潘忠显 / 2021-04-18
“JavaScript 工作原理”系列文章是翻译和整理自 SessionStack 网站的 How JavaScript works。因为博文发表于2017年,部分技术或信息可能已经过时。本文英文原文链接,作者 Alexander Zlatkov,翻译 潘忠显。
How JavaScript works: WebRTC and the mechanics of peer to peer networking

Jul 5, 2018 · 13 min read

This is post # 18 of the series dedicated to exploring JavaScript and its building components. In the process of identifying and describing the core elements, we also share some rules of thumb we use when building SessionStack, a JavaScript application that needs to be robust and highly-performant to help users see and reproduce their web app defects real-time.
If you missed the previous chapters, you can find them here:
- An overview of the engine, the runtime, and the call stack
- Inside Google’s V8 engine + 5 tips on how to write optimized code
- Memory management + how to handle 4 common memory leaks
- The event loop and the rise of Async programming + 5 ways to better coding with async/await
- Deep dive into WebSockets and HTTP/2 with SSE + how to pick the right path
- A comparison with WebAssembly + why in certain cases it’s better to use it over JavaScript
- The building blocks of Web Workers + 5 cases when you should use them
- Service Workers, their life-cycle, and use cases
- The mechanics of Web Push Notifications
- Tracking changes in the DOM using MutationObserver
- The rendering engine and tips to optimize its performance
- Inside the Networking Layer + How to Optimize Its Performance and Security
- Under the hood of CSS and JS animations + how to optimize their performance
- Parsing, Abstract Syntax Trees (ASTs) + 5 tips on how to minimize parse time
- The internals of classes and inheritance + transpiling in Babel and TypeScript
- Storage engines + how to choose the proper storage API
- The internals of Shadow DOM + how to build self-contained components
Overview
So what is WebRTC? First of all RTC stands for Real Time Communication which already gives a lot of information about this technology.
WebRTC fills a critical gap in the web platform. Previously, P2P technologies such as desktop Chat apps could do something that the web couldn’t. WebRTC changes that.
WebRTC basically allows web apps go create Peer-To-Peer communication, which we’ll discuss in this post. We’ll also discuss the following topics, in order to give you the full picture on the internals of WebRTC:
- Peer-To-Peer communication
- Firewalls and NAT Traversal
- Signaling, Sessions, and Protocols
- WebRTC APIs
Peer-To-Peer Communication
In order to communicate with another peer via a web browser, each person’s web browser must go through the following steps:
- Agree to begin communication
- Know how to locate one another
- Bypass security and firewall protections
- Transmit all multimedia communications in real-time
One of the biggest challenges associated with browser-based peer-to-peer communications is knowing how to locate and establish a network socket connection with another web browser in order to bidirectionally transmit data. We’ll go through the difficulties, associated with establishing this connection.
When your web application needs some data or a resource, it fetches it from some server and that’s it. If you, however, want to create a peer-to-peer video chat, by directly connecting to someone else’s browser — you don’t know the address since the other browser is not a known web server. So, in order to establish a p2p connection, more is needed.
Firewalls and NAT Traversal
Your computer doesn’t typically have a static public IP address assigned. The reason is that your computer is sitting behind a firewall and a network access translation device (NAT).
A NAT device is a device that translates private IP addresses from inside a firewall to public-facing IP addresses. NAT devices are needed for security and IPv4 limitations on available public IP addresses. This is why your web application shouldn’t assume that the current device has a public static IP address.
Let’s see how a NAT device works. If you’re on a corporate network and join the WiFi, your computer will be assigned an IP address that exists only behind their NAT. Let’s say that the IP is 172.0.23.4. To the outside world, however, your IP address may look like 164.53.27.98. The outside world will therefore see your requests as coming from 164.53.27.98 but the NAT device will ensure that the responses to the requests, performed by your machine will be sent to the internal, 172.0.23.4. This happens thanks to mapping tables. Note that in addition to the IP address, a port is also required for network communications.
Given the involvement of a NAT device, your browser needs to figure out the IP address of the machine, which has the browser you want to communicate with.
This is where Session Traversal Utilities for NAT (STUN) and Traversal Using Relays around NAT (TURN) servers come into the picture. In order for WebRTC technologies to work, a request for your public-facing IP address is first made to a STUN server. Think of it like your computer making a query to a remote server, which is asking what is the IP address it receives the query from. The remote server then responds with the IP address it sees.
