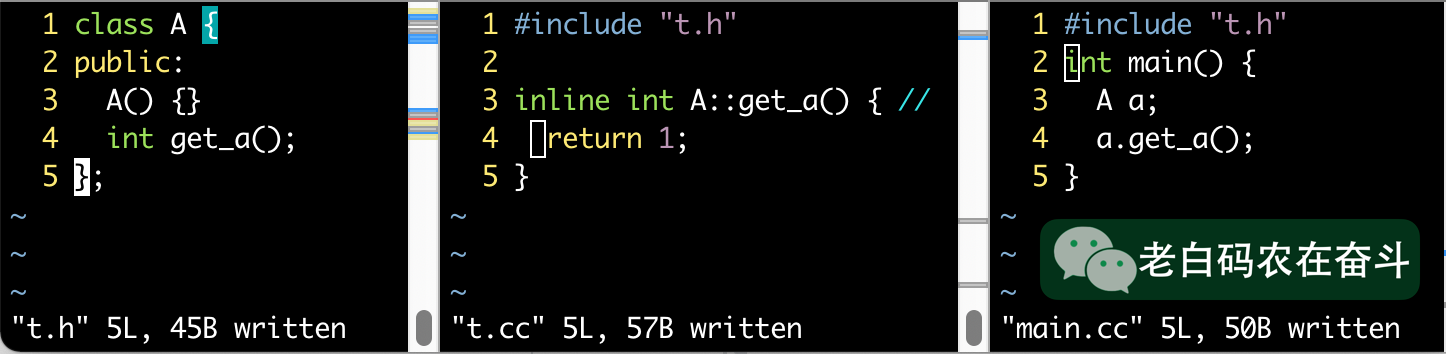
构建:
g++ t.cc main.cc
链接错误:
/tmp/ccLw3WSW.o: In function `main':
main.cc:(.text+0x1c): undefined reference to `A::get_a()'
collect2: error: ld returned 1 exit status
header 中的函数使用 inline
在类声明中定义的函数默认是 inline 的:
class Fred {
public:
void f(int i, char c) { /* ... */ }
};
但是上边这种方式影响可读性:会做什么(函数声明)和如何做(函数定义)混在一起。所以通常会将其分开:
class Fred {
public:
void f(int i, char c);
};
inline void f(int i, char c) { /* ... */ }
带 inline 跟上边定义在类内部是相同的效果;如果去掉 inline,不是将代码展开,而是调用另外的函数,会降低性能。
二、如何用锁
spdlog 中也提供两种类型的 logger,线程安全 _mt (multiple-thread 的缩写) 和非线程安全 _st (single-thread的缩写) 的接口:
using rotating_file_sink_mt = rotating_file_sink<std::mutex>;
using rotating_file_sink_st = rotating_file_sink<details::null_mutex>;
如果创建了一个 logger,确定只在单个线程中使用,那就没有必要使用锁,因为使用锁会带来额外的开销:单个线程取锁,也会进行额外的trylock。接下来跟着 spdlog 学学如何使用锁。
lock_guard 源码
以 GNU C++ Library 中对 lock_guard 实现源码(微软的实现也类似)为例,我们看看这个 std::lock_guard 做了什么:
template<typename _Mutex>
class lock_guard
{
public:
typedef _Mutex mutex_type;
explicit lock_guard(mutex_type& __m) : _M_device(__m)
{ _M_device.lock(); }
lock_guard(mutex_type& __m, adopt_lock_t) : _M_device(__m)
{ } // calling thread owns mutex
~lock_guard()
{ _M_device.unlock(); }
lock_guard(const lock_guard&) = delete;
lock_guard& operator=(const lock_guard&) = delete;
private:
mutex_type& _M_device;
};
跟我们想象的一样:
lock_guard是一个类模板,接受一个 BasicLockable 类型的形参BasicLockable要求类型需要具有m.lock()和m.unlock()两个函数lock_guard在构建时调用m.lock(),在析构时调用m.unlock()
空互斥量
前边单线程代码不需要使用锁,但同时为了复用代码,spdlog 直接将锁的类型作为模板参数。多线程的时候使用 std::mutex,而单线程的时候就使用自定义的空锁 null_mutex:
struct null_mutex {
void lock() const {}
void unlock() const
};
锁的粒度
以 spdlog 里边最重要的 sink 为例,先看下他的类之间的继承关系:
- 基类
class sink是个“抽象类”,声明了需要实现的纯虚函数而无法被实例化 - 类模板
template<typename Mutex> class base_sink继承sink类,实现了大部分 sink 接口log(const log_msg&)、flush()、set_pattern()、set_formatter(),但是每个 sinker 不同的sink_it_和flush_()两个函数作为纯虚函数,需要子类来实现 - 类模板
class rotating_file_sink继承base_sink<Mutex>并实现了sink_it_()和flush_(),在sink_it_()的时候判断文件大小是否需要 rotate,如果需要则在此进行文件旋转
