JavaScript 工作原理 —— 事件循环和异步编程 + 利用 async/await 编码优质代码的5个技巧
潘忠显 / 2021-04-04
“JavaScript 工作原理”系列文章是翻译和整理自 SessionStack 网站的 How JavaScript works。因为博文发表于2017年,部分技术或信息可能已经过时。本文英文原文链接,作者 Alexander Zlatkov,翻译 潘忠显。
欢迎阅读该系列文章的第4部分,本文作为第一篇文章的扩展,将探讨 JavaScript 内部组件。首先,会回顾第一篇文章中,单线程环境中编程的弊端。然后,介绍如何使用事件循环 (event loop) 和异步/等待 (async / await) 来克服这些弊端,构建出色的 JavaScript UI。最后,会介绍如何使用 async/await 编写更简洁的代码的 5 条技巧。
单线程的限制
在第一篇文章中,我们思考了以下问题:当调用堆栈中的函数,需要大量时间运行时,会发生什么情况。例如,假设浏览器中正在运行一种复杂的图像转换算法。
当调用堆栈中有函数要执行,浏览器无法执行其他任何操作(被阻塞了)。这意味着浏览器无法渲染,也无法运行任何其他代码,只是卡住了。这样一来,您的应用程序 UI 不再高效且令人愉悦。
您的应用卡住了。
在某些情况下,这可能不是一个严重的问题。但是,还有一个更大的问题:一旦浏览器开始处理“调用堆栈”中的繁重任务,它可能会长时间停止响应。那时,许多浏览器会通过引发错误来询问是否应该终止该页面(这很难看,也完全破坏了用户体验):
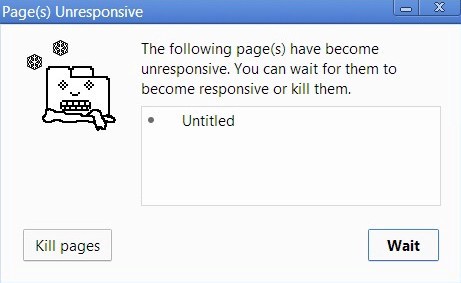
组成 JavaScript 程序的块 (block)
您可能会在单个 .js 文件中编写 JavaScript 应用程序,但是几乎可以确定是,您的程序由几个块 (block) 组成的,其中只有一个块要现在执行,其余以后执行。最常见的块单位是函数 (function)。