Assuming this process works and you receive your public-facing IP address and port, you are then able to tell other peers how to connect to you directly. These peers are also able to do the same thing using a STUN or TURN server and can tell you what address to contact them at as well.
Signaling, Sessions, and Protocols
The network information discovery process described above is one part of the larger topic of signaling, which is based on the JavaScript Session Establishment Protocol (JSEP) standard in the case of WebRTC. Signaling involves network discovery and NAT traversal, session creation and management, communication security, media-capability metadata and coordination, and error handling.
In order for the connection to work, peers must acquire local media conditions (resolution and codec capabilities, for instance) for metadata, and gather possible network addresses for the application’s host. The signaling mechanism for passing this crucial information back and forth is not built into the WebRTC API.
Signaling is not specified by the WebRTC standard, and it’s not implemented by its APIs in order to allow flexibility in the technologies and protocols used. Signaling and the server that handles it is left to the WebRTC app developer to deal with.
Assuming that your WebRTC browser-based app is able to determine it’s public-facing IP address using STUN as described, the next step is to actually negotiate and establish the network session connection with the peer.
The initial session negotiation and establishment happens using a signaling/communication protocol specialized in multimedia communications. This protocol is also responsible for governing the rules by which the session is managed and terminated.
One such protocol is the Session Initiation Protocol (called SIP). Note that due to the flexibility of WebRTC signaling, SIP is not the only signaling protocol that can be used. The signaling protocol chosen must also work with an application layer protocol called the Session Description Protocol (SDP), which is used in the case of WebRTC. All multimedia-specific metadata is passed using the SDP Protocol.
Any peer (i.e., WebRTC-leveraging application) that is attempting to communicate with another peer generates a set of Interactive Connectivity Establishment protocol (ICE) candidates. The candidates represent a given combination of IP address, port, and transport protocol to be used. Note that a single computer may have multiple network interfaces (wireless, wired, etc.), so can be assigned multiple IP addresses, one for each interface.
Here is a diagram from MDN depicting this exchange.
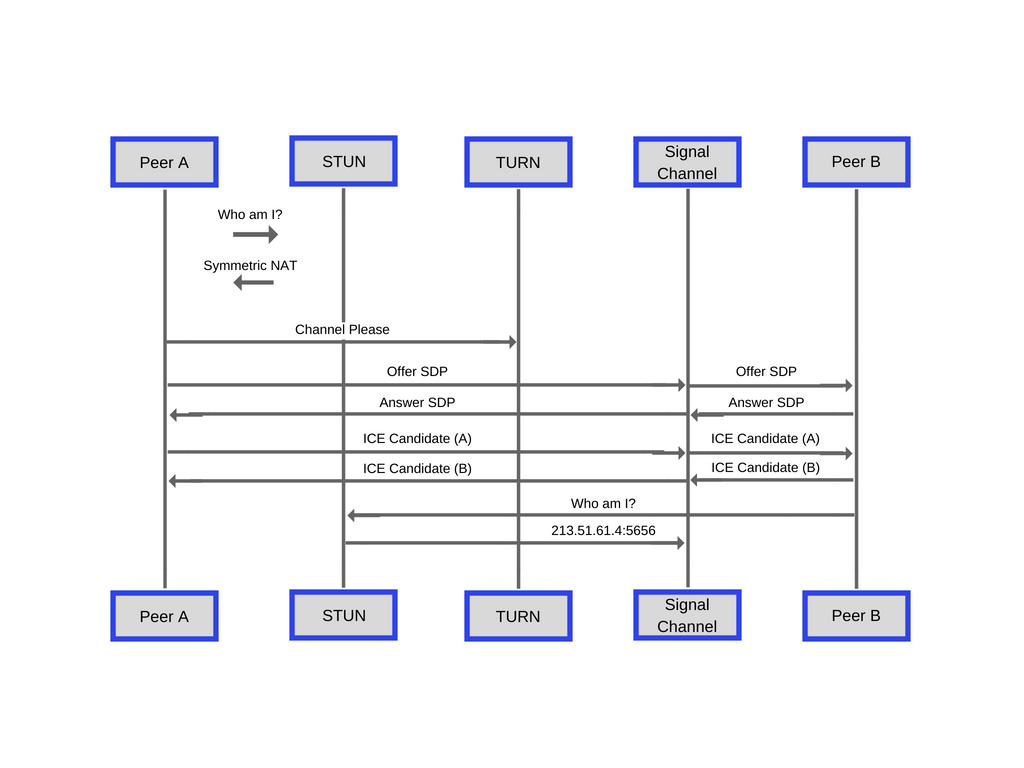
Connection Establishment
Each peer first establishes it’s public-facing IP address as described. Signaling data “channels” are then dynamically created to detect peers and support peer-to-peer negotiations and session establishment.