**为保证多线程之间的同步,sink 过程中会使用锁,而这个锁的范围该如何设置呢?**在类模板 base_sink 中使用,在 log(const log_msg&)、flush()、set_pattern()、set_formatter() 函数范围内会使用 lock_guard 进行保护:
template<typename Mutex>
void SPDLOG_INLINE spdlog::sinks::base_sink<Mutex>::log(const details::log_msg &msg) {
std::lock_guard<Mutex> lock(mutex_);
sink_it_(msg);
}
针对同一种资源,更大范围内加锁了,其中一部分小范围就不用也不应该加锁。因此,在调用特例化类型的 sink_it_() 的外层函数 log() 里边已经加了锁,在 sink_it_() 中是不需要再加锁的。
不需要额外的线程 rotate 文件:因为在几乎每个用户调用的函数上都会加锁,在其中的任何一个函数中 rotate 就可以阻塞住其他线程,所以不需要额外的线程去做单独的 rotate 动作。
三、线程安全的循环队列
spdlog 中定义了两个队列:循环队列 circular_q 和线程安全的 mpmc_blocking_queue。MPMC 是指多生产者/多消费者(Multiple Producer Multiple Consumer)。
接下来会先说明容器不是线程安全的,然后看看如何实现一个线程安全的循环队列。
容器与容器适配器
容器是为了有效地存储数据,比如 std::array、std::vector、std::list、std::deque。
std::deque (double-ended queue) is an indexed sequence container that allows fast insertion and deletion at both its beginning and its end. In addition, insertion and deletion at either end of a deque never invalidates pointers or references to the rest of the elements.
容器适配器是在容器的基础上包了一层,增加了一些限制,比如 std::stack、std::queue、std::priority_queue。
The std::stack class is a container adaptor that gives the programmer the functionality of a stack - specifically, a LIFO (last-in, first-out) data structure.
要实现一个 stack 可以使用 std::vector、std::list、std::deque,但实现上往往会选择效率相对较高的实现方式。比如 GCC 在 std::stack 的实现中,默认选用的就是 std::deque:
// This is not a true container, but an @e adaptor. ...
template<typename _Tp, typename _Sequence = deque<_Tp> >
class stack {...}
容器不是线程安全
容器的某些函数是线程不安全的,即多线程并发的调用,会造成数据不一致,甚至程序崩溃。
简单地,可以将容器理解为两部分:开辟一块内存空间存放数据,额外的信息存储内存空间和容器状态的信息。这样对理解 std::vector 不是线程安全的就比较简单。
再以 vector::push_back() 成员函数为例,每次调用该函数:会往已经开辟的内存空间中塞数据,如果数据多到原来的内存塞不下,就需要新开辟一块空间。具体地,看 push_back() 的定义中,先会判断当前结尾元素是否已经达到了之前申请的内存边界,如果已经达到,则会调用 _M_realloc_insert() 分配新的空间,然后插入元素:
void push_back(const value_type& __x) {
if (this->_M_impl._M_finish != this->_M_impl._M_end_of_storage) {
...