大多数 JavaScript 新手似乎遇到的问题是,要理解以后不一定严格地、立即地在现在之后发生。换句话说,根据定义,无法立即完成的任务将异步完成,这跟之前期望的阻塞行为是不一致的。
让我们看一下以下示例:
// ajax(..) is some arbitrary Ajax function given by a library
var response = ajax('https://example.com/api');
console.log(response);
// `response` won't have the response
您可能已经知道标准 Ajax 请求不会同步完成,这意味着在执行代码 ajax(...) 时,函数还没有返回任何值来分配给 response 变量。
使用“回调”函数是一种简单的等待异步函数返回的方式:
ajax('https://example.com/api', function(response) {
console.log(response); // `response` is now available
});
请注意:实际上可以发出同步的 Ajax 请求,这是一个可怕的做法,永远不要那样做。如果您发出同步 Ajax 请求,则 JavaScript 应用的用户界面将被阻塞:用户将无法单击、输入数据、导航或滚动,这将阻止任何用户交互。
虽然不要这样做,但这里仍给出同步代码的示例:
// This is assuming that you're using jQuery
jQuery.ajax({
url: 'https://api.example.com/endpoint',
success: function(response) {
// This is your callback.
},
async: false // And this is a terrible idea
});
我们以 Ajax 请求为例。可以通过 setTimeout(callback, milliseconds) 函数来完成,可以让任何代码块异步执行。setTimeout 函数的作用是设置一个超时事件。让我们来看看:
function first() {
console.log('first');
}
function second() {
console.log('second');
}
function third() {
console.log('third');
}
first();
setTimeout(second, 1000); // Invoke `second` after 1000ms
third();
控制台的输出:
first
third
second
事件循环
尽管允许异步 JavaScript 代码(如上边的 setTimeout),实际上 ES6之前的 JavaScript 本身没有内建的异步概念。除了在任何给定的时刻执行程序的单个块之外,JavaScript 引擎从未做过其他任何事情。
有关 JavaScript 引擎工作原理的详细信息(特别是Google的V8),请查看我们之前关于引擎的文章。
那么,谁去告诉 JS 引擎执行我们程序的代码块呢?实际上,JS引擎不是孤立运行的,而是在托管 (hosting) 环境中运行。对于大多数开发人员而言,典型托管环境是 Web 浏览器或 Node.js。如今,JavaScript 已嵌入从机器人到灯泡的各种设备中。每个单独的设备代表 JS 引擎的不同类型的托管环境。
所有环境的共同点,都有一种被称为事件循环的内建机制。该机制每次调用 JS 引擎时,都会处理程序中多个块的执行。
这意味着 JS 引擎只是按需执行任意 JS 代码的环境,是周围环境在调度事件(JS 代码块的执行)。