These “channels” are not known or accessible to the outside world, and require a unique identifier to access them.
Note that due to the flexibility of WebRTC, and the fact that the signaling process is not specified by the standard, the concept and utilization of “channels” may be slightly different given the technologies used. In fact, some protocols do not require a “channel” mechanism to communicate.
We will assume that “channels” are used in the implementation for the purposes of this post.
Once two or more peers are connected to the same “channel”, the peers are able to communicate and negotiate session information. This process is somewhat similar to the publish/subscribe pattern. Basically, the initiating peer sends an “offer” using a signaling protocol, such as Session Initiation Protocol (SIP) and SDP. The initiator waits to receive an “answer” from any receivers that are connected to the given “channel”.
Once the answer is received, a process occurs to determine and negotiate the best of the Interactive Connectivity Establishment protocol (ICE) candidates gathered by each peer. Once the optimal ICE candidates are chosen, essentially all of the required metadata, network routing (IP address and port), and media information used to communicate for each peer is agreed upon. The network socket session between the peers is then fully established and active. Next, local data streams and data channel endpoints are created by each peer, and multimedia data is finally transmitted both ways using whatever bidirectional communication technology is employed.
If the process of agreeing on the best ICE candidate fails, which does happen sometimes due to firewalls and NAT technologies in use, the fallback is to use a TURN server as a relay instead. This process basically employs a server that acts as an intermediary, and which relays any transmitted data between peers. Note that this is not a true peer-to-peer communication, in which peers transmit data bidirectionally, directly to one another.
When using the TURN fallback for communications, each peer no longer needs to know how to contact and transmit data to each other. Instead, they need to know what public TURN server to send and receive real-time multimedia data during a communication session.
It’s important to understand that this is definitely a fail safe and last resort only. TURN servers need to be quite robust, have extensive bandwidth and processing capabilities, and handle potentially large amounts of data. The use of a TURN server therefore obviously incurs additional cost and complexity.
WebRTC APIs
There are three main categories of APIs that exist in WebRTC:
- Media Capture and Streams — Allows you to Get access to input devices such as the microphone and the web camera. The API allows you to get a stream of media from either of them.
- RTCPeerConnection — using these APIs you can send the captured stream of audio and video in real-time across the internet to another WebRTC endpoint. Using these APIs you can create a connection between the local machine and a remote peer. It provides methods to connect to a remote peer, maintain and monitor the connection, and close the connection once it’s no longer needed.
- RTCDataChannel — these APIs allow you to transmit arbitrary data. Each data channel is associated with an RTCPeerConnection.
We’re going to discuss each of these three categories separately.
Media Capture and Streams
The Media Capture and Streams API, often called the Media Stream API or the Stream API, is an API which supports streams of audio or video data, the methods for working with them, the constraints associated with the type of data, the success and error callbacks when using the data asynchronously, and the events that are fired during the process.
The MediaDevices getUserMedia() method prompts the user for permission to use a media input which produces a MediaStream with tracks containing the requested types of media. That stream can include, for example, a video track (produced by either a hardware or virtual video source such as a camera, video recording device, screen sharing service, etc.), an audio track (similarly, produced by a physical or virtual audio source like a microphone, A/D converter, etc.), and possibly other track types.
It returns a Promise that resolves to a MediaStream object. If the user denies permission, or matching media is not available, then the promise is rejected with PermissionDeniedError or NotFoundError respectively.
The MediaDevice singleton can be accessed through the navigator object like this:
navigator.mediaDevices.getUserMedia(constraints)
.then(function(stream) {
/* use the stream */
})
.catch(function(err) {
/* handle the error */
});
Note that you have to pass a constraints object which tells the API what type of stream to return. You can configure all sorts of stuff, including which camera you want to use (front or back), frame rate, resolution and so on.