} else
_M_realloc_insert(end(), __x);
}
而 _M_realloc_insert() 的实现中的会申请新的内存,搬移老数据,最后销毁旧的内存,将指针指向新的内存地址:
template <typename _Tp, typename _Alloc>
void vector<_Tp, _Alloc>::_M_realloc_insert(iterator __position,
const _Tp& __x) {
...
std::_Destroy(__old_start, __old_finish, _M_get_Tp_allocator());
_GLIBCXX_ASAN_ANNOTATE_REINIT;
_M_deallocate(__old_start, this->_M_impl._M_end_of_storage - __old_start);
this->_M_impl._M_start = __new_start;
this->_M_impl._M_finish = __new_finish;
this->_M_impl._M_end_of_storage = __new_start + __len;
...
}
多个线程如果同时调用 push_back(),就可能造成一个线程在销毁一块内存,而另外一个线程同时在往这块内存上写数据(“Segmentation fault” 等运行时错误),或者两个线程同时销毁同一块内存(“double free or corruption”)。
容器不是线程安全的,那么依赖于容器的容器适配器也就不是线程安全的。写一个简单的测试程序,下边的程序基本不会正常退出:
// g++ -g st_vector_test.cc -pthread
#include <cassert>
#include <thread>
#include <vector>
int main() {
constexpr int kQueueLen = 100000;
for (int i = 0; i < 10; i++) {
std::vector<int> v_;
auto x = [&v_]() {
while (v_.size() < kQueueLen) {
v_.push_back(1);
}
};
std::thread t1(x);
std::thread t2(x);
t1.join();
t2.join();
assert(v_.size() == kQueueLen);
}
}
循环队列
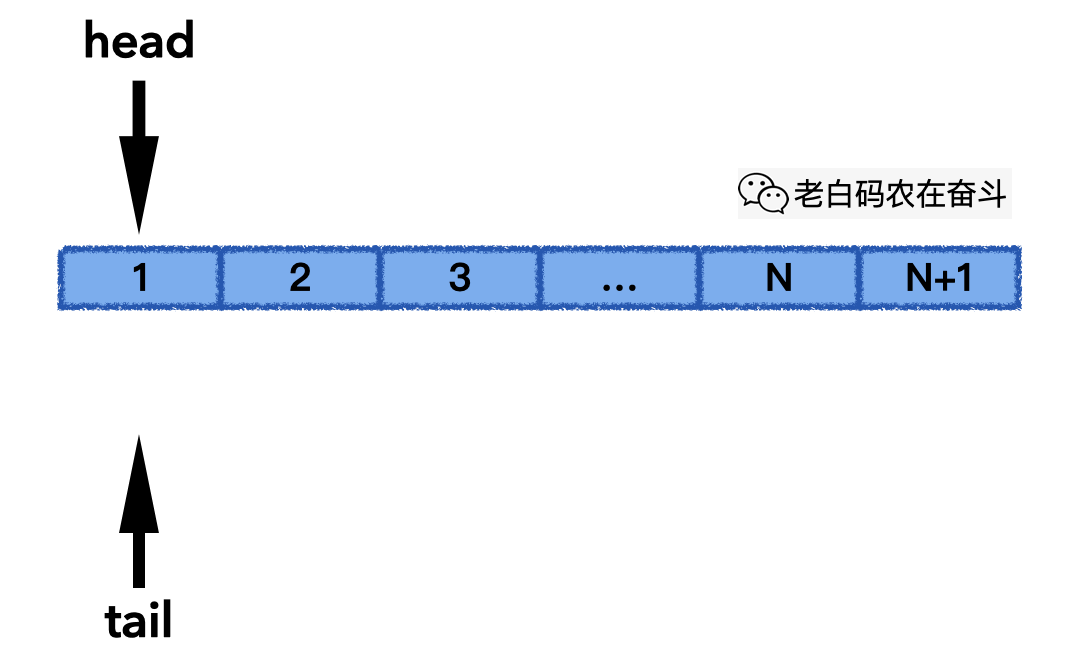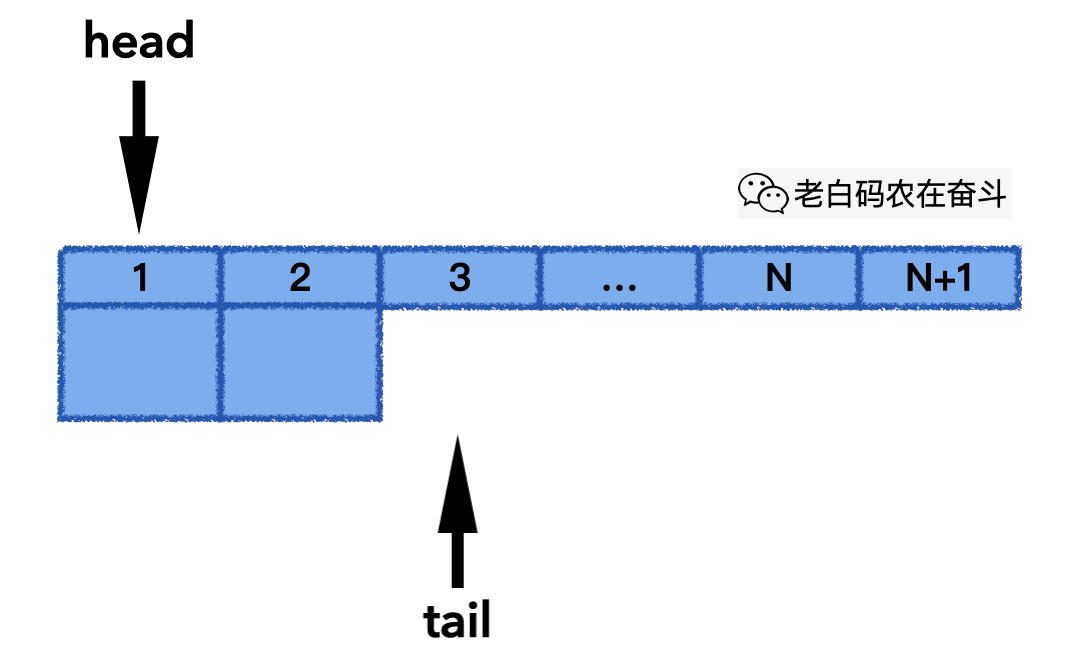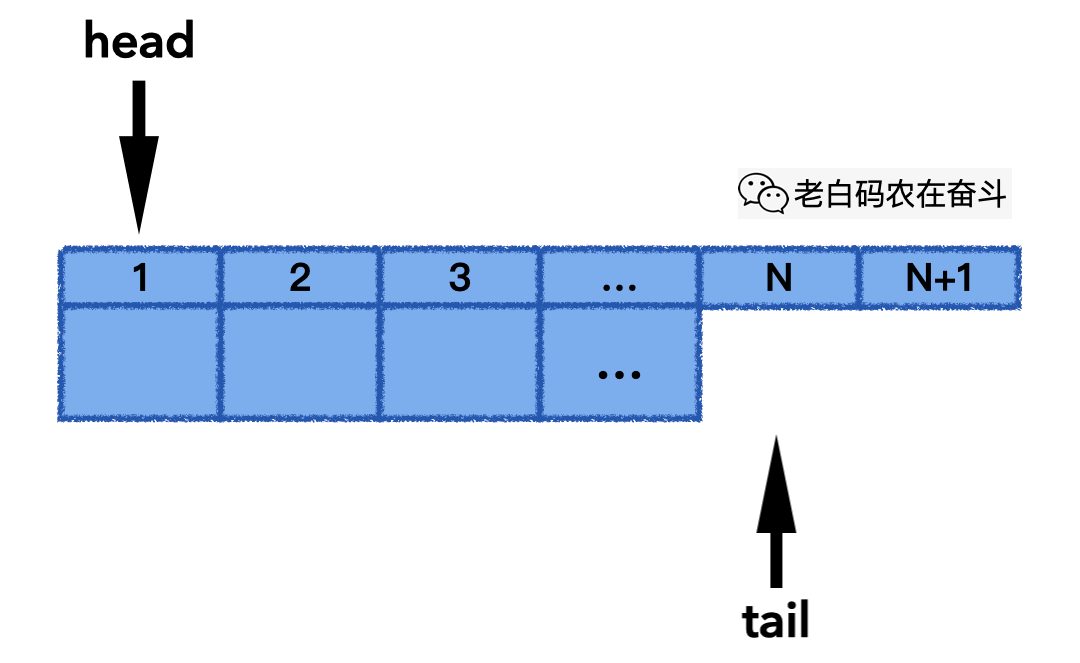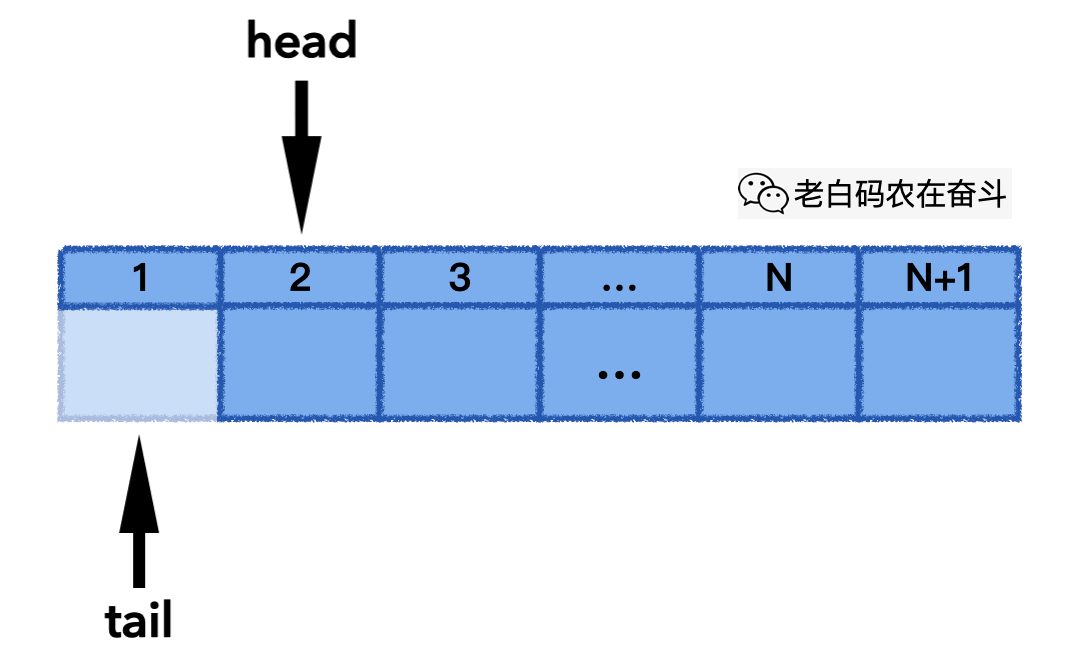