当您的 JavaScript 程序发出 Ajax 请求、以从服务器获取某些数据时,您在函数中设置了“响应”代码(“回调”),然后 JS 引擎告知托管环境:“嘿,我现在暂时暂停执行,但是只要您完成该网络请求,并且有一些数据,请回调此函数。”
然后,将浏览器设置侦听来自网络的响应,并且当有需要返回的内容时,它将通过将其插入到事件循环 (event loop) 中来调度要执行的回调函数。
让我们看下图:
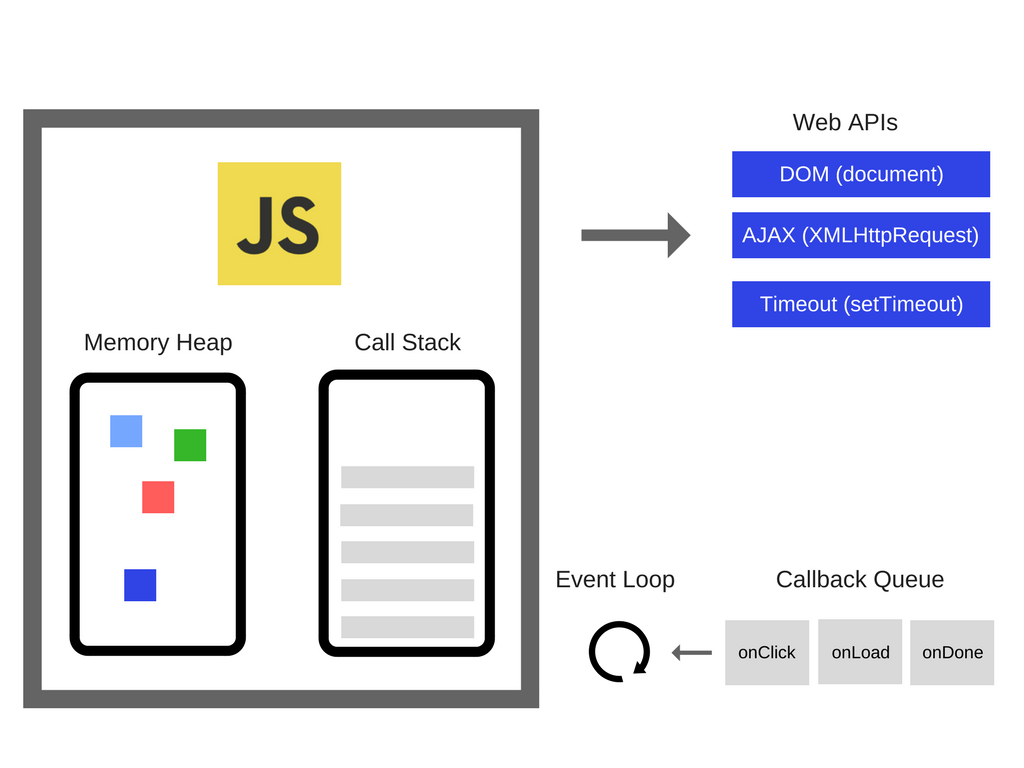
您可以在我们的之前的文章中,找到有关内存堆和调用堆栈的更多信息。
这些 Web API 是什么?本质上,它们是并发浏览器中您无法访问的线程,您只能对其进行调用。如果您是 Node.js 开发人员,则它们是 C ++ API。
事件循环到底是什么
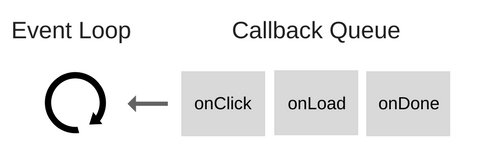
事件循环有一项简单的工作:监视调用栈和回调队列。如果调用栈为空,则事件循环将从回调队列中获取第一个事件,并将其压入调用栈,从而有效地运行该事件。
这样的迭代过程,在事件循环中称为“滴答 (tick)”,每个事件只是一个函数回调。
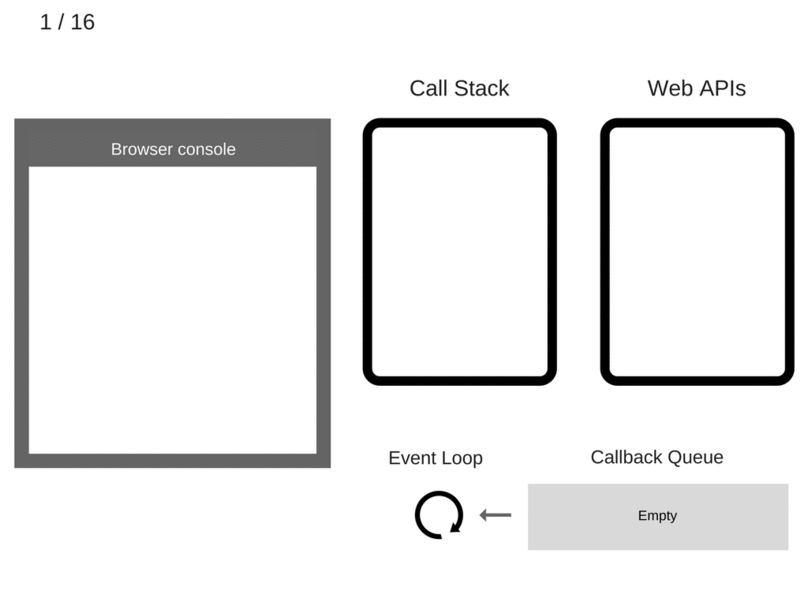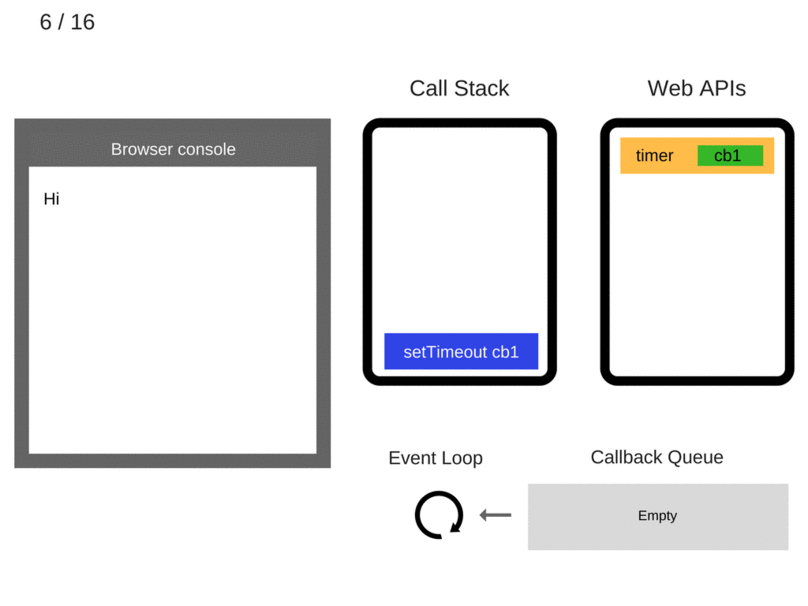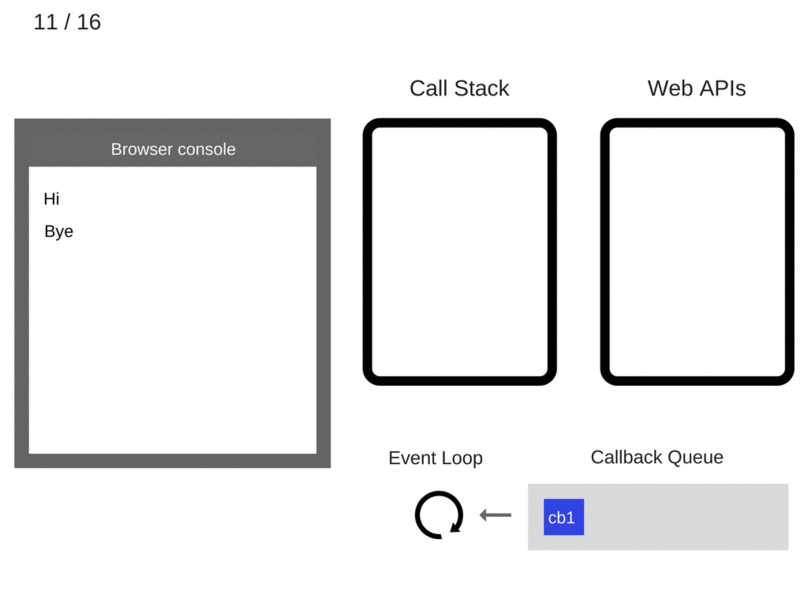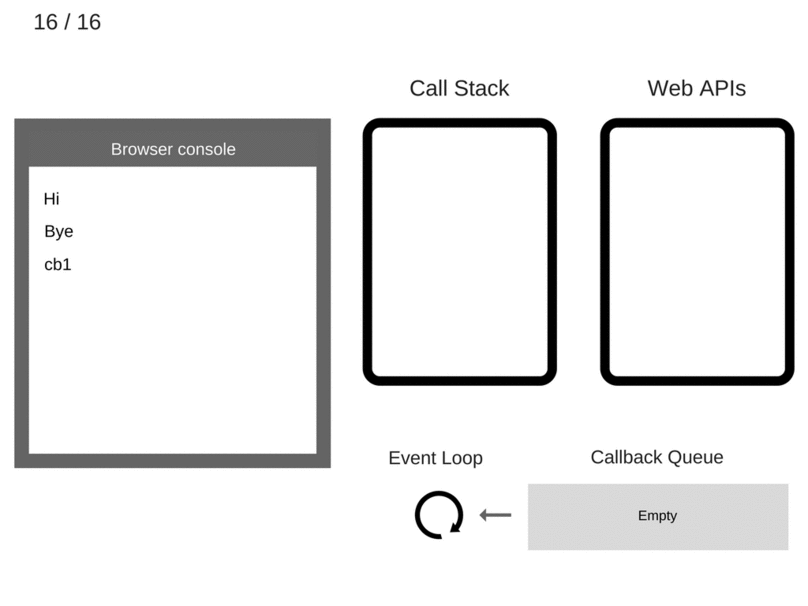
console.log('Hi');
setTimeout(function cb1() {
console.log('cb1');
}, 5000);
console.log('Bye');
我们来“执行”这段代码,看具体发生了什么:
- 所有状态是清空的:浏览器 console 清空,调用栈也是空的。
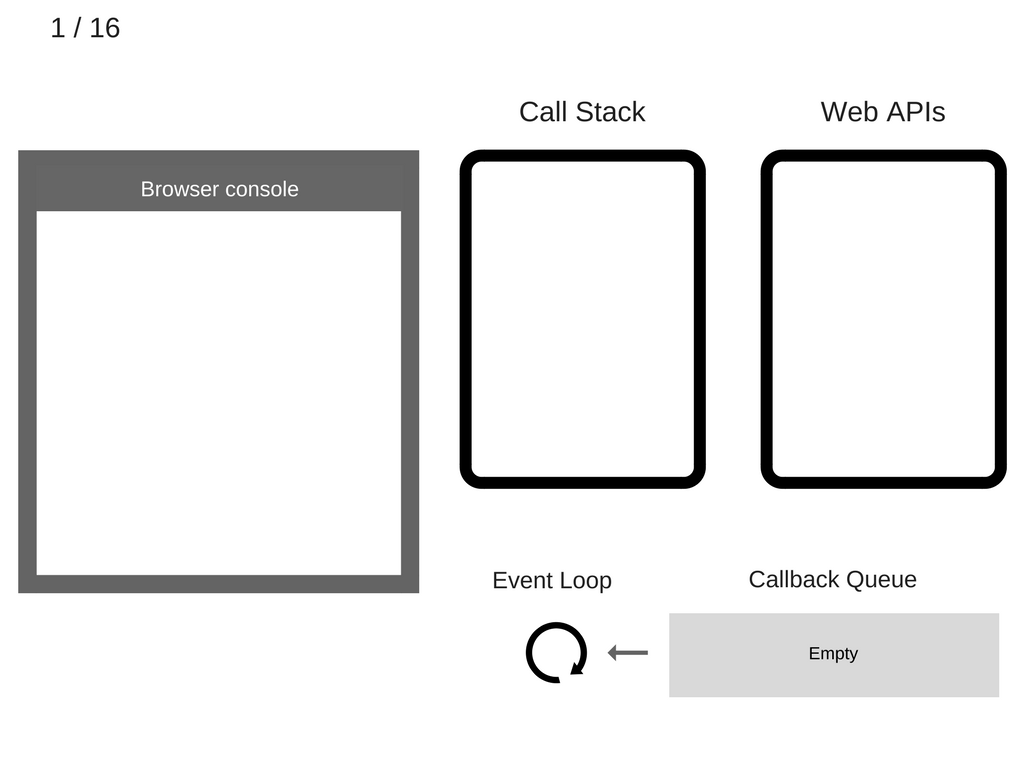
console.log('Hi')被添加到调用栈。
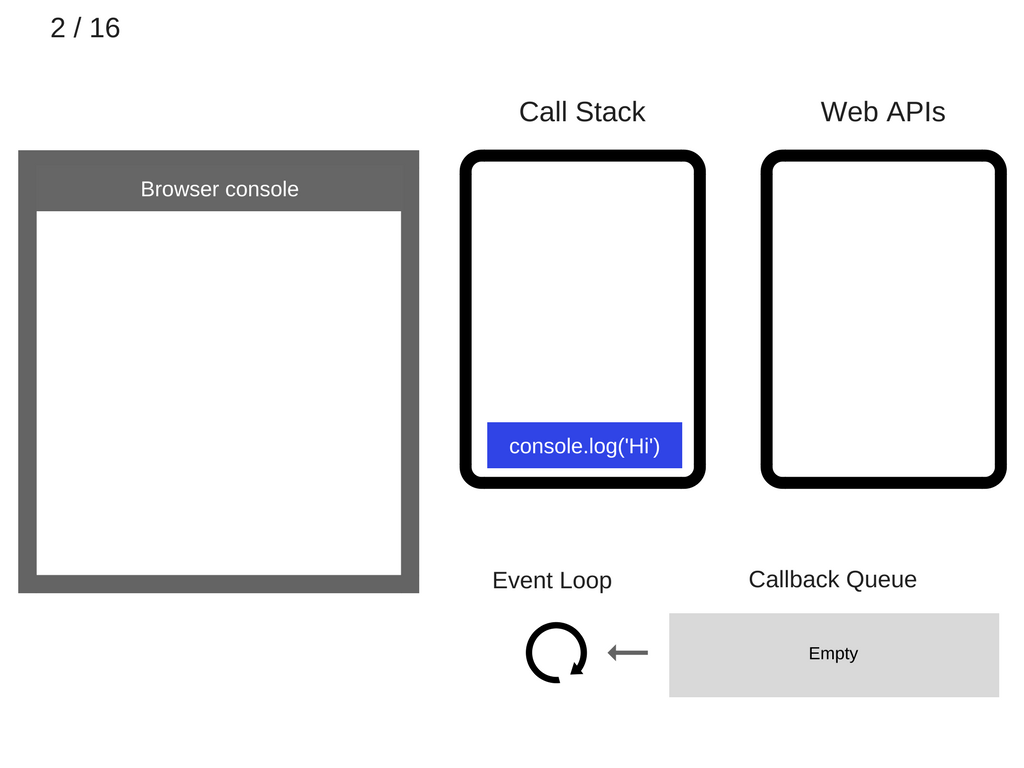
console.log('Hi')被执行。
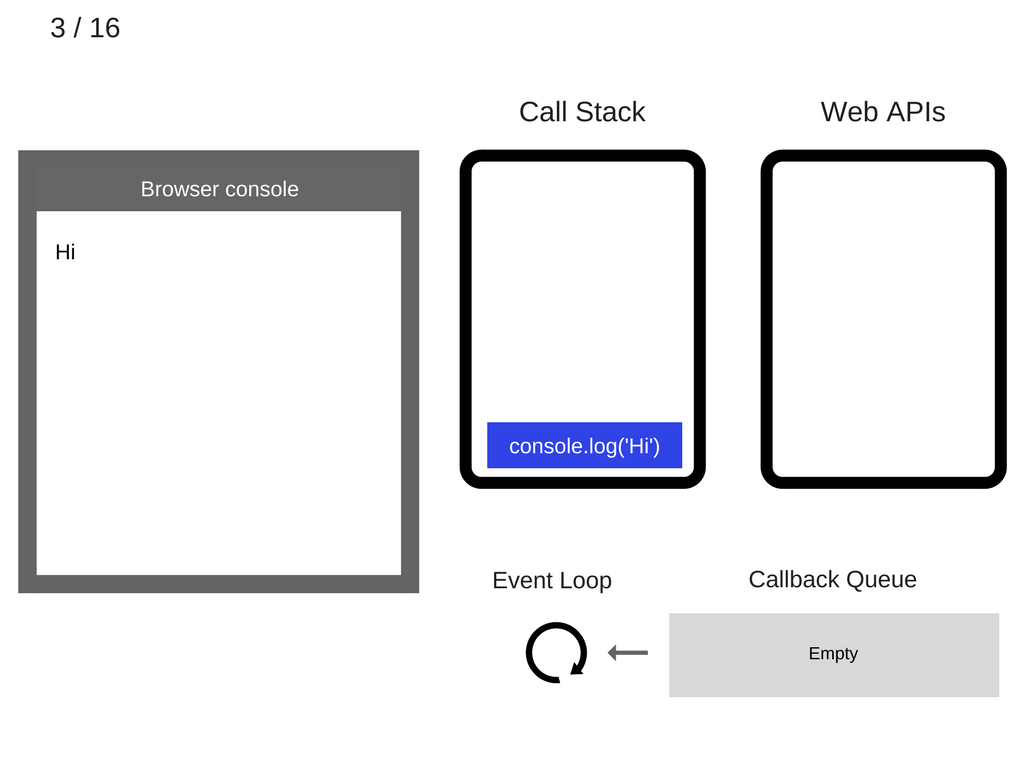
console.log('Hi')被从调用栈中移除。

setTimeout(function cb1() { ... })被添加到调用栈。
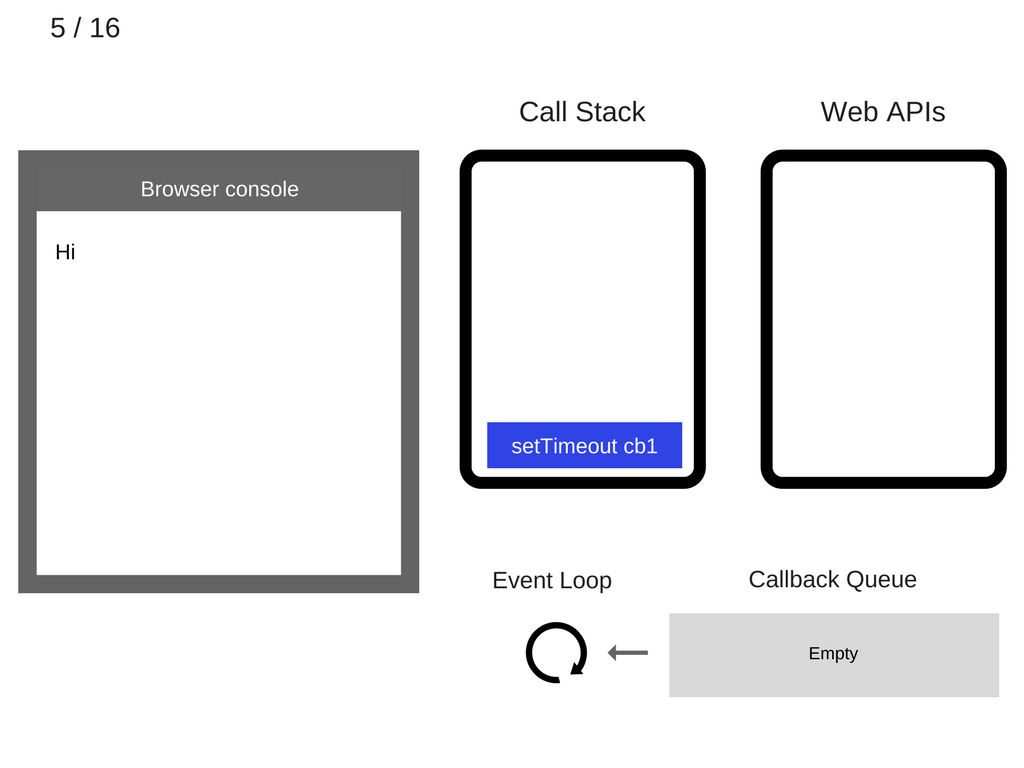
setTimeout(function cb1() { ... })被执行。浏览器创建了一个定时器 (Web API),处理倒计时。

setTimeout(function cb1() { ... })函数自身完成,被从调用栈中移除。
console.log('Bye')被加入到调用栈。
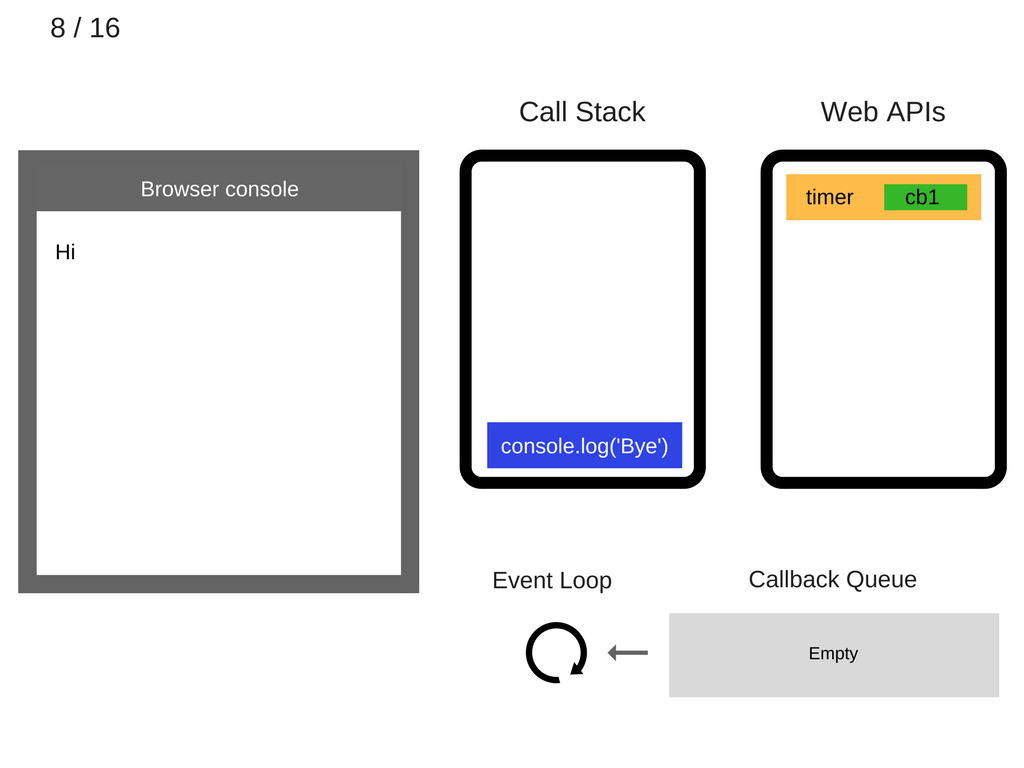
console.log('Bye')被执行。
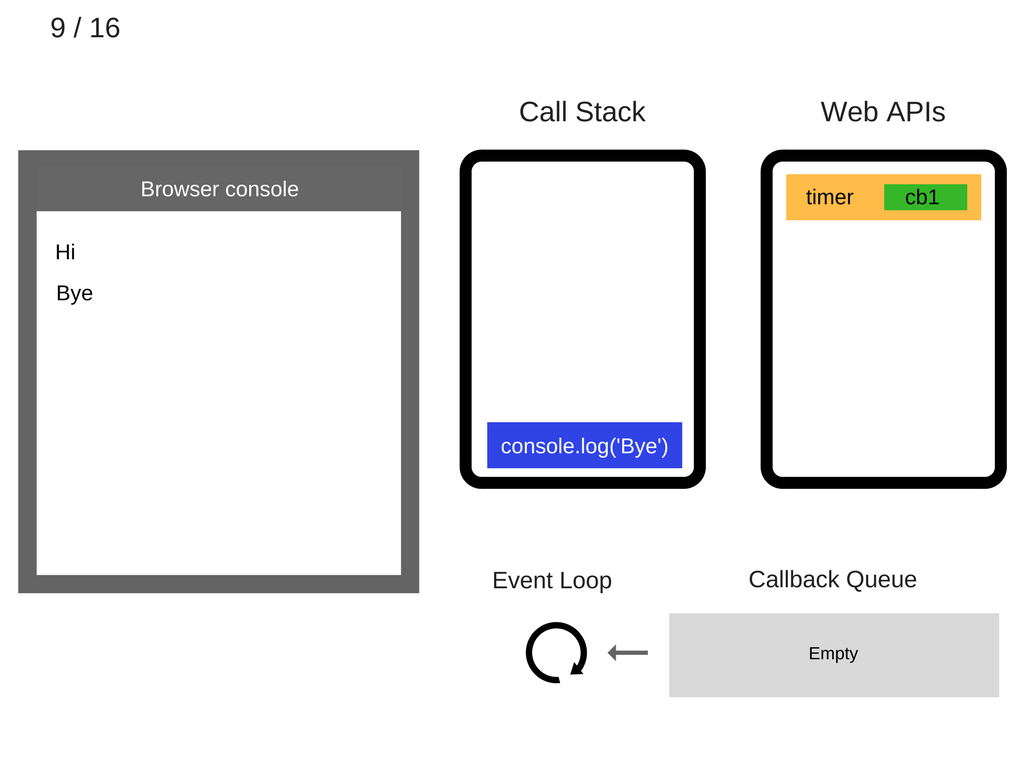
console.log('Bye')被移出调用栈。
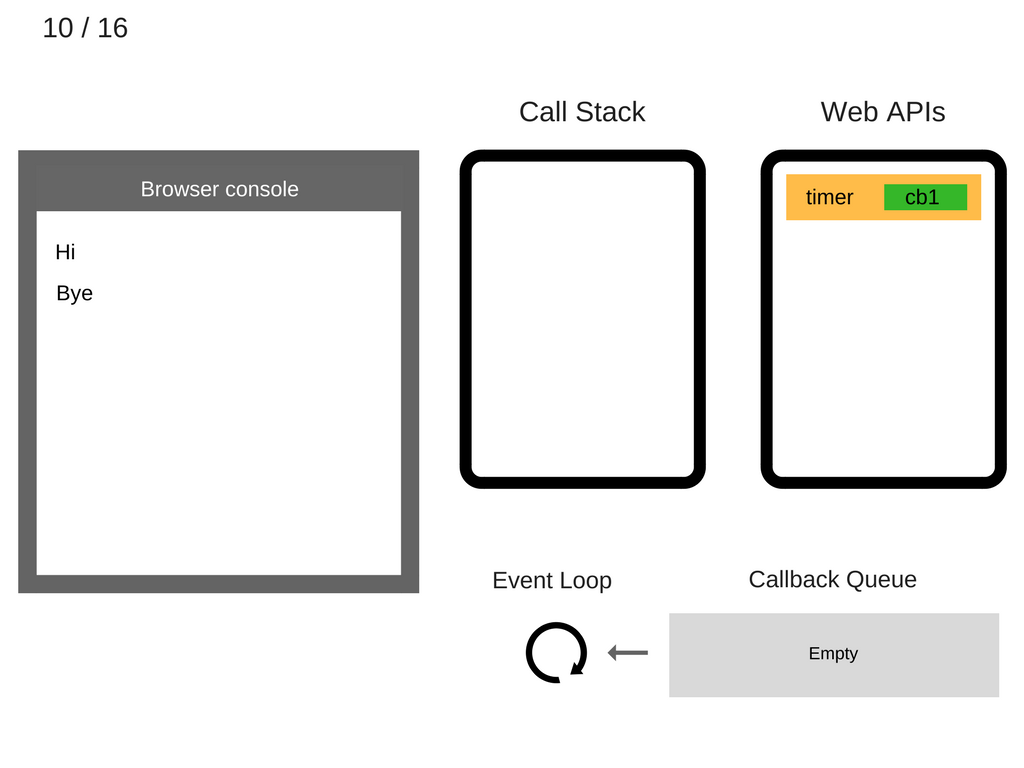
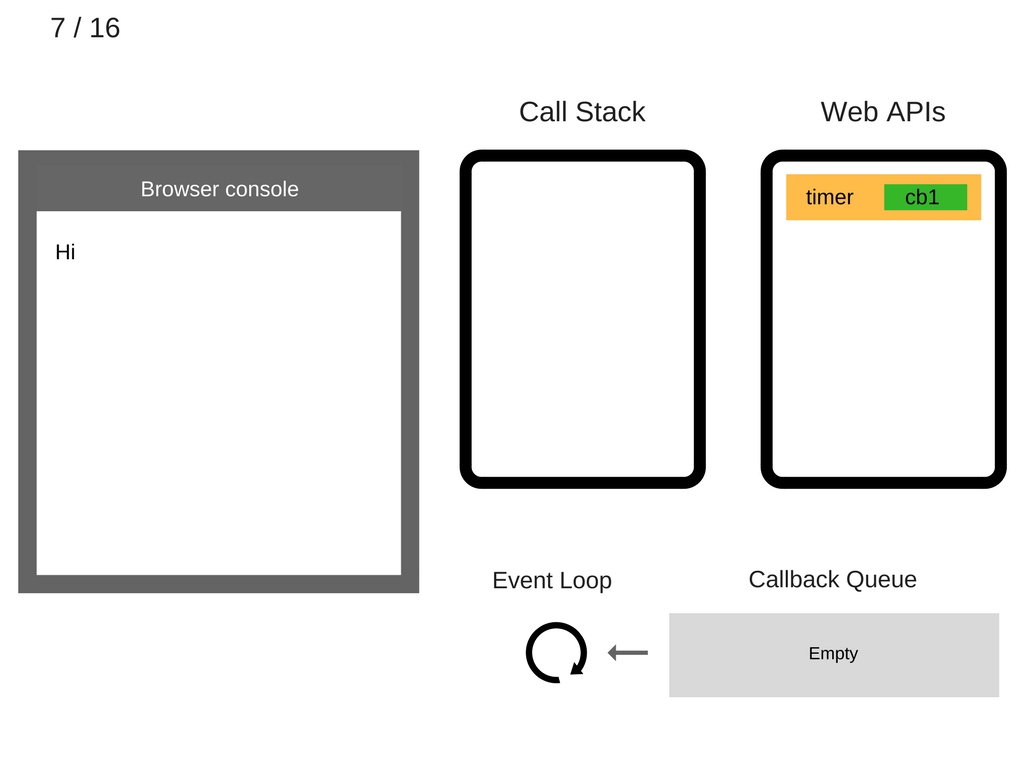
- 5000ms 之后,定时器结束,并将
cb1回调 push 进回调队列。
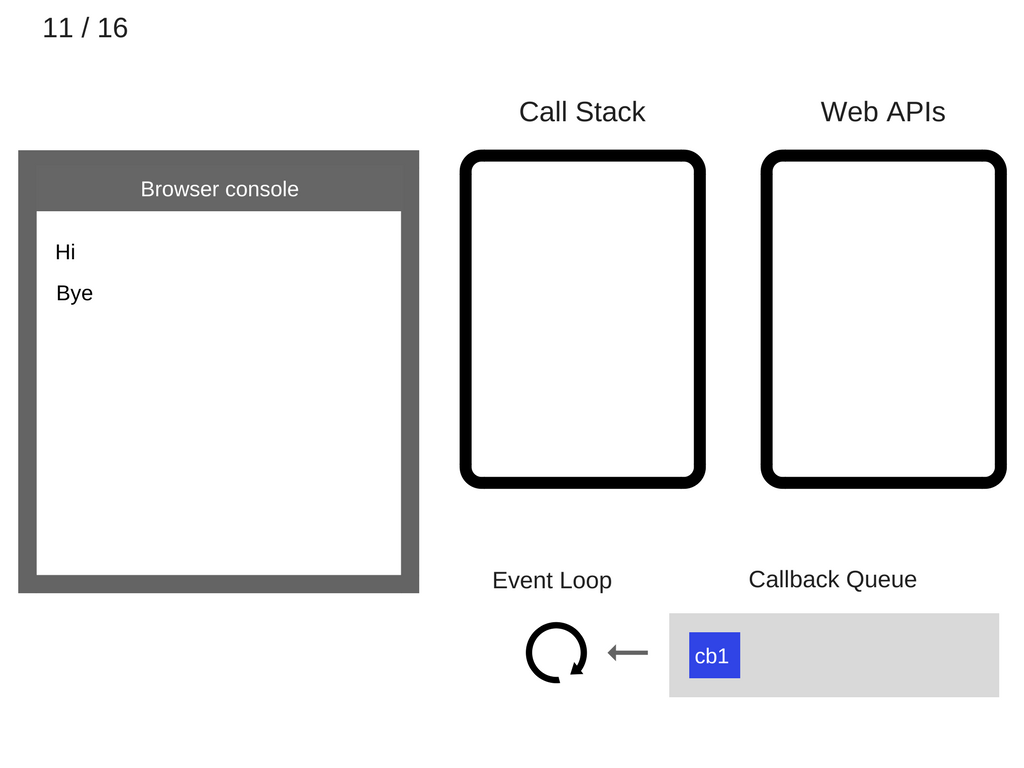
- 事件循环 (Event Loop) 从回调队列中将
cb1取出,并压入调用栈。