Since version 25, Chromium-based browsers have allowed audio data from getUserMedia() to be passed to an audio or video element (but note that by default the media element will be muted).
getUserMedia can also be used as an input node for the Web Audio API:
function gotStream(stream) {
window.AudioContext = window.AudioContext || window.webkitAudioContext;
var audioContext = new AudioContext();
// Create an AudioNode from the stream
var mediaStreamSource = audioContext.createMediaStreamSource(stream);
// Connect it to destination to hear yourself
// or any other node for processing!
mediaStreamSource.connect(audioContext.destination);
}
navigator.getUserMedia({audio:true}, gotStream);
Privacy Constraints
As an API that may involve significant privacy concerns, getUserMedia() is held by the specification to very specific requirements for user notification and permission management. getUserMedia() must always get user permission before opening any media gathering input such as a webcam or microphone. Browsers may offer a once-per-domain permission feature, but they must ask at least the first time, and the user must specifically grant ongoing permission if they choose to do so.
Of equal importance are the rules around notification. Browsers are required to display an indicator that shows that a camera or microphone is in use, above and beyond any hardware indicator that may exist. They must also show an indicator that permission has been granted to use a device for input, even if the device is not actively recording at the moment.
RTCPeerConnection
The RTCPeerConnection interface represents a WebRTC connection between the local computer and a remote peer. It provides methods to connect to a remote peer, maintain and monitor the connection, and close the connection once it’s no longer needed.
Below is a WebRTC architecture diagram showing the role of RTCPeerConnection:
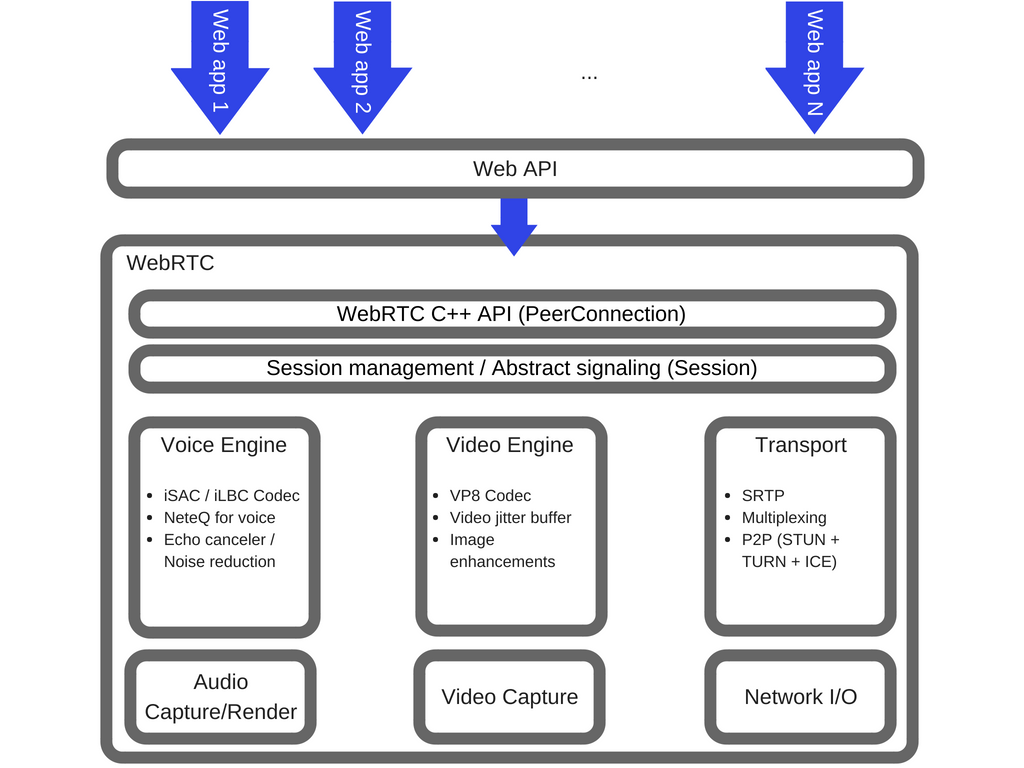
From a JavaScript perspective, the main thing to understand from this diagram is that RTCPeerConnection gives web developers an abstraction from the complexities from the complex internals beneath. The codecs and protocols used by WebRTC do a huge amount of work to make real-time communication possible, even over unreliable networks:
- Packet loss concealment
- Echo cancellation
- Bandwidth adaptivity
- Dynamic jitter buffering
- Automatic gain control
- Noise reduction and suppression
- Image “cleaning”
RTCDataChannel
As well as audio and video, WebRTC supports real-time communication for other types of data.