“circular_q.h” 文件中,以 std::vector 容器作为存储,封装了一个循环队列。他有几个要素:
- 循环队列最大能容纳元素
max_items_个 - 使用大小为
max_items_ + 1的向量保留元素,额外留一个用于标识队列满 - 使用下标维护头和尾,head 指向真正头的位置,而每次 tail 总指向下一个要填充的位置
- 使用
((tail_ + 1) % max_items_) == head_判断队列满;使用tail_ == head_判断队列空 - 队列满时覆盖最老的元素,记录被覆盖的次数
下面的动画展示了其 push_back() 的实际过程,最后一次发生覆盖,head 也会往后移动,一直保持 N 个最新元素:
下面的动画展示了其 pop_front() 的实际过程,当 head 往后移动,直到 head 和 tail 指到同一个位置,意味着队列变空:
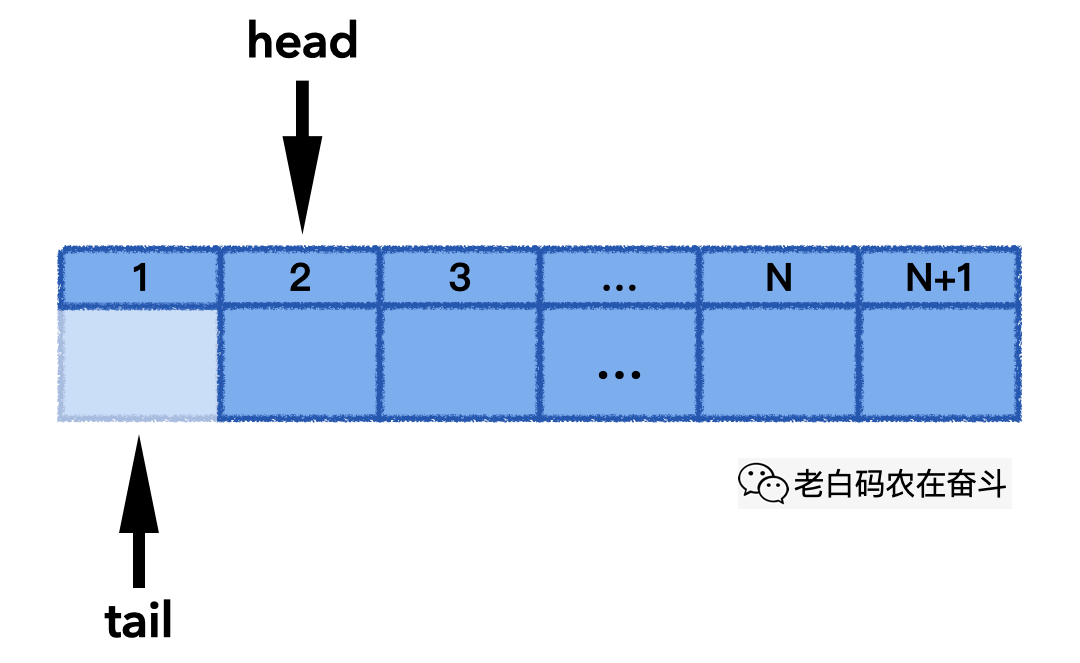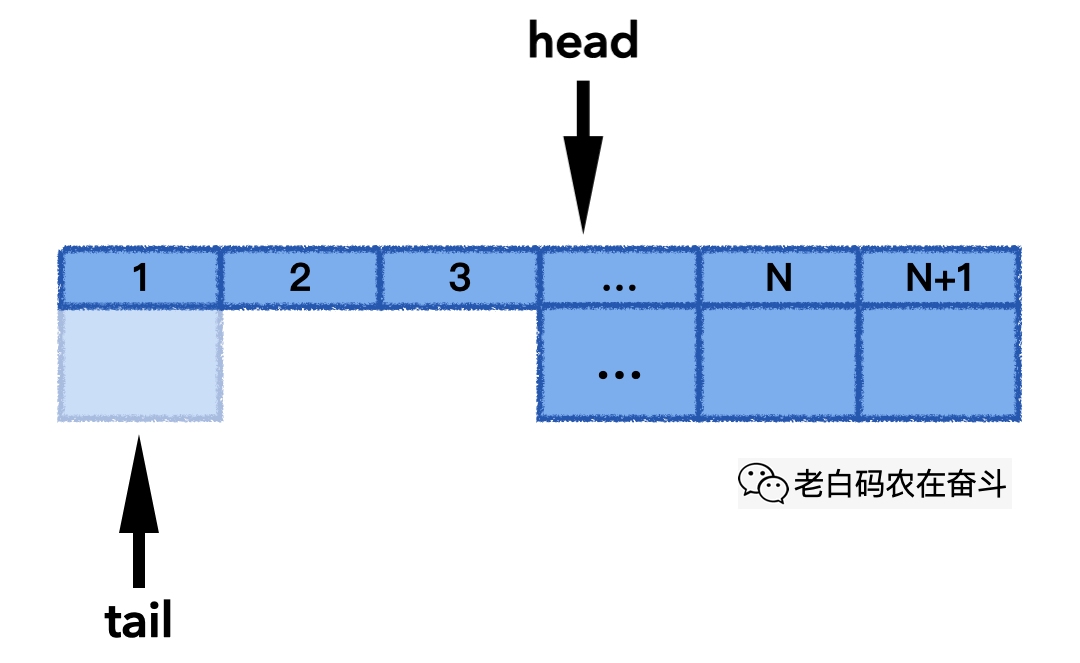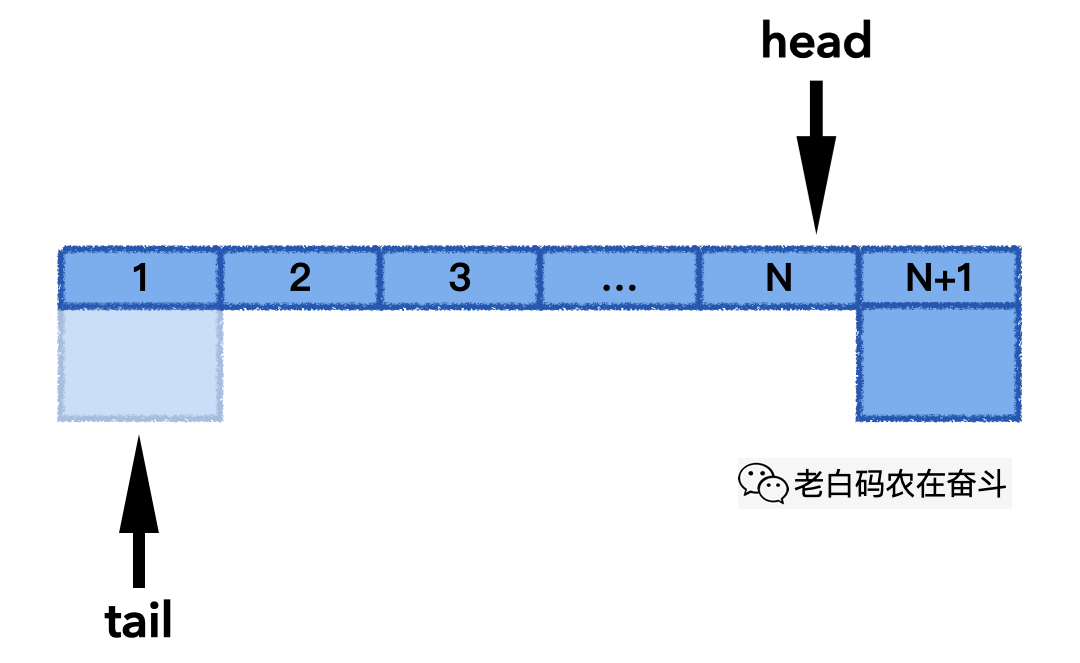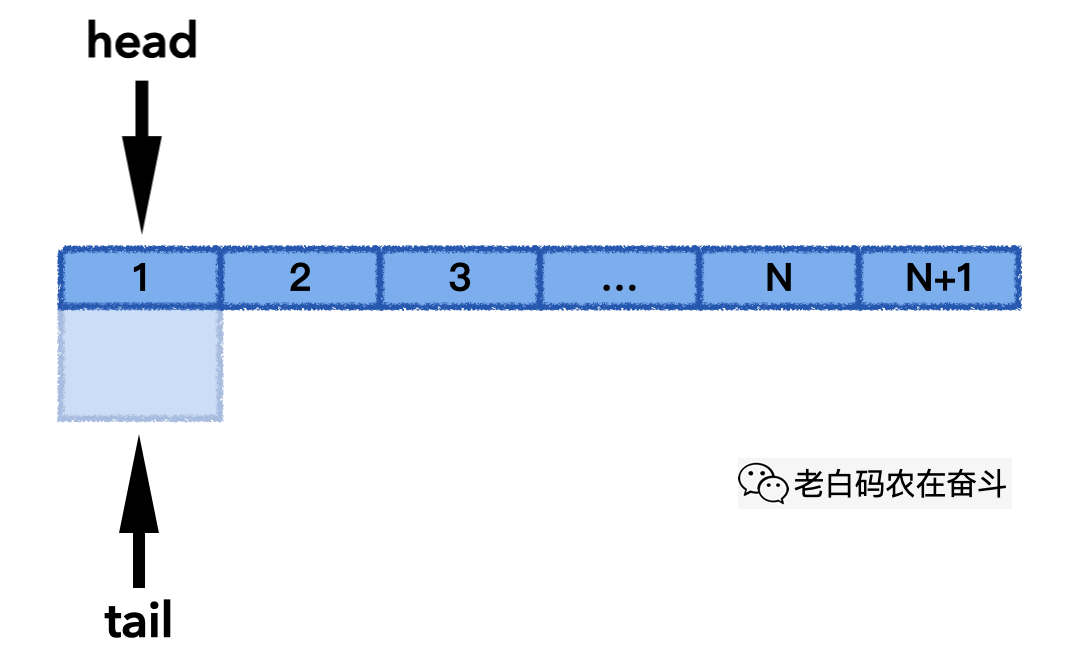
线程安全循环队列