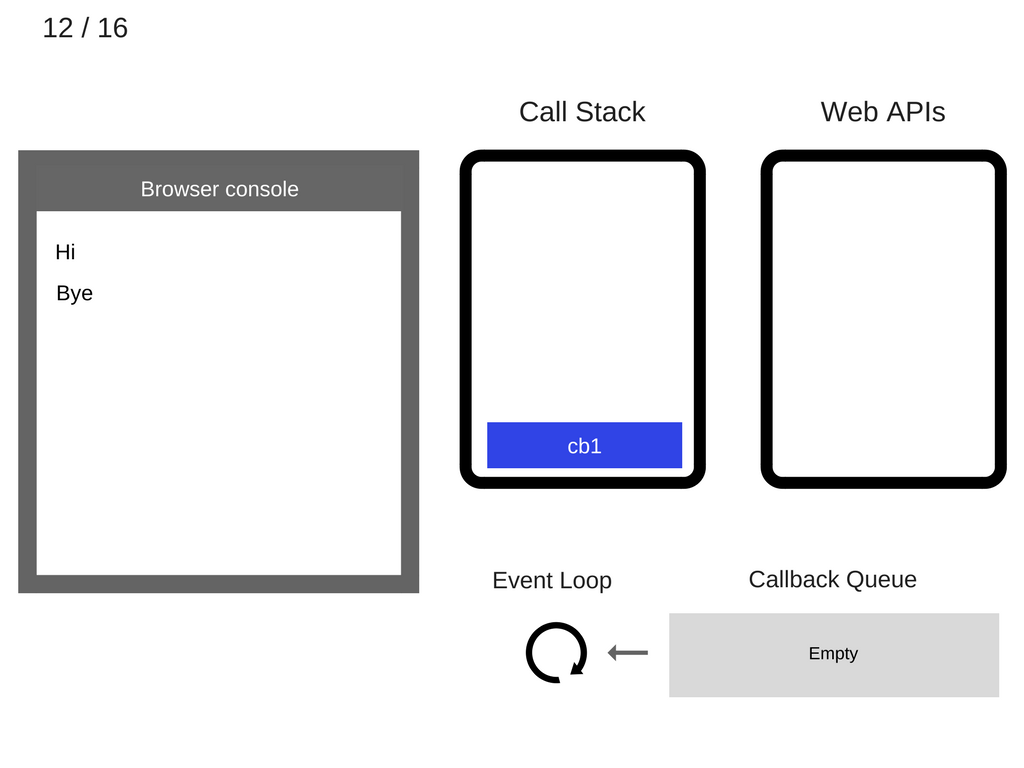
cb1被执行,并将console.log('cb1')压入调用栈。
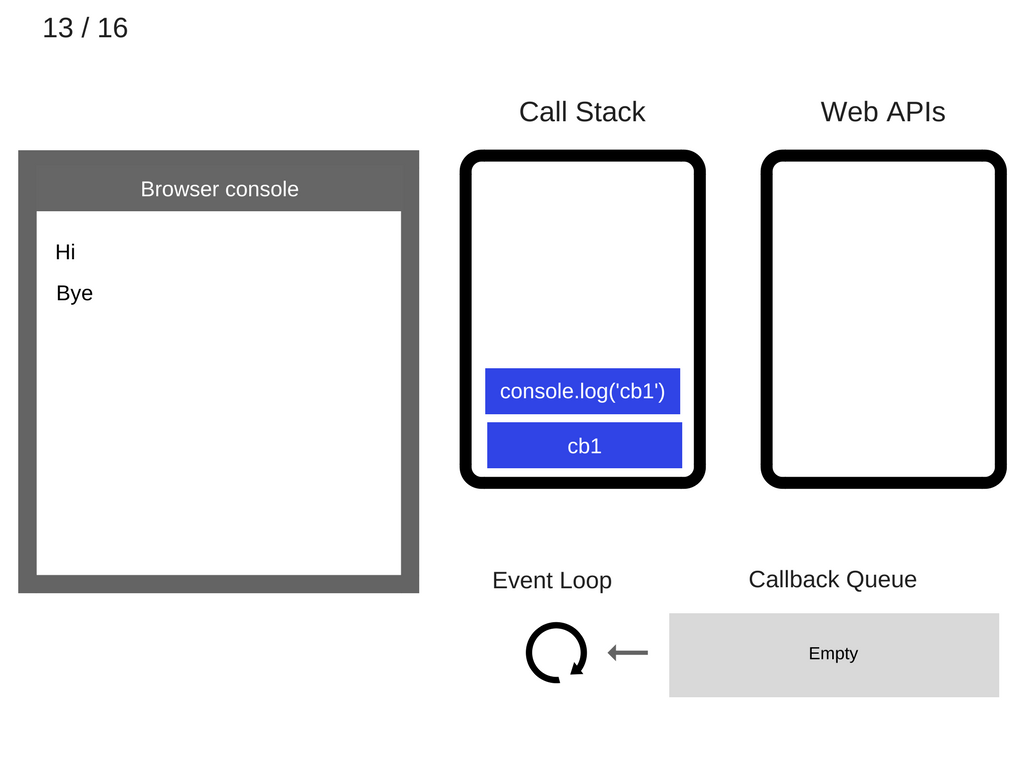
console.log('cb1')被执行。
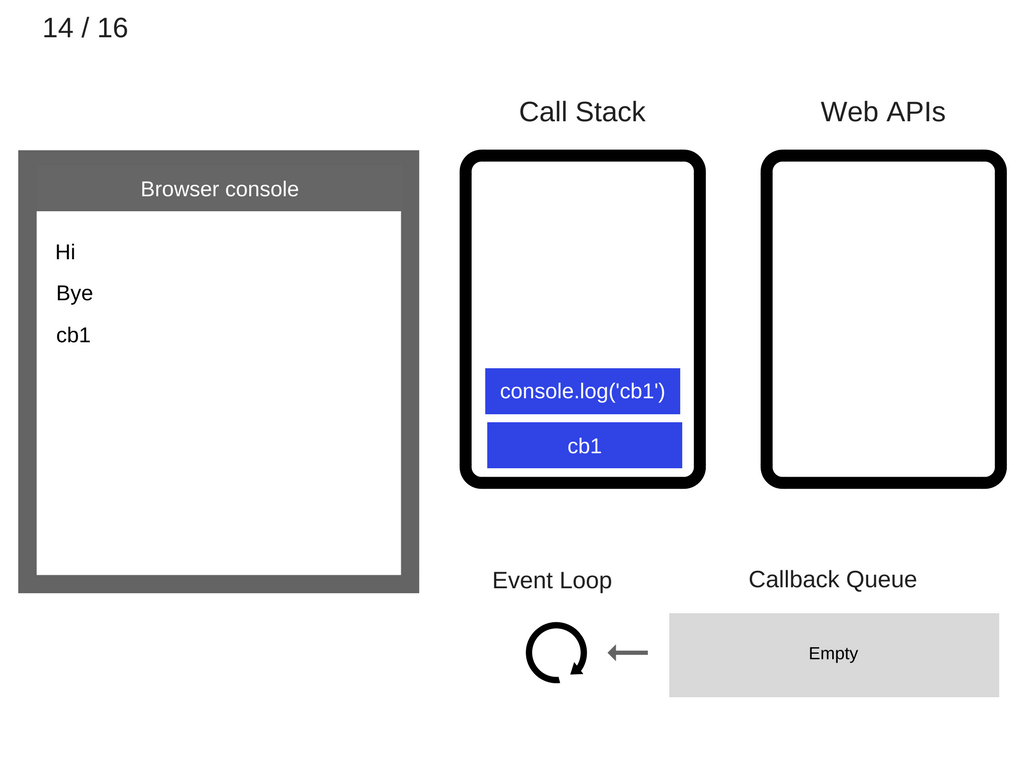
console.log('cb1')被移出调用栈。
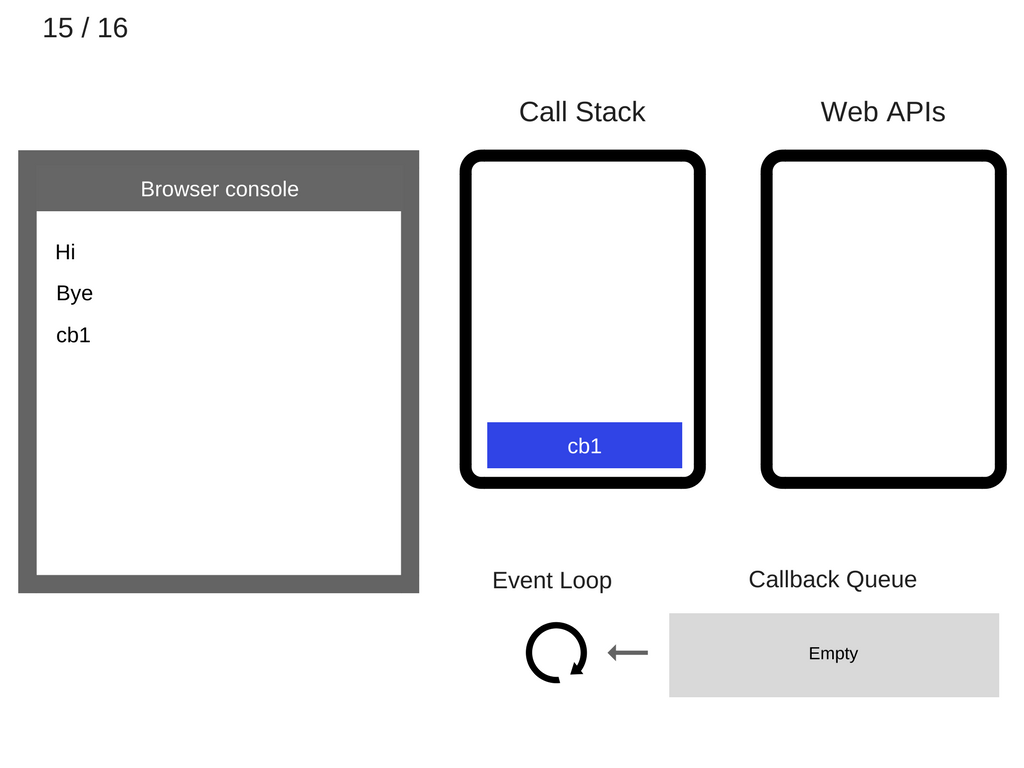
cb1被移出调用栈。

快速回顾:
ES6 指定了事件循环的工作方式,这意味着在技术上, JS 引擎将事件循环囊括在其责范围之内,而不仅仅充当托管环境的角色。进行此更改的主要原因之一是:在 ES6 中引入的 Promises 需要获得对事件循环队列上的调度操作,进行直接的、细粒度的控制(我们将在后面详细讨论)。
setTimeout(...) 的工作方式
请注意很重要的一点:setTimeout(...) 不会自动将您的回调置于事件循环队列中。它设置了一个计时器,当计时器到期时,环境会将您的回调放入事件循环中,以便将来的某个 tick 将其选中并执行。看一下这段代码:
setTimeout(myCallback, 1000);
这并不意味着 myCallback 将在1000毫秒后执行,而是 myCallback 将在1000毫秒后添加到事件循环队列中。但是,队列中可能还包含其他较早添加的事件,myCallback 将不得不等待。
有很多关于 JavaScript 异步代码入门的文章和教程,它们会提到使用 setTimeout(callback, 0)。现在您已经知道了事件循环的功能以及setTimeout的工作方式:将 setTimeout 的第二个参数设为0,其调用会推迟回调函数的执行,直到调用堆栈清空。(译者注:所以相当于 Go 中的 defer 功能?)