The RTCDataChannel API enables peer-to-peer exchange of arbitrary data.
There are many use cases for the API, including:
- Gaming
- Real-time text chat
- File transfer
- Decentralized networks
The API has several features to make the most of RTCPeerConnection and enable powerful and flexible peer-to-peer communication:
- Leveraging of
RTCPeerConnectionsession setup. - Multiple simultaneous channels, with prioritization.
- Reliable and unreliable delivery semantics.
- Built-in security (DTLS) and congestion control.
The syntax is similar to the already known WebSocket, with a send() method and a message event:
var peerConnection = new webkitRTCPeerConnection(servers,
{optional: [{RtpDataChannels: true}]}
);
peerConnection.ondatachannel = function(event) {
receiveChannel = event.channel;
receiveChannel.onmessage = function(event){
document.querySelector("#receiver").innerHTML = event.data;
};
};
sendChannel = peerConnection.createDataChannel("sendDataChannel", {reliable: false});
document.querySelector("button#send").onclick = function (){
var data = document.querySelector("textarea#send").value;
sendChannel.send(data);
};
Communication occurs directly between browsers, so RTCDataChannel can be much faster than WebSocket even if a relay (TURN) server is required.
WebRTC in the real world
In the real world, WebRTC needs servers, however simple, so the following can happen:
- Users discover each other and exchange details such as names.
- WebRTC client applications (peers) exchange network information.
- Peers exchange data about media such as video format and resolution.
- WebRTC client applications traverse NAT gateways and firewalls.
In other words, WebRTC needs four types of server-side functionality:
- User discovery and communication
- Signaling
- NAT/firewall traversal
- Relay servers in case peer-to-peer communication fails
The STUN protocol and its extension TURN are used by the ICE to enable RTCPeerConnection to cope with NAT traversal and other network vagaries.
As mentioned earlier, ICE is a protocol for connecting peers, such as two video chat clients. Initially, ICE tries to connect peers directly, with the lowest possible latency, via UDP. In this process, STUN servers have a single task: to enable a peer behind a NAT to find out its public address and port. You can check this list of available STUN servers (Google has a couple of them as well).
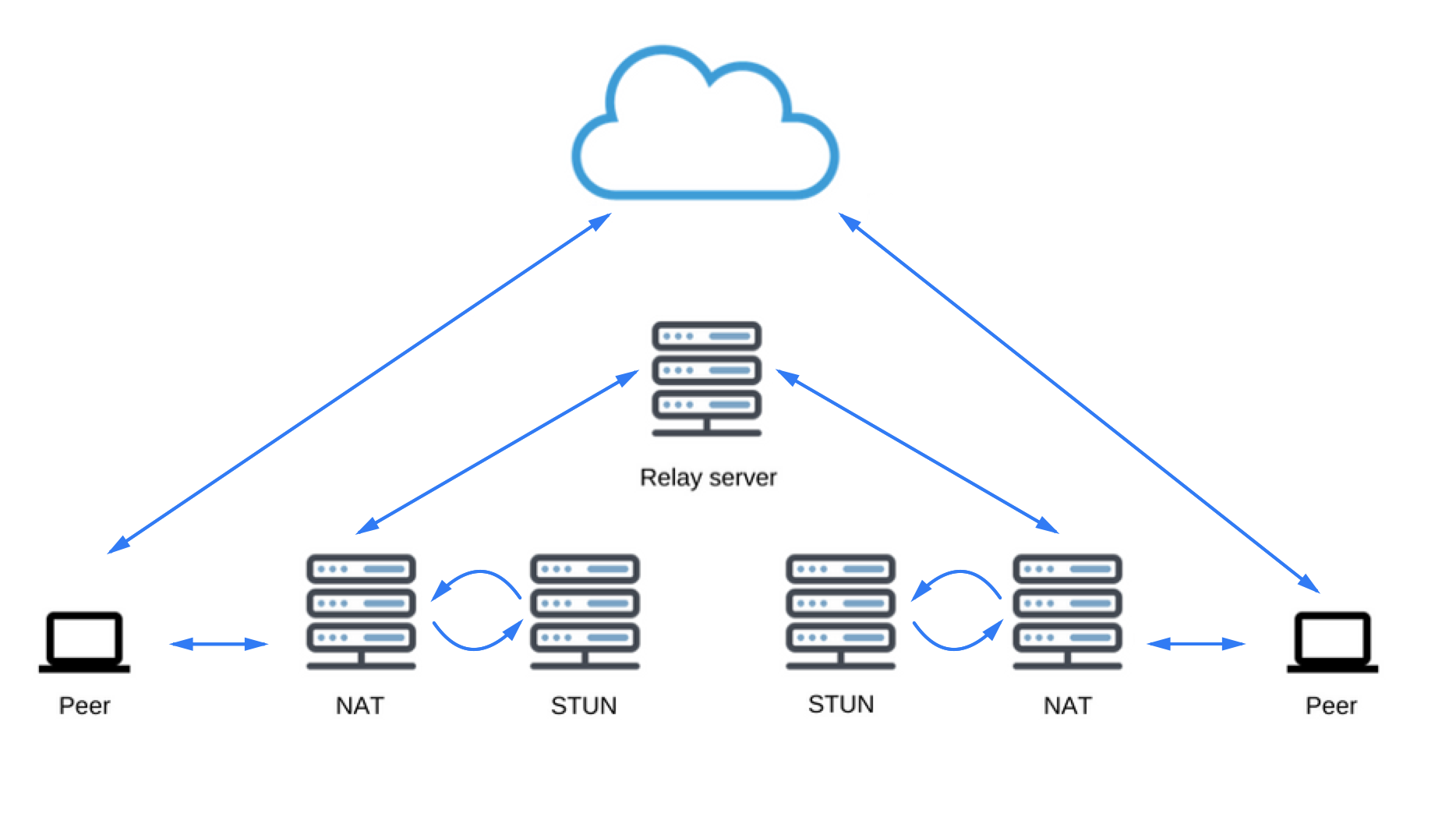
Finding connection candidates
If UDP fails, ICE tries TCP: first HTTP, then HTTPS. If direct connection fails — in particular, because of enterprise NAT traversal and firewalls — ICE uses an intermediary (relay) TURN server. In other words, ICE will first use STUN with UDP to directly connect peers and, if that fails, will fall back to a TURN relay server. The expression ‘finding candidates’ refers to the process of finding network interfaces and ports.
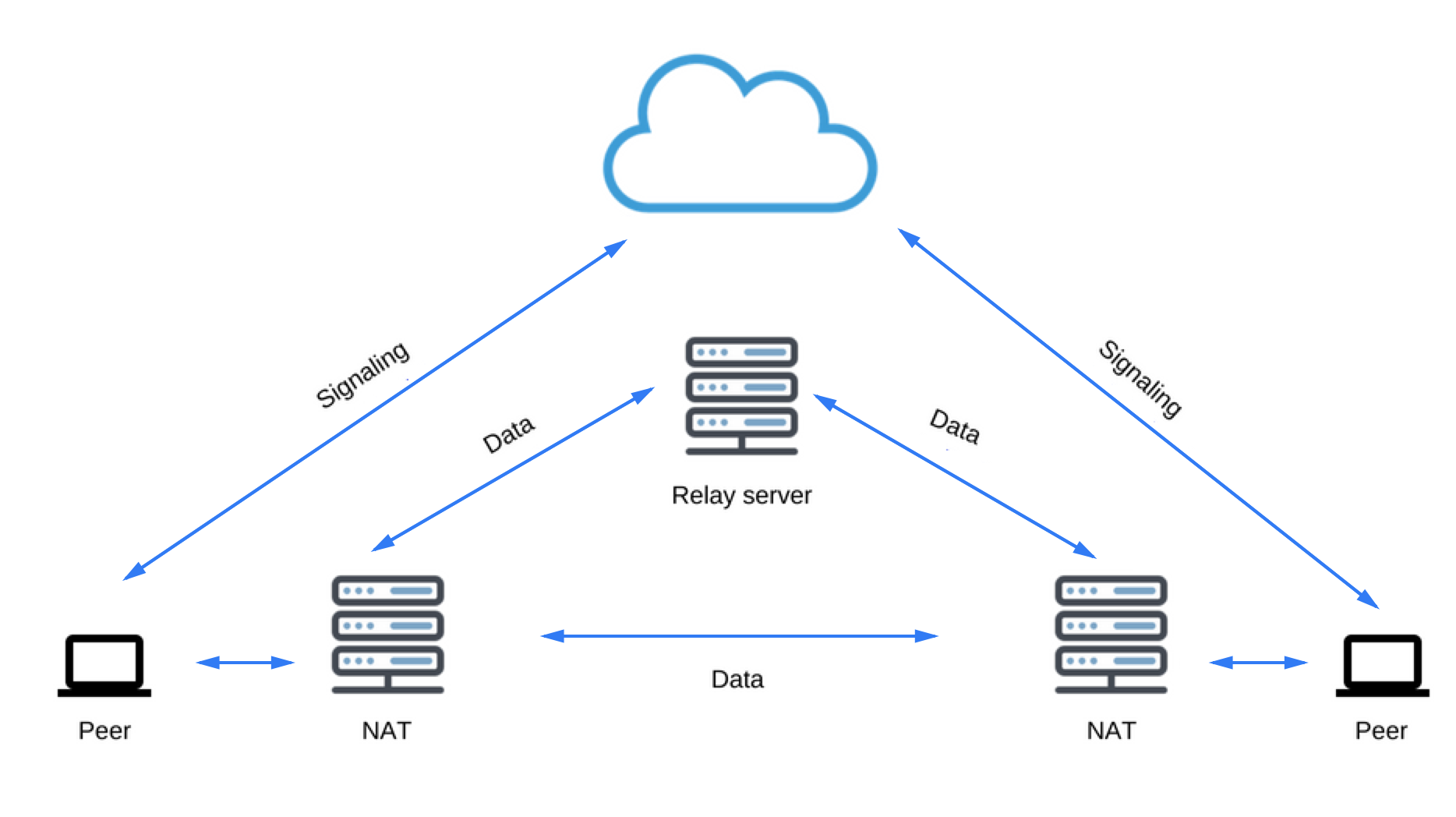
Security
There are several ways a real-time communication application or plugin might compromise security. For example:
- Unencrypted media or data might be intercepted en route between browsers, or between a browser and a server.
- An application might record and distribute video or audio without the user knowing.
- Malware or viruses might be installed alongside an apparently innocuous plugin or application.
WebRTC has several features to avoid these problems:
- WebRTC implementations use secure protocols such as DTLS and SRTP.