这个循环队列和普通队列有一个区别:底层用户存储的 std::vector 因为大小从一开始就不会变化,所以不会发生重新分配空间。如果不加任何的同步控制,多线程调用该循环队列的成员函数,不会发生程序崩溃,但是会有数据不一致的情况。
线程安全的类 mpmc_blocking_queue 使用 circular_q 作为存储,使用了以下成员变量控制同步:
- 队列锁
queue_mutex_,基本上每个成员函数调用的时候,都会先调用该锁进行保护 - 条件变量
push_cv_,用于队列满时wait_for(),在 pop 成功后notify_one()通知可以 push - 条件变量
pop_cv_,用于队列空时wait_for(),在 push 成功后notify_one()通知可以 pop
以 enqueue 为例,我们他调用 pop_cv_.wait() 阻塞到队列非空;在将元素入队列后,调用 push_cv_.notify_one() 通知可以取。
void enqueue(T &&item) {
{
std::unique_lock<std::mutex> lock(queue_mutex_);
pop_cv_.wait(lock, [this] { return !this->q_.full(); });
q_.push_back(std::move(item));
}
push_cv_.notify_one();
}
之前的文章有介绍过虚假唤醒,这里在 wait() 的时候,需要填上校验的函数,等价于:
while (!this->q_.full()) {
pop_cv_.wait(lock);
}
四、注册机制
spdlog 提供了一种比较方便的使用方式:在任何代码片段中,可以创建一个 logger 并将其进行注册;在其他的代码片段中,可以通过logger的名称获得该对象,记录日志。
注册新的 logger:
auto net_logger = std::make_shared<spdlog::logger>("net", daily_sink);
spdlog::register_logger(net_logger);
其他地方根据名字获取 logger,并利用其记录日志:
auto l = spdlog::get("logger1");
l->info("hello again");
利用静态变量实现单例
SPDLOG_INLINE registry ®istry::instance() {
static registry s_instance;
return s_instance;
}
利用 unordered_map 存储映射
注意使用 lock_guard 进行保护
// std::unordered_map<std::string, std::shared_ptr<logger>> loggers_;
SPDLOG_INLINE void registry::register_logger_(std::shared_ptr<logger> new_logger)
{
auto logger_name = new_logger->name();
throw_if_exists_(logger_name);
loggers_[logger_name] = std::move(new_logger);
}
SPDLOG_INLINE void registry::register_logger(std::shared_ptr<logger> new_logger)
{
std::lock_guard<std::mutex> lock(logger_map_mutex_);
register_logger_(std::move(new_logger));
}
封装函数不暴露 registry 实例
namespace spdlog {
SPDLOG_INLINE void set_formatter(std::unique_ptr<spdlog::formatter> formatter) {
details::registry::instance().set_formatter(std::move(formatter));
}
} // namespace spdlog