看下面的代码:
console.log('Hi');
setTimeout(function() {
console.log('callback');
}, 0);
console.log('Bye');
尽管等待时间设置为 0 毫秒,但在浏览器控制台中的结果如下:
Hi
Bye
callback
ES6 中的作业 (job)
ES6 中引入了一个称为“作业队列”的新概念。它是事件循环队列之上的一层,您最有可能在处理 Promises 的异步行为时碰到它,后续我们也会讨论 Promises。
我们现在只讨论概念,以便稍后讨论 Promises 相关的异步行为时,您能理解这些动作是如何被调度和处理的。
想象一下:工作队列是一个附加到事件循环队列中每个 tick 末尾的队列。
某些发生在一个事件循环滴答时的异步动作,不会引起整个新事件被添加到事件循环队列,而是将一个事项(item,又名作业-job) 添加到当前滴答的作业队列末尾。
这意味着,可以添加需要待会执行的其他函数,并能保证它会在之后立即执行。
作业还可以引起更多的作业被添加到同一队列的末尾。不断添加其他作业的作业被称为“作业循环”,从理论上讲,它可能无限期循环,从而使程序缺少必要资源的,而不能进入下一个事件循环滴答。概念上,这类似于只在代码中长时间运行或无限循环(如 while (true))。
作业有点像 setTimeout(callback, 0) 的技巧,但是其实现方式引入的顺序,更加明确且有保证的:稍后,但要尽快。
回调
到目前为止,回调是 JavaScript 中表达和管理异步性的最常见方法,也是 JavaScript 语言中最基本的异步模式。无数的 JS 程序,甚至是非常复杂的程序,都是在异步回调的基础上编写的。
除了回调之外,许多开发人员正尝试寻找更好的异步模式。但如果不理解回调的本质,就不可能有效地使用任何抽象。
在以后的章节中,我们将深入探讨其中的两个抽象,以说明为什么有必要使用、甚至建议使用更复杂的异步模式。
回调嵌套
看下面的代码:
listen('click', function (e){
setTimeout(function(){
ajax('https://api.example.com/endpoint', function (text){
if (text == "hello") {
doSomething();
}
else if (text == "world") {
doSomethingElse();
}
});
}, 500);
});
我们将三个函数嵌套在一起,每个函数代表一个异步序列中的一个步骤。
这种代码通常称为“回调地狱 (callback hell)”。实际上,“回调地狱”几乎与嵌套或缩进无关,这是一个更深层次的问题。
上述代码首先在等待“点击”事件,然后在等待计时器触发,再然后在等待 Ajax 响应返回,这一过程可能会再次重复出现。
乍一看,此代码似乎自然地将其异步映射到顺序步骤,例如首先:
listen('click', function (e) {
// ..
});
然后:
setTimeout(function(){
// ..
}, 500);
再然后:
ajax('https://api.example.com/endpoint', function (text){
// ..
});
最后:
if (text == "hello") {
doSomething();
}
else if (text == "world") {
doSomethingElse();
}
因此,这种顺序的异步代码表达方式似乎更加自然,不是吗?肯定有这种方法,对吧?
Promises
来看下面的代码:
var x = 1;
var y = 2;
console.log(x + y);
非常简单,将 x 和y 的值相加,然后将结果打印到控制台。但是,如果 x 或 y 的值丢失并且仍待确定怎么办?假设我们需要先从服务器中检索 x 和 y 的值,之后才能在表达式中使用它们。假设我们有一个函数 loadX 和 loadY,它们分别从服务器加载了 x 和 y 的值。然后,假设我们有一个函数 sum,一旦两个值都被加载,它们便将 x 和 y 的值相加。
可能看起来像这样(是不是非常丑陋?):
function sum(getX, getY, callback) {
var x, y;
getX(function(result) {
x = result;
if (y !== undefined) {
callback(x + y);
}
});
getY(function(result) {
y = result;
if (x !== undefined) {
callback(x + y);
}
});
}
// A sync or async function that retrieves the value of `x`
function fetchX() {
// ..
}
// A sync or async function that retrieves the value of `y`
function fetchY() {
// ..
}
sum(fetchX, fetchY, function(result) {
console.log(result);
});
这里有一个非常重要的内容:在该代码段中,我们将 x 和 y 作为未来值,并且我们创建了一个 sum(...)表达操作,从外部看,sum 函数并不关心 x 或 y 是否立即可用。
未来值不用考虑何时可用,当然,这种基于回调的方法很粗略,还有很多不足之处,但有助于我们理解推理未来值的好处。
承诺值 Promise Value
让我们简要地看一下如何用 Promises 来表达 x + y 示例:
function sum(xPromise, yPromise) {
// `Promise.all([ .. ])` takes an array of promises,
// and returns a new promise that waits on them
// all to finish
return Promise.all([xPromise, yPromise])
// when that promise is resolved, let's take the
// received `X` and `Y` values and add them together.
.then(function(values){
// `values` is an array of the messages from the
// previously resolved promises
return values[0] + values[1];
} );
}
// `fetchX()` and `fetchY()` return promises for
// their respective values, which may be ready
// *now* or *later*.
sum(fetchX(), fetchY())
// we get a promise back for the sum of those
// two numbers.
// now we chain-call `then(...)` to wait for the
// resolution of that returned promise.
.then(function(sum){
console.log(sum);
});
此代码段中有两层 承诺 (Promises)。
fetchX() 和 fetchY() 被直接调用,它们(承诺,promise)返回的值被传递给 sum(...)。这些 promise 表示的基础值可能现在或将来会准备好,但是每个 promise 都将其行为规范化为相同的。我们以与时间无关的方式推理 x 和 y 值,它们就是未来值,周期 (period)。
第二层是 sum(...) 通过 Promise.all([ ... ]) 创建承诺并返回,然后我们通过调用 then(...)来等待。当 sum(...) 完成后,我们用来求和的未来值已经就绪,然后我们可以将“和”打印出来。这里隐藏了 sum(...) 中等待 x 和 y 两个未来值的逻辑。
注意:在 sum(...) 中, Promise.all([ ... ]) 调用会创建一个 promise,这个 promise 等待 promiseX 和 promiseY 求解完成。链式调用 .then(...) 会创建另一个 promise,该 promise 将立即求解 values[0] + values[1],作为加法的结果返回。因此,链式地在 sum(...) 调用之后的 then(...) 调用,真正操作的是返回的第二个 promise,而不是由 Promise.all([ ... ]) 创建的第一个 promise。另外,尽管我们没有在第二个 then(...) 之后继续链式调用,它也创建了另外一个 promise,我们可以观察或使用它。该 promise 链条会在本章的后边有详细说明。
使用 Promises,then(...) 调用实际上可以具有两个函数,第一个用于实现(如前所示),第二个用于拒绝:
sum(fetchX(), fetchY())
.then(
// fullfillment handler
function(sum) {
console.log( sum );
},
// rejection handler
function(err) {
console.error( err ); // bummer!
}
);
如果在获取 x 或 y 时出现问题,或者在加法过程中因某种原因失败, sum(...) 返回的承诺将不会被拒绝,而是传递给 then(...) 的第二个回调错误处理函数,将从承诺中获得拒绝值 (rejection value)。
因为 Promise 封装了时间相关的状态(等待潜在值的实现或拒绝),Promise 本身是时间独立的,因此 Promise可以通过可预测的方式组合 (composed / combined),而不考虑时间或结果 (timing or outcome underneath)。
而且,一旦 Promise 状态变成已决议 (resolved),它就变成了一个不可变值 (immutable value),然后会永远保持这种状态,可以根据需要被多次观察。
实际上,链式承诺 (chain promises) 非常有用:
function delay(time) {
return new Promise(function(resolve, reject){
setTimeout(resolve, time);
});
}
delay(1000)
.then(function(){
console.log("after 1000ms");
return delay(2000);
})
.then(function(){
console.log("after another 2000ms");
})
.then(function(){
console.log("step 4 (next Job)");
return delay(5000);
})
// ...
调用 delay(1000) 创建一个将 在 1000ms 内完成的 promise,然后我们从第一个 then(...) 实现回调中返回该值,这将导致第二个 then(...) 的 promise 等待 2000ms 的承诺。
注意:由于 Promise 在变成已决议状态后,从外部是不可变的,因此现在可以安全地将该值传递给任何一方,因为它不会被意外或恶意修改。对于多方遵守承诺的解决方案而言,更是如此。一方不可能影响另一方遵守 Promise 解决方案的能力。不变性听起来像是一个学术话题,但实际上这是 Promise 设计的最基本、最重要的方面之一,不应随便忽略。
是否使用 Promise
关于 Promise 的一个重要细节是确定某个值是否是真正的 Promise。换句话说,它是否会像Promise一样表现?
我们知道 Promises 是由 new Promise(...) 语法构造的,使用 p instanceof Promise 来判断实例类型。但这还不够。
主要是因为您可以从另一个浏览器窗口(例如iframe)接收Promise值,该窗口具有自己的Promise,与当前窗口或框架中的 Promise 不同,并且该检查将无法识别 Promise 实例。
此外,库或框架可以选择提供其自己的 Promise,而不使用本机 ES6 Promise 实现。实际上,您可能会在完全没有 Promise 的旧版浏览器中,通过库来使用 Promises。
吞咽异常 Swallowing exceptions
Swallowing exceptions: 吞咽异常、抑制异常、隐藏异常等等翻译。
在创建 Promise 或观察其解决过程时,如果发生了 JavaScript 异常错误(例如TypeError或ReferenceError),则会捕获该异常,这将迫使有问题的 Promise 变成被拒绝状态 (rejected)。
例如:
var p = new Promise(function(resolve, reject){
foo.bar(); // `foo` is not defined, so error!
resolve(374); // never gets here :(
});
p.then(
function fulfilled(){
// never gets here :(
},
function rejected(err){
// `err` will be a `TypeError` exception object
// from the `foo.bar()` line.
}
);
但是,如果实现了 Promise,却在观察期间(在then(...)注册的回调中)出现 JS 异常错误,会发生什么? 即使不会丢失,您也可能会发现它们的处理方式令人惊讶。 直到您更深入地研究:
var p = new Promise( function(resolve,reject){
resolve(374);
});
p.then(function fulfilled(message){
foo.bar();
console.log(message); // never reached
},
function rejected(err){
// never reached
}
);
foo.bar() 的异常并没有被吞咽下去。问题出在了我们没有监听的更深层次上。 p.then(...) 调用本身会返回另一个承诺,并且该承诺会因 TypeError 异常而被拒绝。(译注:p.then(...) 中已经吞咽了异常,但是产生的Promise 的默认拒绝处理函数抛出了这个异常)
处理未捕获的异常
还有许多人会说有其他更好的方法。
一个常见的建议是,Promises 应该添加一个 done(...),这实际上将 Promise 链标记为 “done”。 done(...)不会创建及返回 Promise,传递给 done(...) 的回调无法串联起来,也无法向不存在的链式 Promise 报告问题。
同未捕获错误的场景类似,通常会这样处理:done(..) 拒绝处理器 (reject handler) 中的任何异常,会被作为一个全局未捕获的异常被抛出,最基础是抛出到开发者控制台中。
var p = Promise.resolve(374);
p.then(function fulfilled(msg){
// numbers don't have string functions,
// so will throw an error
console.log(msg.toLowerCase());
})
.done(null, function() {
// If an exception is caused here, it will be thrown globally
});
ES8中的 异步/等待 (async/await)
JavaScript ES8 引入了 async/await,这使得 Promises 的相关处理变得更加容易。我们将简要介绍 async/await 功能以及如何利用它们编写异步代码。
如何使用 async/await?
您可以使用 async 函数声明来定义一个异步函数。此类函数返回 AsyncFunction 对象。 AsyncFunction 对象代表执行函数中代码的异步函数。
当异步函数被调用时,它返回一个 Promise。当异步函数返回一个不是 Promise 的值时,会自动创建一个Promise,并解析该函数返回值。当 async 函数抛出异常时,Promise 将使用被抛出的值作为被拒绝。
async 函数可以包含 await 表达式,该表达式会暂停函数的执行,并等待所传递的 Promise 变成已决议的状态,然后恢复异步函数的执行并返回 resolved 的值。
您可以将 JavaScript 中的 Promise 视为 Java Future 或 C# Task 的等效项。
async / await的目的是简化使用promise的行为。
让我们看一下以下示例:
// Just a standard JavaScript function
function getNumber1() {
return Promise.resolve('374');
}
// This function does the same as getNumber1
async function getNumber2() {
return 374;
}
类似地,抛出异常的函数等价于返回已被拒绝的 promise 的函数:
function f1() {
return Promise.reject('Some error');
}
async function f2() {
throw 'Some error';
}
await 关键字只能在 async 函数中使用,并允许您同步等待Promise。如果我们在 async 函数之外使用Promise,则仍然必须使用 then 回调:
async function loadData() {
// `rp` is a request-promise function.
var promise1 = rp('https://api.example.com/endpoint1');
var promise2 = rp('https://api.example.com/endpoint2');
// Currently, both requests are fired, concurrently and
// now we'll have to wait for them to finish
var response1 = await promise1;
var response2 = await promise2;
return response1 + ' ' + response2;
}
// Since, we're not in an `async function` anymore
// we have to use `then`.
loadData().then(() => console.log('Done'));
也可以使用“异步函数表达式”定义异步函数。异步函数表达式与异步函数语句非常相似,语法也几乎相同。异步函数表达式和异步函数语句之间的主要区别在于函数名称,在异步函数表达式中,可以省略该名称,创建匿名函数。异步函数表达式可以用作IIFE(立即调用函数表达式,Immediately Invoked Function Expression),该函数一经定义便立即运行。
看起来像这样:
var loadData = async function() {
// `rp` is a request-promise function.
var promise1 = rp('https://api.example.com/endpoint1');
var promise2 = rp('https://api.example.com/endpoint2');
// Currently, both requests are fired, concurrently and
// now we'll have to wait for them to finish
var response1 = await promise1;
var response2 = await promise2;
return response1 + ' ' + response2;
}
更重要的是,所有主要浏览器都支持async/await:

如果您不追求这种兼容性,那么还有一些 JS 转译器, Babel 和 TypeScript。
归根结底,重要的是不要盲目选择“最新”方法来编写异步代码,而是要了解异步JavaScript的内部结构,了解为什么它如此重要,要深入理解你选择使用的方法的内部结构。在编程过程中,每种方法都有其优点和缺点。
编写高可维护、高可靠性异步代码的 5 个技巧
- 简洁代码:使用
async/await可简化代码,可以帮助你跳过一些不必要的步骤。创建一个匿名函数来处理响应,从该回调中命名响应,例如:
// `rp` is a request-promise function.
rp('https://api.example.com/endpoint1').then(function(data) {
// ...
});
对比代码:
// `rp` is a request-promise function.
var response = await rp('https://api.example.com/endpoint1');
- 错误处理:使用异步/等待的另外一个好处是,可以使用相同的代码结构(众所周知的try / catch语句)来处理同步错误和异步错误。让我们看看这段代码:
function loadData() {
try { // Catches synchronous errors.
getJSON().then(function(response) {
var parsed = JSON.parse(response);
console.log(parsed);
}).catch(function(e) { // Catches asynchronous errors
console.log(e);
});
} catch(e) {
console.log(e);
}
}
改用 async/wait 的方式:
async function loadData() {
try {
var data = JSON.parse(await getJSON());
console.log(data);
} catch(e) {
console.log(e);
}
}
- 条件语句:用
async/await编写条件代码要简单得多。看这段代码:
function loadData() {
return getJSON()
.then(function(response) {
if (response.needsAnotherRequest) {
return makeAnotherRequest(response)
.then(function(anotherResponse) {
console.log(anotherResponse)
return anotherResponse
})
} else {
console.log(response)
return response
}
})
}
对比:
async function loadData() {
var response = await getJSON();
if (response.needsAnotherRequest) {
var anotherResponse = await makeAnotherRequest(response);
console.log(anotherResponse)
return anotherResponse
} else {
console.log(response);
return response;
}
}
- 栈帧:很难确定从 promise 链返回的错误堆栈发生的位置。请看以下内容:
function loadData() {
return callAPromise()
.then(callback1)
.then(callback2)
.then(callback3)
.then(() => {
throw new Error("boom");
})
}
loadData()
.catch(function(e) {
console.log(err);
// Error: boom at callAPromise.then.then.then.then (index.js:8:13)
});
async/await 则不同:
async function loadData() {
await callAPromise1()
await callAPromise2()
await callAPromise3()
await callAPromise4()
await callAPromise5()
throw new Error("boom");
}
loadData()
.catch(function(e) {
console.log(err);
// output
// Error: boom at loadData (index.js:7:9)
});
- 调试:如果您用过 Promise,你就会知道,调试它们是一场噩梦。例如,如果在
.then块内设置断点并使用调试快捷方式(如“ stop-over”),则调试器将不会移至下一个.then,因为它仅逐步通过同步代码。 使用async / await,您可以完全像正常的同步函数一样逐步执行await调用。
Resources
- [https://github.com/getify/You-Dont-Know-JS/blob/master/async%20%26%20performance/ch2.md](https://github.com/getify/You-Dont-Know-JS/blob/master/async %26 performance/ch2.md)
- [https://github.com/getify/You-Dont-Know-JS/blob/master/async%20%26%20performance/ch3.md](https://github.com/getify/You-Dont-Know-JS/blob/master/async %26 performance/ch3.md)
- http://nikgrozev.com/2017/10/01/async-await/