- Encryption is mandatory for all WebRTC components, including signaling mechanisms.
- WebRTC is not a plugin: its components run in the browser sandbox and not in a separate process, components do not require separate installation, and are updated whenever the browser is updated.
- Camera and microphone access must be granted explicitly and, when the camera or microphone are running, this is clearly shown by the user interface.
WebRTC is an incredibly interesting and powerful technology for products that are doing some form of real-time streaming between browsers.
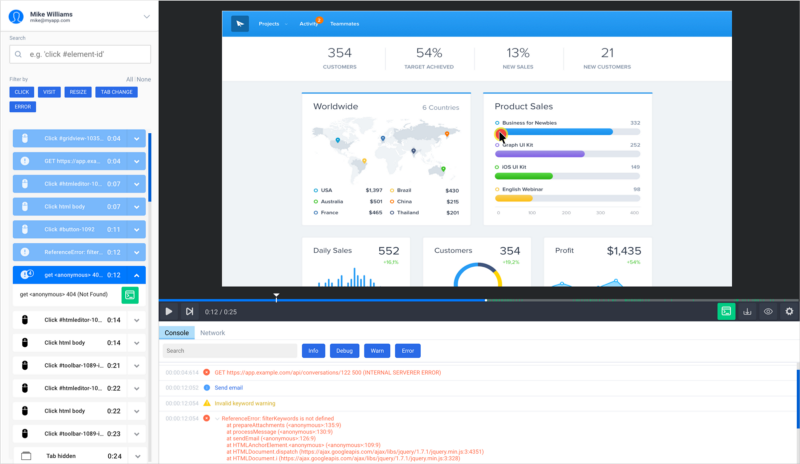
For example, we at SessionStack allow our users to integrate our JavaScript library inside of their web apps. What happens is that our library starts collecting data such as user events, DOM changes, network data, exceptions, debug messages and so on and sending them to our servers.
In the meantime, your users can go into our web app and open a user session and watch it in real-time. Using the collected data, SessionStack is able to recreate everything that is currently happening in the browser of the user, combining the purely visual information with an emulation of the browser console and everything under the hood. Think of it as a remote desktop but not having to make the end users download any software. And on top of the visual information you can actually see the technical information from the session.
And we’re doing all of this having servers but using WebRTC we can actually start doing this directly from browser to browser and reducing latency and the computation power needed from our end.
There is a free plan if you’d like to give SessionStack a try.
Resources: