性能问题排查步骤 (CPU)
潘忠显 / 2020-11-03
本文介绍了基本的CPU性能分析工具、问题排查步骤,掺杂少量内存、IO、网络相关内容。
CPU排查过程跟普通思考问题的方法是一致的:
- 哪项指标有异常
- 哪个进程有异常
- 进程高负载的原因
- 进程高负载的影响 (TODO)
《CPU毛刺问题排查》描述了一个按照该步骤排查的典型案例,文章已被腾讯技术工程转载。
哪项指标有异常
| 系统告警 | 业务告警 | 其他 |
|---|---|---|
| Coredump OOM Killer CPU负载过高 内存占用过高 IO过高 FD过多 |
失败率 超时率 请求延迟 |
上线前压测 上线后观察 vmstat sar |
sar
对磁盘、CPU、内存使用情况,软硬中断,系统调用,进程活动等都可以进行有效的分析。
vmstat
展示给定时间间隔的服务器的状态值,包括服务器的CPU使用率、内存使用、虚拟内存交换、IO读写情况。
理解指标的含义
TNM Agent采集项说明
| 采集指标 | 说明 | 采集频率 |
|---|---|---|
| CPU使用率 | CPU处于非空闲状态的百分比 | 60秒 |
| CPU负载 | CPU的1分钟、5分钟、15分钟平均负载*100 | 60秒 |
| 应用程序使用内存数 (单位Mb) | MemTotal - MemFree - (Buffers + Cached - Shmem) 得到内存使用指标 | 240秒 |
| MEM总量(单位Kb) | free命令中Mem:一行total的值 | 240秒 |
| MEM使用量 | free命令中Mem:一行used的值 | 240秒 |
| Private内存占用 | 所有进程的private内存占用总和 | 240秒 |
| Virtual内存占用 | 所有进程的virtual内存占用总和 | 240秒 |
| Private加共享内存占用 | 所有进程的private内存+共享内存的总和 | 240秒 |
| 磁盘IO disk_block_in(单位:block/s) | 平均每秒把数据从磁盘读到内存的数据量,即读数据量 | 60秒 |
| 磁盘IO disk_block_out(单位:block/s) | 平均每秒把数据从内存写到磁盘的数据量,即写数据量 | 60秒 |
| SWAP SI | 平均每秒把数据从磁盘交换区装入内存的数据量 | 60秒 |
| SWAP SO | 平均每秒把数据从内存转储到磁盘交换区的数据量 | 60秒 |
| svctm_time_max | 平均每次设备I/O操作的服务时间*100(取所有分区最大值) | 60秒 |
| await_time_max | 平均每次设备I/O操作的等待时间*100(取所有分区最大值) | 60秒 |
| avgqu_sz_max | 平均I/O队列长度*100(取所有分区最大值) | 60秒 |
| util_max | 平均每秒有百分之几的时间用于IO操作(取所有分区最大值) | 60秒 |
| disk_total_read | 所有磁盘平均每秒完成的读操作次数总和*100 | 60秒 |
| disk_total_write | 所有磁盘平均每秒完成的写操作次数总和*100 | 60秒 |
| 流量 | 网卡的平均每秒出入流量 | 60秒 |
| 包量 | 网卡的平均每秒出入包量 | 60秒 |
| TCP连接数 | 服务器已建立的TCP连接数 | 240秒 |
| UDP接收数据报 | 平均每秒接收的UDP数据报 | 240秒 |
| UDP发送数据报 | 平均每秒发送的UDP数据报 | 240秒 |
问题:Linux 设备块大小如何确认,block/s到kB/s的映射关系?
哪个进程有异常
top
问题:top如何按照不同的指标排序
| SORTING of task window (F 可以动态调整展示的列、选择按照哪列排序) |
|||
|---|---|---|---|
| M(%MEM) | N(PID) | P(%CPU) | T(TIME+) |
问题:top是如何工作的?top的第一帧是如何刷出来的?
问题:如何看懂top
iotop
不是内建的工具,需要额外安装
lsof
可以查看哪些进程正在写某个指定的文件
/var/log
/var/log/messages
可以看OOM killer等相关进程记录
/var/log/cron
可以看crontab的执行情况
last
显示用户最近登录信息,包括重启的情况。因为last命令实际使用的 /var/log/wtmp 中的内容,所以列在这里。
netstat
可以通过观察Send-Q或者Recv-Q是否有堵塞,来判断网络是否有高负载。
netstat -alnp | awk '{if(($1=="tcp"|| $2=="Recv-Q") && $2!= 0 && $3!=0){print $0}}'
coredump信息
问题:为什么得在启动目录去gdb core文件
启动时使用了相对路径,找不到so等文件,所以找不到符号信息。
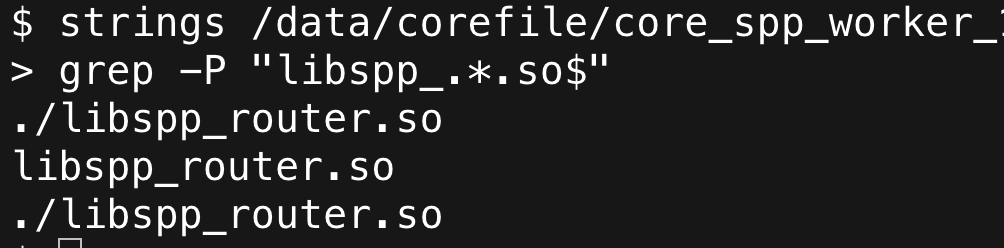
问题:如何从单独的core文件中找到对应的启动目录?
方法1:任意目录使用gdb core文件可以看到启动命令行
gdb /data/corefile/core_spp_worker_1603787664.65337
...
Failed to read a valid object file image from memory.
Core was generated by `./spp_worker ./../etc/spp_worker1.xml'.
Program terminated with signal 6, Aborted.
方法2:使用strings -a core文件grep对应的目录,适用于多个进程启动命令相同的情况
strings -a /data/corefile/core_spp_worker_1603787664.65345 | grep "/bin/" | sort | uniq
/data1/user00/router/bin/.
...
方法3: 有自动拉起的话,可以通过匹配时间来找到对应的进程
问题:core文件是如何产生的?
A core dump is a file that gets automatically generated by the Linux kernel after a program crashes. This file contains the memory, register values, and the call stack of an application at the point of crashing.
是操作系统在进程收到某些信号而终止运行时,将此时进程地址空间的内容以及有关进程状态的其他信息写出的一个磁盘文件。
GDB core dump文件的时候,也会看到"Program terminated with signal 6, Aborted."
信号6就是ABRT(Abort),当进程接收到这些信号的时候就会被操作系统中止。比如下边的指令可以使我们当前登录的bash coredump并退出:
ps | grep bash | awk '{print $1}' | xargs kill -ABRT
了解 /proc
man 5 proc
The proc file system is a pseudo-file system which is used as an interface to kernel data structures. It is commonly mounted at /proc. Most of it is read-only, but some files allow kernel variables to be changed.
伪文件系统,内核数据的接口。大部分文件是只读的,少部分文件对应内核变量可以被修改。
系统相关
| 目录 | 说明 | TNM相关 |
|---|---|---|
| /proc/sys | 内核变量对应的文件和目录 | |
| /proc/cpuinfo | CPU信息 | |
| /proc/loadavg | 1、5、15分钟平均负载 – uptime | 三个平均负载 |
| /proc/diskstats | 每块硬盘的I/O统计 | IO相关数据 |
| /proc/stat | 系统统计信息(从本次启动开始) | |
| /proc/net/dev | 网络设备状态信息 | 统计网卡流量及包量 |
| /proc/net/snmp | IP、ICMP、TCP、UDP管理信息 | TCP连接数、UDP收发包数 |
“kernel variables to be changed”
# 指定生成coredump文件名的位置与格式
/proc/sys/kernel/core_pattern
# 是否使用TCP延迟ACK
/proc/sys/net/ipv4/tcp_no_delay_ack
/proc/[tid] 和 /proc/[pid]/task/[tid] 的有什么区别?
内容一样,可见性不同,ls直接看/proc看不到线程目录,跟直接top只展示进程类似。
Each one of these subdirectories contains files and subdirectories exposing information about the thread with the corresponding thread ID. The contents of these directories are the same as the corresponding
/proc/[pid]/task/[tid]directories.
什么时候用/proc/thread-self 或 /proc/thread-self?
只关注自己进程状态的时候,比如要让总的CPU使用率是正弦曲线使用的是/proc/stats,自己画正弦曲线则要使用/proc/thread-self
/proc/[pid]
文件
/proc/[pid]/cwd : 启动路径
/proc/[pid]/exe : 运行的二进制文件
/proc/uptime : 第一个字段是系统启动以来的秒数
使用strings看下边的文件,因为这些文件中的字符串是通过'\0'做的分割。
/proc/[pid]/environ : 环境变量
/proc/[pid]/cmdline : 启动命令行
目录
/proc/[pid]/fd/ : 打开的文件句柄
/proc/[pid]/net/ : 网络相关统计
/proc/[pid]/stat
$ cat /proc/22049/stat
22049 (spp_proxy) S 1 22049 22049 0 -1 4218944 91154 0 14 0 768322 1258005 0 0 20 0 1 0 11974071498 112250880 13039 18446744073709551615 4194304 4891643 140727656653472 140727656587208 140545180835539 0 0 3231747 2560 18446744071580677180 0 0 17 14 0 0 17 0 0 5940224 5949408 39415808 140727656654802 140727656654837 140727656654837 140727656656876 0
| 字段位置 | 1 | 2 | 3 | 4 | 14 | 15 | 16 | 17 | 22 |
|---|---|---|---|---|---|---|---|---|---|
| 说明 | pid | comm | state | ppid | utime | stime | cutime | cstime | starttime |
stime的描述如下:
Amount of time that this process has been scheduled in kernel mode, measured in clock ticks (divide by
sysconf(_SC_CLK_TCK)).
也就是说,stime是进程被调度到内核模式下使用的tick数,而一个tick的时间长度就是 1 / Hertz 。所以转换成CPU利用率的百分比:
$$ usage = \frac{\Delta stime \times \frac{1}{Hertz} }{\Delta uptime} $$
Docker中sysconf变量不准确
以下信息在Docker中不准确,但是使用/proc/cpuinfo或者/proc/stats准确。
使用sysconf写代码,运行得到的结果是:
// CPU核数
printf("sysconf(_SC_NPROCESSORS_ONLN): %d\n", sysconf(_SC_NPROCESSORS_ONLN));
// Hertz
printf("sysconf(_SC_CLK_TCK): %d\n", sysconf(_SC_CLK_TCK));
sysconf(_SC_NPROCESSORS_ONLN): 24
sysconf(_SC_CLK_TCK): 100
而通过/proc中文件查询结果为:
$ cat /proc/stat| grep -P "^cpu\d\s"| wc -l # CPU核数
2
$ zgrep CONFIG_HZ= /proc/config.gz |awk -F"=" '{print $2}' # Hertz
250
pidstat
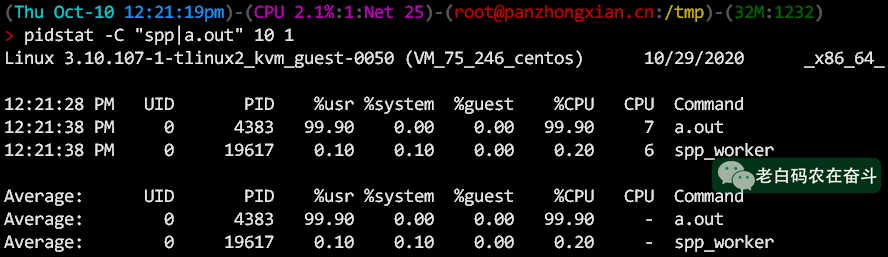
问题:为什么不能直接使用pidstat?
因为如果interval参数不填,统计的是从机器重启的平均负载,而不是进程启动之后的平均。
The interval parameter specifies the amount of time in seconds between each report. A value of 0 (or no parameters at all) indicates that tasks statistics are to be reported for the time since system startup (boot).
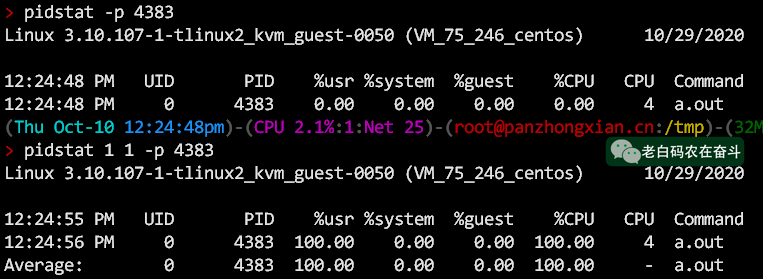
进程高负载的原因
pidstat
查看用户态和内核态占用CPU的比例,也要理解系统调用、内核态、用户态的关系:
strace / ltrace
strace用于统计系统调用情况,是基于ptrace 实现的,ptrace本身也是个系统调用。
The operation of strace is made possible by the kernel feature known as ptrace.
ltrace用于统计统计库,用法跟strace类似。
通常用strace/ltrace -c来做一段时间的统计。
gstack / gcore
gstack是基于gdb查看程序调用栈的脚本,会直接将调用栈打印到屏幕上,pstack是一个到gstack的软链。
gcore也是个基于gdb的脚本,同gstack类似,使用的不同选项,产生更详细的coredump文件。
perf
perf的详细使用和例子可以参考这里。
perf-top
实时采样的滚动展示
perf-stat
可以看上下文切换等进程的统计信息
Performance counter stats for process id '44414':
512.400277 task-clock (msec) # 0.110 CPUs utilized
651 context-switches # 0.001 M/sec
85 cpu-migrations # 0.166 K/sec
4 page-faults # 0.008 K/sec
1,324,257,001 cycles # 2.584 GHz
0 stalled-cycles-frontend # 0.00% frontend cycles idle
0 stalled-cycles-backend # 0.00% backend cycles idle
2,062,488,798 instructions # 1.56 insns per cycle
364,827,676 branches # 711.997 M/sec
2,054,375 branch-misses # 0.56% of all branches
4.662286445 seconds time elapsed
perf-record
perf record 可以生成报告文件perf.data,利用其他一些工具可以展示其中的相关内容:
在进程的启动目录下
sudo perf record -F 99 -p 44414 -g -- sleep 600
perf script > out.perf # 在启动目录才会有完整的符号信息
perf report --stdio
perf-script: 解析perf.data文件,显示调用跟踪的输出。
perf-report: 解析perf.data文件,显示"performance counter profile information"
perf report -n会按照占比展示采样到的函数,类似于perf top展示的一个汇总。
火焰图
比perf report更直观的展示,需要用到perf-script产生的out.perf文件。
cd 到 FlameGraph目录下
仓库地址 https://github.com/brendangregg/FlameGraph
./stackcollapse-perf.pl out.perf > out.folded
./flamegraph.pl out.folded > perf-pandora.svg

问题:为什么毛刺不能适合使用火焰图?
因为毛刺出现的不确定性,perf持续采样很长一段时间才可能覆盖到毛刺时刻,而毛刺持续时间短,占整个火焰图的比例很小,较难找到对应于毛刺的火焰。
火焰图更适合排查持续消耗CPU的负载分析,针对占比大的火焰进行优化。
进程高负载的影响
进程高负载往往会引起处理性能下降、延迟增加、超时等问题。而超时往往是RPC中做后续处理的问题。
带来的负面影响除了能通过业务自身的统计数据进行验证之外,还可以通过网络抓包等方式进行印证。
这里暂且留个TODO,后边在进一步举例说明。